RGB-Sonar Tracking Benchmark and Spatial Cross-Attention Transformer Tracker

0
Sign in to get full access
Overview
- This paper introduces an RGB-Sonar tracking benchmark and a novel Spatial Cross-Attention Transformer Tracker for object tracking in RGB-Sonar data.
- The RGB-Sonar tracking benchmark provides a comprehensive dataset and evaluation protocol for assessing the performance of object tracking algorithms on data that combines visual (RGB) and acoustic (Sonar) information.
- The Spatial Cross-Attention Transformer Tracker leverages a transformer-based architecture with a spatial cross-attention mechanism to effectively fuse the RGB and Sonar data for robust object tracking.
Plain English Explanation
The paper presents a new way to track objects in environments where both visual (RGB) and acoustic (Sonar) information is available. This is useful in underwater scenarios, where traditional camera-based tracking can be challenging due to poor visibility or occlusions.
The researchers first created an RGB-Sonar tracking benchmark, which is a dataset and evaluation protocol that allows researchers to test and compare different object tracking algorithms in these types of environments. This provides a standardized way to measure the performance of tracking methods that can use both visual and acoustic data.
The paper then introduces a novel tracking algorithm called the Spatial Cross-Attention Transformer Tracker. This tracker uses a transformer-based architecture to effectively combine the RGB and Sonar information and track objects. The key innovation is the use of a "spatial cross-attention" mechanism, which helps the tracker focus on the most relevant spatial regions of the RGB and Sonar data when making its predictions.
By leveraging both visual and acoustic information, the Spatial Cross-Attention Transformer Tracker can potentially outperform tracking methods that rely on only one type of sensor, especially in challenging underwater environments where RGB-T object detection or RGB-T saliency detection may struggle.
Technical Explanation
The paper first introduces the RGB-Sonar tracking benchmark, which is a new dataset and evaluation protocol for assessing object tracking performance in environments with both RGB visual data and Sonar acoustic data. The benchmark includes a diverse set of sequences with various challenges, such as occlusions, illumination changes, and fast target motions.
The Spatial Cross-Attention Transformer Tracker is then presented as a novel method for RGB-Sonar object tracking. The tracker uses a transformer-based architecture, which is well-suited for exploiting the complementary information in the RGB and Sonar data. The key component is the Spatial Cross-Attention module, which learns to focus on the most relevant spatial regions in both the RGB and Sonar inputs when making tracking predictions.
The transformer-based architecture consists of a feature extraction backbone, a Spatial Cross-Attention module, and a prediction head. The feature extraction backbone encodes the RGB and Sonar inputs into feature representations, which are then fused using the Spatial Cross-Attention module. This module computes attention weights that highlight the most informative spatial regions in both the RGB and Sonar features, allowing the tracker to effectively combine the two modalities. The fused features are then passed to the prediction head, which outputs the tracked target's bounding box.
The paper evaluates the Spatial Cross-Attention Transformer Tracker on the RGB-Sonar tracking benchmark and compares its performance to various baseline methods. The results demonstrate the effectiveness of the proposed approach, which outperforms other state-of-the-art RGB-T tracking algorithms, especially in challenging underwater scenarios.
Critical Analysis
The paper presents a novel and promising approach for object tracking in RGB-Sonar environments, but there are a few potential areas for improvement or further research:
-
Dataset Diversity: While the RGB-Sonar tracking benchmark is a valuable contribution, the dataset could potentially be expanded to include an even wider range of challenging scenarios, such as more complex underwater scenes or a greater variety of target objects.
-
Computational Efficiency: The transformer-based architecture of the Spatial Cross-Attention Tracker may be computationally intensive, which could limit its real-world applicability, especially in resource-constrained environments. Exploring ways to optimize the model's efficiency could be an area for future work.
-
Generalization Capabilities: The paper focuses on evaluating the tracker's performance on the RGB-Sonar benchmark, but it would be interesting to see how well the model generalizes to other types of multi-modal tracking tasks, such as RGB-D object tracking or RGB-Thermal tracking.
-
Interpretability: While the Spatial Cross-Attention mechanism provides a way to fuse the RGB and Sonar data, a deeper analysis of how the model is making its decisions could help improve the interpretability and transparency of the tracker's behavior.
Overall, the RGB-Sonar tracking benchmark and the Spatial Cross-Attention Transformer Tracker represent valuable contributions to the field of multi-modal object tracking, with the potential to enable more robust and reliable tracking in complex environments.
Conclusion
This paper introduces an RGB-Sonar tracking benchmark and a novel Spatial Cross-Attention Transformer Tracker for object tracking in environments where both visual and acoustic data are available. The benchmark provides a standardized way to evaluate tracking methods in these types of scenarios, while the Spatial Cross-Attention Transformer Tracker leverages a transformer-based architecture with a novel fusion mechanism to effectively combine RGB and Sonar information for robust object tracking.
The results demonstrate the effectiveness of the proposed approach, especially in challenging underwater environments where traditional tracking methods may struggle. While the paper highlights several promising directions for future research, the RGB-Sonar tracking benchmark and the Spatial Cross-Attention Transformer Tracker represent significant advancements in the field of multi-modal object tracking, with the potential to enable more reliable and efficient tracking solutions in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RGB-Sonar Tracking Benchmark and Spatial Cross-Attention Transformer Tracker
Yunfeng Li, Bo Wang, Jiuran Sun, Xueyi Wu, Ye Li
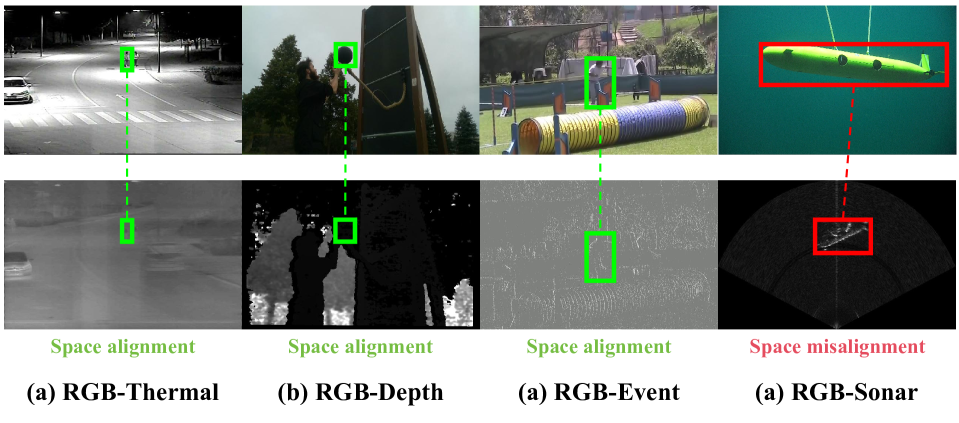
Vision camera and sonar are naturally complementary in the underwater environment. Combining the information from two modalities will promote better observation of underwater targets. However, this problem has not received sufficient attention in previous research. Therefore, this paper introduces a new challenging RGB-Sonar (RGB-S) tracking task and investigates how to achieve efficient tracking of an underwater target through the interaction of RGB and sonar modalities. Specifically, we first propose an RGBS50 benchmark dataset containing 50 sequences and more than 87000 high-quality annotated bounding boxes. Experimental results show that the RGBS50 benchmark poses a challenge to currently popular SOT trackers. Second, we propose an RGB-S tracker called SCANet, which includes a spatial cross-attention module (SCAM) consisting of a novel spatial cross-attention layer and two independent global integration modules. The spatial cross-attention is used to overcome the problem of spatial misalignment of between RGB and sonar images. Third, we propose a SOT data-based RGB-S simulation training method (SRST) to overcome the lack of RGB-S training datasets. It converts RGB images into sonar-like saliency images to construct pseudo-data pairs, enabling the model to learn the semantic structure of RGB-S-like data. Comprehensive experiments show that the proposed spatial cross-attention effectively achieves the interaction between RGB and sonar modalities and SCANet achieves state-of-the-art performance on the proposed benchmark. The code is available at https://github.com/LiYunfengLYF/RGBS50.
Read more6/27/2024
✨
0
Transformer-based RGB-T Tracking with Channel and Spatial Feature Fusion
Yunfeng Li, Bo Wang, Ye Li, Zhiwen Yu, Liang Wang
How to better fuse cross-modal features is the core issue of RGB-T tracking. Some previous methods either insufficiently fuse RGB and TIR features, or depend on intermediaries containing information from both modalities to achieve cross-modal information interaction. The former does not fully exploit the potential of using only RGB and TIR information of the template or search region for channel and spatial feature fusion, and the latter lacks direct interaction between the template and search area, which limits the model's ability to fully exploit the original semantic information of both modalities. To alleviate these limitations, we explore how to improve the performance of a visual Transformer by using direct fusion of cross-modal channels and spatial features, and propose CSTNet. CSTNet uses ViT as a backbone and inserts cross-modal channel feature fusion modules (CFM) and cross-modal spatial feature fusion modules (SFM) for direct interaction between RGB and TIR features. The CFM performs parallel joint channel enhancement and joint multilevel spatial feature modeling of RGB and TIR features and sums the features, and then globally integrates the sum feature with the original features. The SFM uses cross-attention to model the spatial relationship of cross-modal features and then introduces a convolutional feedforward network for joint spatial and channel integration of multimodal features. We retrain the model with CSNet as the pre-training weights in the model with CFM and SFM removed, and propose CSTNet-small, which achieves 36% reduction in parameters and 24% reduction in Flops, and 50% speedup with a 1-2% performance decrease. Comprehensive experiments show that CSTNet achieves state-of-the-art performance on three public RGB-T tracking benchmarks. Code is available at https://github.com/LiYunfengLYF/CSTNet.
Read more7/23/2024
0
RGB-T Object Detection via Group Shuffled Multi-receptive Attention and Multi-modal Supervision
Jinzhong Wang, Xuetao Tian, Shun Dai, Tao Zhuo, Haorui Zeng, Hongjuan Liu, Jiaqi Liu, Xiuwei Zhang, Yanning Zhang
Multispectral object detection, utilizing both visible (RGB) and thermal infrared (T) modals, has garnered significant attention for its robust performance across diverse weather and lighting conditions. However, effectively exploiting the complementarity between RGB-T modals while maintaining efficiency remains a critical challenge. In this paper, a very simple Group Shuffled Multi-receptive Attention (GSMA) module is proposed to extract and combine multi-scale RGB and thermal features. Then, the extracted multi-modal features are directly integrated with a multi-level path aggregation neck, which significantly improves the fusion effect and efficiency. Meanwhile, multi-modal object detection often adopts union annotations for both modals. This kind of supervision is not sufficient and unfair, since objects observed in one modal may not be seen in the other modal. To solve this issue, Multi-modal Supervision (MS) is proposed to sufficiently supervise RGB-T object detection. Comprehensive experiments on two challenging benchmarks, KAIST and DroneVehicle, demonstrate the proposed model achieves the state-of-the-art accuracy while maintaining competitive efficiency.
Read more5/30/2024
🖼️
0
SONIC: Sonar Image Correspondence using Pose Supervised Learning for Imaging Sonars
Samiran Gode, Akshay Hinduja, Michael Kaess
In this paper, we address the challenging problem of data association for underwater SLAM through a novel method for sonar image correspondence using learned features. We introduce SONIC (SONar Image Correspondence), a pose-supervised network designed to yield robust feature correspondence capable of withstanding viewpoint variations. The inherent complexity of the underwater environment stems from the dynamic and frequently limited visibility conditions, restricting vision to a few meters of often featureless expanses. This makes camera-based systems suboptimal in most open water application scenarios. Consequently, multibeam imaging sonars emerge as the preferred choice for perception sensors. However, they too are not without their limitations. While imaging sonars offer superior long-range visibility compared to cameras, their measurements can appear different from varying viewpoints. This inherent variability presents formidable challenges in data association, particularly for feature-based methods. Our method demonstrates significantly better performance in generating correspondences for sonar images which will pave the way for more accurate loop closure constraints and sonar-based place recognition. Code as well as simulated and real-world datasets will be made public to facilitate further development in the field.
Read more5/15/2024