Rho-1: Not All Tokens Are What You Need
2404.07965
1
0

Abstract
Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that Not all tokens in a corpus are equally important for language model training. Our initial analysis delves into token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring pretraining tokens using a reference model, and then training the language model with a focused loss on tokens with higher excess loss. When continual pretraining on 15B OpenWebMath corpus, Rho-1 yields an absolute improvement in few-shot accuracy of up to 30% in 9 math tasks. After fine-tuning, Rho-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively - matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when pretraining on 80B general tokens, Rho-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both efficiency and performance of the language model pre-training.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper "Rho-1: Not All Tokens Are What You Need" explores the concept of selective language modeling, where not all tokens in a text are equally important for training a language model.
- The researchers investigate the training dynamics of token loss, revealing that the contribution of different tokens to the overall loss can vary significantly.
- The paper proposes a novel approach called Rho-1, which selectively focuses on the most important tokens during training, leading to improved model performance and efficiency.
Plain English Explanation
The paper discusses the idea that not all words or "tokens" in a piece of text are equally important when training a language model. Language models are AI systems that can generate human-like text, but training them on all the words in a text can be inefficient. The researchers found that some words contribute more to the overall loss (the measure of how well the model is performing) than others during the training process.
The paper introduces a new approach called Rho-1, which selectively focuses on the most important tokens during training. By doing this, the researchers were able to improve the model's performance and make the training process more efficient. This means the language model can be trained faster and with fewer resources, which could be useful for real-world applications.
The key insight is that not all words are created equal when it comes to training a language model. Some words are more important than others, and by focusing on those critical words, the model can be improved without needing to process every single word in the text.
Technical Explanation
The paper introduces the concept of "selective language modeling," where the training process of a language model focuses on the most important tokens rather than treating all tokens equally. The researchers analyze the training dynamics of token loss, revealing that the contribution of different tokens to the overall loss can vary significantly.
To address this, the paper proposes a novel approach called Rho-1, which selectively focuses on the most important tokens during training. Rho-1 identifies the tokens that contribute the most to the overall loss and prioritizes them during the training process. This selective approach leads to improved model performance and efficiency compared to traditional training methods that treat all tokens equally.
The researchers conduct experiments on various language modeling tasks, including text generation and language understanding, and demonstrate the effectiveness of the Rho-1 approach. They show that Rho-1 can achieve better results than standard training methods while requiring fewer training resources, such as time and computational power.
Critical Analysis
The paper raises some interesting points about the importance of token selection in language model training. The Rho-1 approach seems promising, as it can lead to more efficient and effective training of language models. However, the paper does not address some potential limitations or caveats of the method.
For example, the paper does not discuss how the Rho-1 approach might perform on specialized or domain-specific language tasks, where the importance of certain tokens may differ from more general language modeling. Additionally, the paper does not explore the potential impacts of the Rho-1 approach on the overall robustness and generalization capabilities of the trained language models.
Further research could investigate the long-term effects of selective language modeling on the language models' ability to handle diverse and complex language tasks. It would also be interesting to see how the Rho-1 approach compares to other token selection or weighting techniques, and whether it can be combined with other language model optimization methods for even greater performance gains.
Conclusion
The paper "Rho-1: Not All Tokens Are What You Need" presents a novel approach to language model training that challenges the assumption that all tokens in a text are equally important. By introducing the concept of selective language modeling and the Rho-1 method, the researchers have demonstrated the potential for improving the efficiency and performance of language models.
The key takeaway is that by focusing on the most important tokens during training, language models can be developed more effectively and with fewer resources. This could have significant implications for real-world applications of language AI, where computational efficiency and performance are crucial. As the field of natural language processing continues to evolve, the insights from this paper may inspire further advancements in the way we train and optimize language models.
Related Papers
💬
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi`ere, David Lopez-Paz, Gabriel Synnaeve
0
0
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
5/1/2024
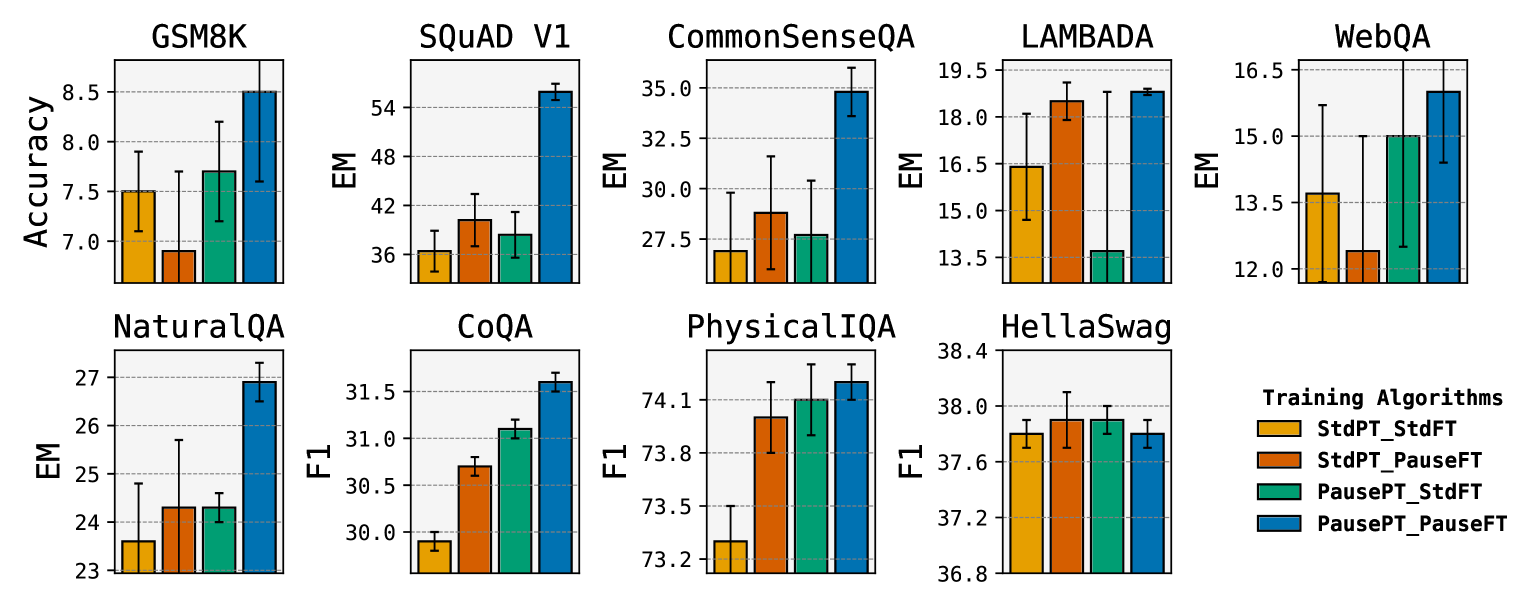
Think before you speak: Training Language Models With Pause Tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, Vaishnavh Nagarajan
0
0
Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18%$ EM score on the QA task of SQuAD, $8%$ on CommonSenseQA and $1%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
4/23/2024
🛠️
Cost-Performance Optimization for Processing Low-Resource Language Tasks Using Commercial LLMs
Arijit Nag, Animesh Mukherjee, Niloy Ganguly, Soumen Chakrabarti
0
0
Large Language Models (LLMs) exhibit impressive zero/few-shot inference and generation quality for high-resource languages (HRLs). A few of them have been trained on low-resource languages (LRLs) and give decent performance. Owing to the prohibitive costs of training LLMs, they are usually used as a network service, with the client charged by the count of input and output tokens. The number of tokens strongly depends on the script and language, as well as the LLM's subword vocabulary. We show that LRLs are at a pricing disadvantage, because the well-known LLMs produce more tokens for LRLs than HRLs. This is because most currently popular LLMs are optimized for HRL vocabularies. Our objective is to level the playing field: reduce the cost of processing LRLs in contemporary LLMs while ensuring that predictive and generative qualities are not compromised. As means to reduce the number of tokens processed by the LLM, we consider code-mixing, translation, and transliteration of LRLs to HRLs. We perform an extensive study using the IndicXTREME classification and six generative tasks dataset, covering 15 Indic and 3 other languages, while using GPT-4 (one of the costliest LLM services released so far) as a commercial LLM. We observe and analyze interesting patterns involving token count, cost, and quality across a multitude of languages and tasks. We show that choosing the best policy to interact with the LLM can reduce cost by 90% while giving better or comparable performance compared to communicating with the LLM in the original LRL.
4/22/2024
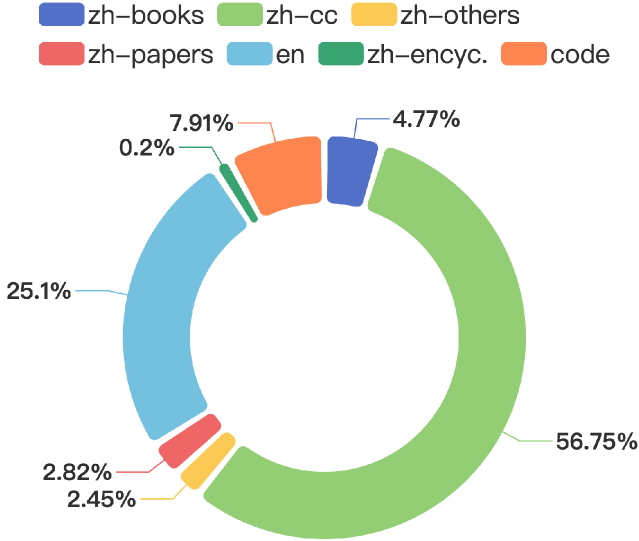
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Binhang Yuan, Wenhu Chen, Jie Fu, Ge Zhang
0
0
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
4/10/2024