Think before you speak: Training Language Models With Pause Tokens
2310.02226
154
0
Abstract
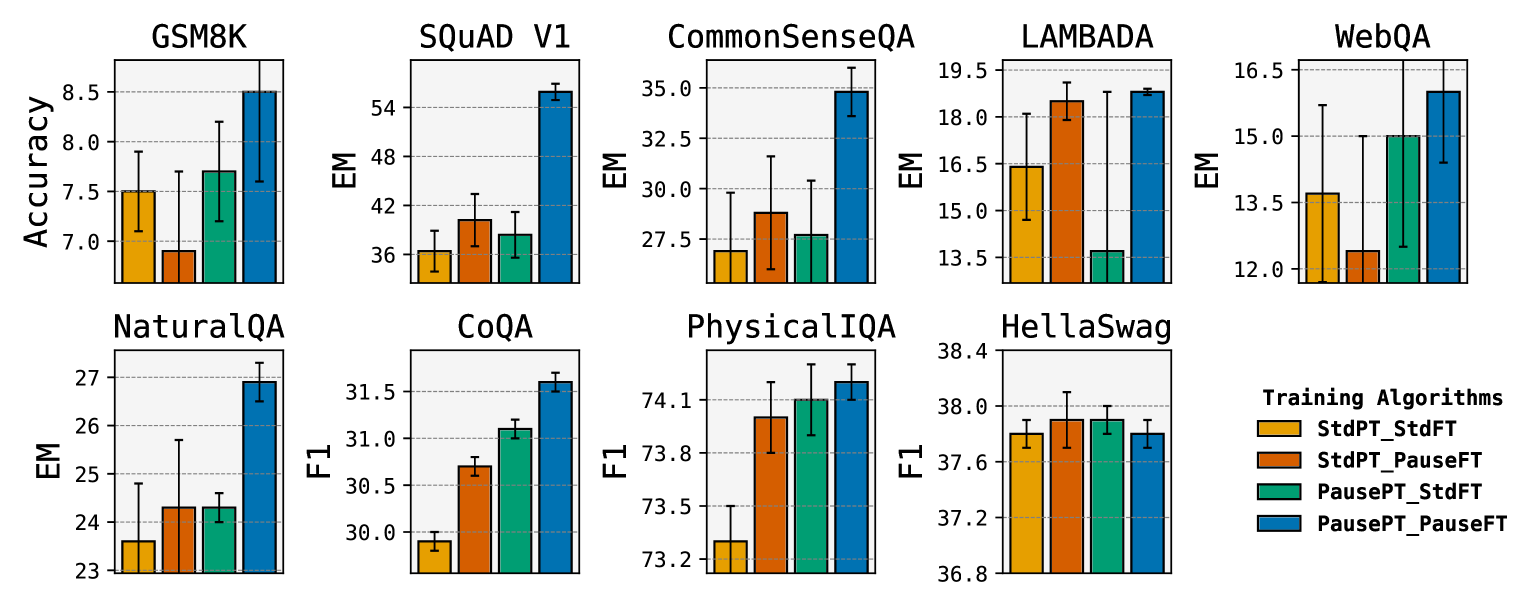
Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18%$ EM score on the QA task of SQuAD, $8%$ on CommonSenseQA and $1%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the idea of training language models with pause tokens, which are used to simulate pauses in human speech.
- The authors hypothesize that including pause tokens during training can help language models generate more natural and coherent text, as humans often pause before speaking.
- The paper presents a "pause-training" approach and evaluates its performance on various language tasks compared to standard language model training.
Plain English Explanation
The researchers in this paper were interested in how language models, which are AI systems that generate human-like text, could be improved by taking into account the way people actually speak. In normal speech, people often pause for a moment before saying the next word or phrase. The researchers wondered if training language models to predict these pauses, in addition to the words themselves, could make the models' outputs sound more natural and human-like.
To test this idea, the researchers developed a "pause-training" approach, where they added special "pause tokens" to the training data that the language model learned from. This allowed the model to not only predict the next word, but also when a pause should occur. [The researchers compare this to how humans leverage both syntactic and acoustic cues when speaking.]
By evaluating the pause-trained models on various language tasks, the researchers found that incorporating pause tokens during training led to improvements in metrics like perplexity and the ability to generate more coherent and natural-sounding text. [The pause-training approach also has potential synergies with techniques like prepacking for improved language model efficiency.]
Overall, this research suggests that explicitly modeling pauses and hesitations, which are a fundamental part of human speech, can help language models better capture the nuances of natural language and communicate in a more human-like way.
Technical Explanation
The authors propose a "pause-training" approach for training language models, where they incorporate pause tokens into the training data alongside the standard word tokens. This allows the model to not only predict the next word, but also when a pause should occur.
The key technical elements of the paper are:
- Pause Token Integration: The authors modify the input and output vocabulary of the language model to include special pause tokens, representing different durations of pauses. This allows the model to predict both words and pauses during generation.
- Pause-Aware Training Objective: The authors introduce a modified training objective that considers both word prediction and pause prediction, encouraging the model to learn the appropriate placement of pauses.
- Evaluation: The authors evaluate the pause-trained models on a range of language tasks, including perplexity, text generation, and coherence. They compare the performance to standard language models trained without pause tokens.
The results show that the pause-training approach leads to improvements in various metrics, indicating that explicitly modeling pauses can help language models generate more natural and coherent text. [The authors also discuss how the pause-training approach could be combined with other techniques, such as rho-1 token prediction or token-level uncertainty modeling, to further enhance the performance of language models.]
Critical Analysis
The paper presents a compelling approach to improving language models by incorporating pause tokens, which aligns with the intuition that human speech is characterized by pauses and hesitations. The authors provide a solid experimental design and thoughtful analysis of the results.
However, the paper does not fully address the potential limitations of the pause-training approach. For example, it is unclear how the model's performance would scale to larger, more complex language modeling tasks, or how the approach would generalize to different domains or languages. Additionally, the paper does not discuss the potential computational overhead or increased training complexity introduced by the pause tokens.
Furthermore, the authors do not explore the potential biases or ethical implications of the pause-training approach. It is possible that the model could learn to associate certain pauses with specific demographic or linguistic characteristics, which could lead to unintended biases in the generated text.
Overall, the research presented in this paper is a step in the right direction for developing more natural and human-like language models. However, further investigation is needed to fully understand the implications and limitations of the pause-training approach.
Conclusion
This paper introduces a novel approach to training language models by incorporating pause tokens into the training process. The results suggest that explicitly modeling pauses can lead to improvements in the coherence and naturalness of the generated text, bringing language models closer to the way humans actually speak.
The pause-training approach represents an important advancement in the field of natural language processing, as it highlights the importance of capturing the nuances of human speech patterns in order to develop more human-like and intuitive language models. [While further research is needed to fully understand the implications and limitations of this approach, this paper lays the groundwork for more realistic and engaging language AI systems.]
Related Papers
💬
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi`ere, David Lopez-Paz, Gabriel Synnaeve
0
0
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
5/1/2024
🎲
Leveraging the Interplay Between Syntactic and Acoustic Cues for Optimizing Korean TTS Pause Formation
Yejin Jeon, Yunsu Kim, Gary Geunbae Lee
0
0
Contemporary neural speech synthesis models have indeed demonstrated remarkable proficiency in synthetic speech generation as they have attained a level of quality comparable to that of human-produced speech. Nevertheless, it is important to note that these achievements have predominantly been verified within the context of high-resource languages such as English. Furthermore, the Tacotron and FastSpeech variants show substantial pausing errors when applied to the Korean language, which affects speech perception and naturalness. In order to address the aforementioned issues, we propose a novel framework that incorporates comprehensive modeling of both syntactic and acoustic cues that are associated with pausing patterns. Remarkably, our framework possesses the capability to consistently generate natural speech even for considerably more extended and intricate out-of-domain (OOD) sentences, despite its training on short audio clips. Architectural design choices are validated through comparisons with baseline models and ablation studies using subjective and objective metrics, thus confirming model performance.
4/4/2024
🤔
Human Latency Conversational Turns for Spoken Avatar Systems
Derek Jacoby, Tianyi Zhang, Aanchan Mohan, Yvonne Coady
0
0
A problem with many current Large Language Model (LLM) driven spoken dialogues is the response time. Some efforts such as Groq address this issue by lightning fast processing of the LLM, but we know from the cognitive psychology literature that in human-to-human dialogue often responses occur prior to the speaker completing their utterance. No amount of delay for LLM processing is acceptable if we wish to maintain human dialogue latencies. In this paper, we discuss methods for understanding an utterance in close to real time and generating a response so that the system can comply with human-level conversational turn delays. This means that the information content of the final part of the speaker's utterance is lost to the LLM. Using the Google NaturalQuestions (NQ) database, our results show GPT-4 can effectively fill in missing context from a dropped word at the end of a question over 60% of the time. We also provide some examples of utterances and the impacts of this information loss on the quality of LLM response in the context of an avatar that is currently under development. These results indicate that a simple classifier could be used to determine whether a question is semantically complete, or requires a filler phrase to allow a response to be generated within human dialogue time constraints.
4/26/2024
Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension
Mengnan Qi, Yufan Huang, Yongqiang Yao, Maoquan Wang, Bin Gu, Neel Sundaresan
0
0
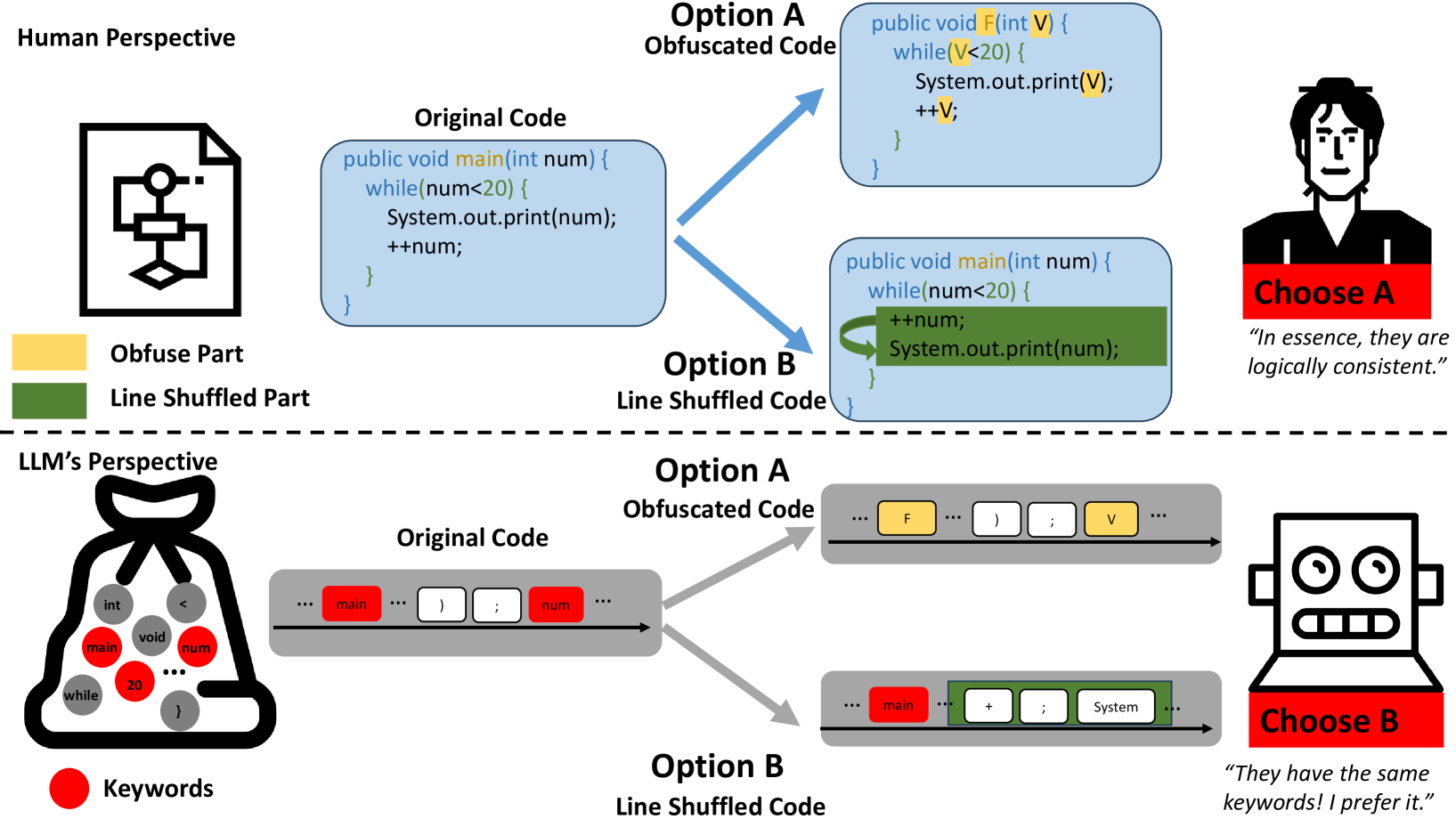
Large language models (LLMs) has experienced exponential growth, they demonstrate remarkable performance across various tasks. Notwithstanding, contemporary research primarily centers on enhancing the size and quality of pretraining data, still utilizing the next token prediction task on autoregressive transformer model structure. The efficacy of this task in truly facilitating the model's comprehension of code logic remains questionable, we speculate that it still interprets code as mere text, while human emphasizes the underlying logical knowledge. In order to prove it, we introduce a new task, Logically Equivalent Code Selection, which necessitates the selection of logically equivalent code from a candidate set, given a query code. Our experimental findings indicate that current LLMs underperform in this task, since they understand code by unordered bag of keywords. To ameliorate their performance, we propose an advanced pretraining task, Next Token Prediction+. This task aims to modify the sentence embedding distribution of the LLM without sacrificing its generative capabilities. Our experimental results reveal that following this pretraining, both Code Llama and StarCoder, the prevalent code domain pretraining models, display significant improvements on our logically equivalent code selection task and the code completion task.
4/16/2024