RI-MAE: Rotation-Invariant Masked AutoEncoders for Self-Supervised Point Cloud Representation Learning

0

Sign in to get full access
Overview
- This paper presents RI-MAE, a self-supervised method for learning representations of point cloud data that is invariant to rotation.
- RI-MAE builds on the Masked Autoencoder (MAE) approach, where a neural network is trained to reconstruct missing parts of the input point cloud.
- The key innovation in RI-MAE is the use of rotation-invariant coding to make the learned representations robust to arbitrary 3D rotations.
Plain English Explanation
RI-MAE is a technique for training AI systems to understand and work with 3D point cloud data, which is a common way of representing 3D shapes and objects. The key idea is to train the AI system to learn representations of the 3D data that are invariant to rotation.
This means the system can recognize and work with 3D objects even if they are rotated or oriented differently. The system does this by masking out parts of the 3D data and then trying to reconstruct the missing parts. By learning to do this reconstruction task, the system develops a robust understanding of the underlying 3D structure that is not dependent on the specific orientation.
This rotation-invariant representation learning could be very useful for a variety of 3D perception and manipulation tasks, like understanding 3D scenes or controlling robotic arms to interact with 3D objects.
Technical Explanation
The RI-MAE method builds on the Masked Autoencoder (MAE) approach, which has shown promising results for self-supervised learning of point cloud representations. In MAE, the neural network is trained to predict the missing parts of a point cloud given a partially masked input.
RI-MAE extends this by incorporating rotation-invariant coding into the MAE framework. Specifically, the RI-MAE encoder first applies a rotation-invariant transformation to the input point cloud, which creates a representation that is robust to arbitrary 3D rotations. This transformed representation is then fed into the standard MAE encoder-decoder architecture to perform the reconstruction task.
The key innovation is the rotation-invariant coding module, which the authors implement using a PointNet-based architecture. This module learns to extract rotation-invariant features from the 3D point cloud data, enabling the overall RI-MAE model to learn representations that generalize across different orientations.
The authors evaluate RI-MAE on several 3D understanding benchmarks, including point cloud classification and shape retrieval. The results demonstrate that RI-MAE outperforms previous self-supervised approaches, particularly on tasks that require rotation-invariant recognition.
Critical Analysis
The RI-MAE paper makes a compelling case for the value of rotation-invariant representation learning for 3D point cloud data. The authors show that explicitly encoding this rotation invariance leads to superior performance on downstream tasks compared to standard MAE approaches.
That said, the paper does not explore the limitations of RI-MAE or provide much insight into the failure modes of the approach. For example, it's unclear how RI-MAE would perform on tasks that do require some notion of orientation, or how it would scale to larger and more complex 3D datasets.
Additionally, the authors do not provide much analysis of the internal workings of the rotation-invariant coding module. A deeper understanding of how this component learns and represents rotation-invariant features could lead to further improvements or inspire related approaches.
Overall, the RI-MAE method represents an interesting and valuable contribution to the field of self-supervised 3D representation learning. However, further research is needed to fully understand its capabilities and limitations.
Conclusion
The RI-MAE paper introduces a novel self-supervised learning approach for point cloud data that is robust to 3D rotations. By incorporating rotation-invariant coding into the Masked Autoencoder framework, RI-MAE is able to learn representations that generalize well across different object orientations.
This rotation-invariance is a key capability for many 3D perception and manipulation tasks, and the results demonstrate the effectiveness of RI-MAE compared to previous self-supervised methods. While the paper leaves some open questions, it represents an important step forward in developing AI systems that can robustly understand and interact with 3D environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RI-MAE: Rotation-Invariant Masked AutoEncoders for Self-Supervised Point Cloud Representation Learning
Kunming Su, Qiuxia Wu, Panpan Cai, Xiaogang Zhu, Xuequan Lu, Zhiyong Wang, Kun Hu
Masked point modeling methods have recently achieved great success in self-supervised learning for point cloud data. However, these methods are sensitive to rotations and often exhibit sharp performance drops when encountering rotational variations. In this paper, we propose a novel Rotation-Invariant Masked AutoEncoders (RI-MAE) to address two major challenges: 1) achieving rotation-invariant latent representations, and 2) facilitating self-supervised reconstruction in a rotation-invariant manner. For the first challenge, we introduce RI-Transformer, which features disentangled geometry content, rotation-invariant relative orientation and position embedding mechanisms for constructing rotation-invariant point cloud latent space. For the second challenge, a novel dual-branch student-teacher architecture is devised. It enables the self-supervised learning via the reconstruction of masked patches within the learned rotation-invariant latent space. Each branch is based on an RI-Transformer, and they are connected with an additional RI-Transformer predictor. The teacher encodes all point patches, while the student solely encodes unmasked ones. Finally, the predictor predicts the latent features of the masked patches using the output latent embeddings from the student, supervised by the outputs from the teacher. Extensive experiments demonstrate that our method is robust to rotations, achieving the state-of-the-art performance on various downstream tasks.
Read more9/4/2024
✨
0
3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining
Siming Yan, Yuqi Yang, Yuxiao Guo, Hao Pan, Peng-shuai Wang, Xin Tong, Yang Liu, Qixing Huang
Masked autoencoders (MAE) have recently been introduced to 3D self-supervised pretraining for point clouds due to their great success in NLP and computer vision. Unlike MAEs used in the image domain, where the pretext task is to restore features at the masked pixels, such as colors, the existing 3D MAE works reconstruct the missing geometry only, i.e, the location of the masked points. In contrast to previous studies, we advocate that point location recovery is inessential and restoring intrinsic point features is much superior. To this end, we propose to ignore point position reconstruction and recover high-order features at masked points including surface normals and surface variations, through a novel attention-based decoder which is independent of the encoder design. We validate the effectiveness of our pretext task and decoder design using different encoder structures for 3D training and demonstrate the advantages of our pretrained networks on various point cloud analysis tasks.
Read more4/30/2024
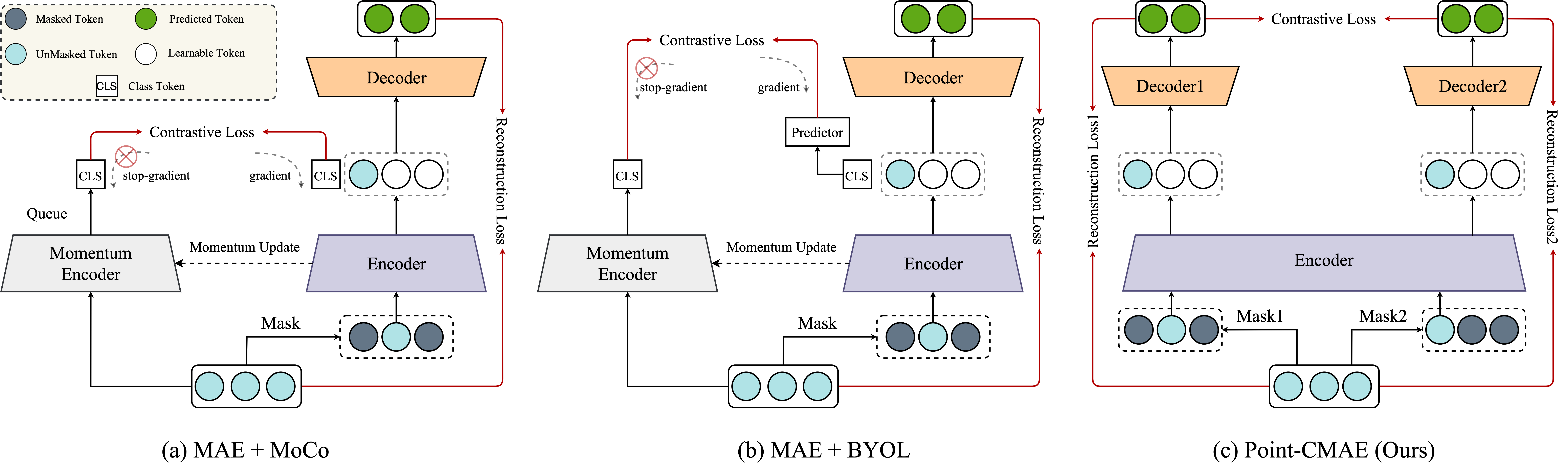
0
Bringing Masked Autoencoders Explicit Contrastive Properties for Point Cloud Self-Supervised Learning
Bin Ren, Guofeng Mei, Danda Pani Paudel, Weijie Wang, Yawei Li, Mengyuan Liu, Rita Cucchiara, Luc Van Gool, Nicu Sebe
Contrastive learning (CL) for Vision Transformers (ViTs) in image domains has achieved performance comparable to CL for traditional convolutional backbones. However, in 3D point cloud pretraining with ViTs, masked autoencoder (MAE) modeling remains dominant. This raises the question: Can we take the best of both worlds? To answer this question, we first empirically validate that integrating MAE-based point cloud pre-training with the standard contrastive learning paradigm, even with meticulous design, can lead to a decrease in performance. To address this limitation, we reintroduce CL into the MAE-based point cloud pre-training paradigm by leveraging the inherent contrastive properties of MAE. Specifically, rather than relying on extensive data augmentation as commonly used in the image domain, we randomly mask the input tokens twice to generate contrastive input pairs. Subsequently, a weight-sharing encoder and two identically structured decoders are utilized to perform masked token reconstruction. Additionally, we propose that for an input token masked by both masks simultaneously, the reconstructed features should be as similar as possible. This naturally establishes an explicit contrastive constraint within the generative MAE-based pre-training paradigm, resulting in our proposed method, Point-CMAE. Consequently, Point-CMAE effectively enhances the representation quality and transfer performance compared to its MAE counterpart. Experimental evaluations across various downstream applications, including classification, part segmentation, and few-shot learning, demonstrate the efficacy of our framework in surpassing state-of-the-art techniques under standard ViTs and single-modal settings. The source code and trained models are available at: https://github.com/Amazingren/Point-CMAE.
Read more7/9/2024

0
T-MAE: Temporal Masked Autoencoders for Point Cloud Representation Learning
Weijie Wei, Fatemeh Karimi Nejadasl, Theo Gevers, Martin R. Oswald
The scarcity of annotated data in LiDAR point cloud understanding hinders effective representation learning. Consequently, scholars have been actively investigating efficacious self-supervised pre-training paradigms. Nevertheless, temporal information, which is inherent in the LiDAR point cloud sequence, is consistently disregarded. To better utilize this property, we propose an effective pre-training strategy, namely Temporal Masked Auto-Encoders (T-MAE), which takes as input temporally adjacent frames and learns temporal dependency. A SiamWCA backbone, containing a Siamese encoder and a windowed cross-attention (WCA) module, is established for the two-frame input. Considering that the movement of an ego-vehicle alters the view of the same instance, temporal modeling also serves as a robust and natural data augmentation, enhancing the comprehension of target objects. SiamWCA is a powerful architecture but heavily relies on annotated data. Our T-MAE pre-training strategy alleviates its demand for annotated data. Comprehensive experiments demonstrate that T-MAE achieves the best performance on both Waymo and ONCE datasets among competitive self-supervised approaches. Codes will be released at https://github.com/codename1995/T-MAE
Read more7/23/2024