Riemannian Bilevel Optimization
2405.15816
0
0
🛠️
Abstract
We develop new algorithms for Riemannian bilevel optimization. We focus in particular on batch and stochastic gradient-based methods, with the explicit goal of avoiding second-order information such as Riemannian hyper-gradients. We propose and analyze $mathrm{RF^2SA}$, a method that leverages first-order gradient information to navigate the complex geometry of Riemannian manifolds efficiently. Notably, $mathrm{RF^2SA}$ is a single-loop algorithm, and thus easier to implement and use. Under various setups, including stochastic optimization, we provide explicit convergence rates for reaching $epsilon$-stationary points. We also address the challenge of optimizing over Riemannian manifolds with constraints by adjusting the multiplier in the Lagrangian, ensuring convergence to the desired solution without requiring access to second-order derivatives.
Create account to get full access
Overview
- The paper introduces new algorithms for Riemannian bilevel optimization, which is a type of optimization problem with a nested structure.
- The focus is on batch and stochastic gradient-based methods that avoid the need for second-order information, such as Riemannian hyper-gradients.
- The researchers propose and analyze a method called RF2SA, which leverages first-order gradient information to efficiently navigate the complex geometry of Riemannian manifolds.
- RF2SA is a single-loop algorithm, making it easier to implement and use compared to other methods.
- The paper also addresses the challenge of optimizing over Riemannian manifolds with constraints by adjusting the multiplier in the Lagrangian.
Plain English Explanation
The paper presents new algorithms for a type of optimization problem called Riemannian bilevel optimization. These problems have a nested structure, where the outer problem depends on the solution of an inner problem.
The researchers focus on developing gradient-based methods that can solve these problems without needing to calculate second-order information, which can be computationally expensive. They propose a new method called RF2SA, which uses only first-order gradient information to efficiently navigate the complex geometry of the Riemannian manifolds involved in these problems.
One key advantage of RF2SA is that it is a single-loop algorithm, meaning it is simpler to implement and use compared to other methods that require multiple loops. The paper also shows how to adapt the algorithm to handle optimization problems with constraints on the Riemannian manifold.
Technical Explanation
The paper introduces new Riemannian bilevel optimization algorithms that avoid the need for second-order information, such as Riemannian hyper-gradients. The researchers propose a method called RF2SA (Riemannian First-order Fully Stochastic Algorithm) that leverages first-order gradient information to efficiently navigate the complex geometry of Riemannian manifolds.
RF2SA is a single-loop algorithm, making it easier to implement and use compared to other methods that require multiple loops. The paper provides explicit convergence rates for RF2SA under various setups, including stochastic optimization.
To address the challenge of optimizing over Riemannian manifolds with constraints, the researchers adjust the multiplier in the Lagrangian, ensuring convergence to the desired solution without requiring access to second-order derivatives.
The paper builds on previous work in the field, such as Accelerated Fully First-Order Methods for Bilevel Minimax Optimization, Finding Small Hypergradients for Bilevel Optimization: Hardness and Study Cases, and Principled Penalty-based Methods for Bilevel Reinforcement Learning.
Critical Analysis
The paper presents a promising approach to Riemannian bilevel optimization by leveraging first-order gradient information and avoiding second-order derivatives. The single-loop nature of the RF2SA algorithm is a notable advantage, as it simplifies implementation and usage compared to other methods.
However, the paper does not address the potential sensitivity of the RF2SA algorithm to the choice of the penalty parameter in the Lagrangian formulation for constrained optimization problems. This parameter can significantly impact the algorithm's performance and convergence, and further investigation into robust techniques for setting it may be warranted.
Additionally, the paper focuses on theoretical convergence rates and does not provide extensive empirical evaluation of the RF2SA algorithm's performance on real-world problems. Validating the practical effectiveness of the method through rigorous experimentation would further strengthen the research.
Lastly, the paper could potentially be strengthened by drawing more explicit connections to related work, such as Optimization Without Retraction on the Random Generalized Stiefel Manifold and Functional Bilevel Optimization in Machine Learning, to situate the contributions within the broader context of Riemannian optimization and bilevel optimization research.
Conclusion
This paper introduces new Riemannian bilevel optimization algorithms that leverage first-order gradient information to efficiently navigate the complex geometry of Riemannian manifolds, without the need for second-order derivatives. The proposed RF2SA method is a single-loop algorithm, making it easier to implement and use compared to other approaches.
The theoretical analysis provided in the paper demonstrates the convergence properties of the RF2SA algorithm under various setups, including stochastic optimization. This work advances the field of Riemannian optimization and has the potential to enable more efficient and scalable solutions for bilevel optimization problems, which arise in many machine learning and decision-making applications.
While the paper presents a promising approach, further research is needed to address potential sensitivity issues with the penalty parameter and to validate the practical effectiveness of the method through extensive empirical evaluation. Continued advancements in this area can lead to significant improvements in the performance and applicability of bilevel optimization techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Accelerated Gradient Method for Convex Smooth Simple Bilevel Optimization
Jincheng Cao, Ruichen Jiang, Erfan Yazdandoost Hamedani, Aryan Mokhtari
0
0
In this paper, we focus on simple bilevel optimization problems, where we minimize a convex smooth objective function over the optimal solution set of another convex smooth constrained optimization problem. We present a novel bilevel optimization method that locally approximates the solution set of the lower-level problem using a cutting plane approach and employs an accelerated gradient-based update to reduce the upper-level objective function over the approximated solution set. We measure the performance of our method in terms of suboptimality and infeasibility errors and provide non-asymptotic convergence guarantees for both error criteria. Specifically, when the feasible set is compact, we show that our method requires at most $mathcal{O}(max{1/sqrt{epsilon_{f}}, 1/epsilon_g})$ iterations to find a solution that is $epsilon_f$-suboptimal and $epsilon_g$-infeasible. Moreover, under the additional assumption that the lower-level objective satisfies the $r$-th Holderian error bound, we show that our method achieves an iteration complexity of $mathcal{O}(max{epsilon_{f}^{-frac{2r-1}{2r}},epsilon_{g}^{-frac{2r-1}{2r}}})$, which matches the optimal complexity of single-level convex constrained optimization when $r=1$.
6/3/2024

Bilevel reinforcement learning via the development of hyper-gradient without lower-level convexity
Yan Yang, Bin Gao, Ya-xiang Yuan
0
0
Bilevel reinforcement learning (RL), which features intertwined two-level problems, has attracted growing interest recently. The inherent non-convexity of the lower-level RL problem is, however, to be an impediment to developing bilevel optimization methods. By employing the fixed point equation associated with the regularized RL, we characterize the hyper-gradient via fully first-order information, thus circumventing the assumption of lower-level convexity. This, remarkably, distinguishes our development of hyper-gradient from the general AID-based bilevel frameworks since we take advantage of the specific structure of RL problems. Moreover, we propose both model-based and model-free bilevel reinforcement learning algorithms, facilitated by access to the fully first-order hyper-gradient. Both algorithms are provable to enjoy the convergence rate $mathcal{O}(epsilon^{-1})$. To the best of our knowledge, this is the first time that AID-based bilevel RL gets rid of additional assumptions on the lower-level problem. In addition, numerical experiments demonstrate that the hyper-gradient indeed serves as an integration of exploitation and exploration.
5/31/2024
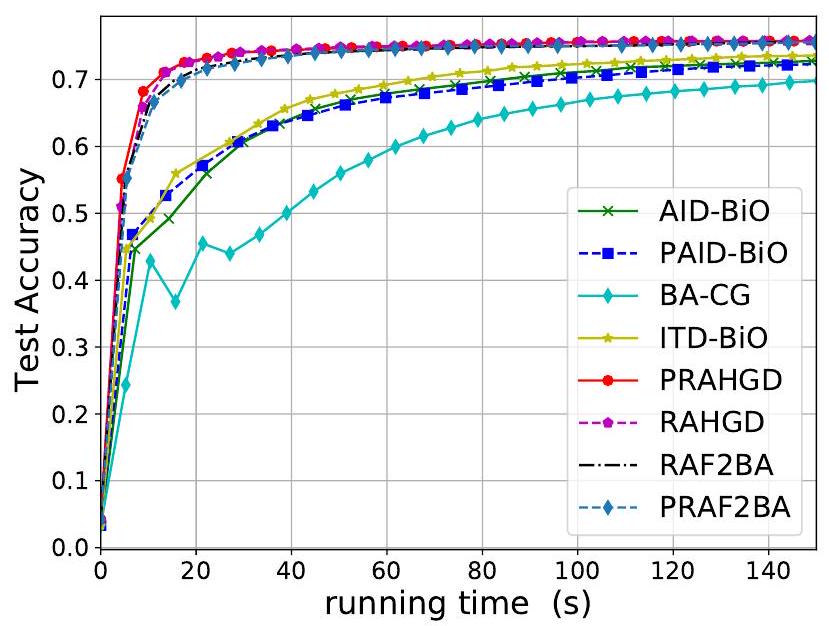
Accelerated Fully First-Order Methods for Bilevel and Minimax Optimization
Chris Junchi Li
0
0
This paper presents a new algorithm member for accelerating first-order methods for bilevel optimization, namely the emph{(Perturbed) Restarted Accelerated Fully First-order methods for Bilevel Approximation}, abbreviated as texttt{(P)RAF${}^2$BA}. The algorithm leverages emph{fully} first-order oracles and seeks approximate stationary points in nonconvex-strongly-convex bilevel optimization, enhancing oracle complexity for efficient optimization. Theoretical guarantees for finding approximate first-order stationary points and second-order stationary points at the state-of-the-art query complexities are established, showcasing their effectiveness in solving complex optimization tasks. Empirical studies for real-world problems are provided to further validate the outperformance of our proposed algorithms. The significance of texttt{(P)RAF${}^2$BA} in optimizing nonconvex-strongly-convex bilevel optimization problems is underscored by its state-of-the-art convergence rates and computational efficiency.
5/7/2024
🛠️
Learning-Rate-Free Stochastic Optimization over Riemannian Manifolds
Daniel Dodd, Louis Sharrock, Christopher Nemeth
0
0
In recent years, interest in gradient-based optimization over Riemannian manifolds has surged. However, a significant challenge lies in the reliance on hyperparameters, especially the learning rate, which requires meticulous tuning by practitioners to ensure convergence at a suitable rate. In this work, we introduce innovative learning-rate-free algorithms for stochastic optimization over Riemannian manifolds, eliminating the need for hand-tuning and providing a more robust and user-friendly approach. We establish high probability convergence guarantees that are optimal, up to logarithmic factors, compared to the best-known optimally tuned rate in the deterministic setting. Our approach is validated through numerical experiments, demonstrating competitive performance against learning-rate-dependent algorithms.
6/5/2024