MARIS: Referring Image Segmentation via Mutual-Aware Attention Features

0

Sign in to get full access
Overview
- The paper presents a new approach called MARIS (Mutual-Aware Attention Features for Referring Image Segmentation) for the task of referring image segmentation.
- Referring image segmentation involves identifying the specific object in an image that corresponds to a given textual description or reference.
- MARIS leverages a mutual-aware attention mechanism to better align the visual and textual features, leading to improved performance on referring image segmentation tasks.
Plain English Explanation
The paper introduces a new method called MARIS (Mutual-Aware Attention Features for Referring Image Segmentation) that helps computers understand which part of an image matches a given textual description. This is a challenging task called referring image segmentation, where the goal is to identify the specific object in an image that corresponds to a textual reference, such as "the dog in the park."
MARIS uses a special attention mechanism to better connect the visual information in the image with the textual information in the description. This helps the computer "see" the connection between what is shown in the image and what is described in the text, leading to more accurate identification of the referred object. By improving this alignment between the visual and textual features, MARIS can outperform previous methods on referring image segmentation tasks.
Technical Explanation
The key innovation in MARIS is the use of a mutual-aware attention mechanism to better align the visual and textual features for referring image segmentation. Previous methods have struggled to effectively connect the information in the image with the information in the textual description. MARIS addresses this by using a specialized attention module that allows the visual and textual features to inform and enhance each other.
Specifically, MARIS takes the visual features extracted from the image and the textual features extracted from the referring expression, and passes them through a series of attention layers. These attention layers allow the visual features to attend to the relevant parts of the textual features, and vice versa. This mutual awareness of the important visual and textual cues helps the model better understand which parts of the image correspond to the given referring expression.
The authors evaluate MARIS on several benchmark datasets for referring image segmentation, and show that it outperforms previous state-of-the-art methods by a significant margin. MARIS demonstrates the power of using a mutual-aware attention mechanism to bridge the gap between the visual and textual domains, leading to more accurate identification of the referred objects in images.
Critical Analysis
The paper presents a well-designed and effective approach to the challenging task of referring image segmentation. The mutual-aware attention mechanism is a clever innovation that addresses a key limitation of prior methods. By allowing the visual and textual features to inform and enhance each other, MARIS is able to better align the two modalities and achieve superior performance.
However, the paper does not discuss any potential limitations or drawbacks of the MARIS approach. For example, the computational complexity of the mutual-aware attention module is not analyzed, nor is the impact on inference time. Additionally, the paper does not explore the generalization capabilities of MARIS – it is unclear how well the method would perform on more diverse or challenging datasets beyond the evaluated benchmarks.
Further research could investigate these areas, as well as explore ways to make the MARIS approach more efficient or applicable to a wider range of referring image segmentation scenarios. Nonetheless, the core idea of mutual-aware attention is a valuable contribution that advances the state of the art in this important computer vision task.
Conclusion
The MARIS paper presents a novel approach to referring image segmentation that leverages a mutual-aware attention mechanism to better align visual and textual features. By allowing the image and text information to inform and enhance each other, MARIS achieves state-of-the-art performance on standard benchmarks.
This work highlights the power of cross-modal interaction and feature fusion for bridging the gap between visual and linguistic data. The mutual-aware attention module developed in this research could have broader applications beyond just referring image segmentation, potentially benefiting other tasks that require understanding the relationship between images and text.
Overall, the MARIS paper makes a significant contribution to the field of computer vision and language understanding, demonstrating the potential for more sophisticated attention-based techniques to advance the state of the art in challenging multimodal tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MARIS: Referring Image Segmentation via Mutual-Aware Attention Features
Mengxi Zhang, Yiming Liu, Xiangjun Yin, Huanjing Yue, Jingyu Yang
Referring image segmentation (RIS) aims to segment a particular region based on a language expression prompt. Existing methods incorporate linguistic features into visual features and obtain multi-modal features for mask decoding. However, these methods may segment the visually salient entity instead of the correct referring region, as the multi-modal features are dominated by the abundant visual context. In this paper, we propose MARIS, a referring image segmentation method that leverages the Segment Anything Model (SAM) and introduces a mutual-aware attention mechanism to enhance the cross-modal fusion via two parallel branches. Specifically, our mutual-aware attention mechanism consists of Vision-Guided Attention and Language-Guided Attention, which bidirectionally model the relationship between visual and linguistic features. Correspondingly, we design a Mask Decoder to enable explicit linguistic guidance for more consistent segmentation with the language expression. To this end, a multi-modal query token is proposed to integrate linguistic information and interact with visual information simultaneously. Extensive experiments on three benchmark datasets show that our method outperforms the state-of-the-art RIS methods. Our code will be publicly available.
Read more5/22/2024

0
HARIS: Human-Like Attention for Reference Image Segmentation
Mengxi Zhang, Heqing Lian, Yiming Liu, Jie Chen
Referring image segmentation (RIS) aims to locate the particular region corresponding to the language expression. Existing methods incorporate features from different modalities in a emph{bottom-up} manner. This design may get some unnecessary image-text pairs, which leads to an inaccurate segmentation mask. In this paper, we propose a referring image segmentation method called HARIS, which introduces the Human-Like Attention mechanism and uses the parameter-efficient fine-tuning (PEFT) framework. To be specific, the Human-Like Attention gets a emph{feedback} signal from multi-modal features, which makes the network center on the specific objects and discard the irrelevant image-text pairs. Besides, we introduce the PEFT framework to preserve the zero-shot ability of pre-trained encoders. Extensive experiments on three widely used RIS benchmarks and the PhraseCut dataset demonstrate that our method achieves state-of-the-art performance and great zero-shot ability.
Read more5/22/2024

0
Extending CLIP's Image-Text Alignment to Referring Image Segmentation
Seoyeon Kim, Minguk Kang, Dongwon Kim, Jaesik Park, Suha Kwak
Referring Image Segmentation (RIS) is a cross-modal task that aims to segment an instance described by a natural language expression. Recent methods leverage large-scale pretrained unimodal models as backbones along with fusion techniques for joint reasoning across modalities. However, the inherent cross-modal nature of RIS raises questions about the effectiveness of unimodal backbones. We propose RISCLIP, a novel framework that effectively leverages the cross-modal nature of CLIP for RIS. Observing CLIP's inherent alignment between image and text features, we capitalize on this starting point and introduce simple but strong modules that enhance unimodal feature extraction and leverage rich alignment knowledge in CLIP's image-text shared-embedding space. RISCLIP exhibits outstanding results on all three major RIS benchmarks and also outperforms previous CLIP-based methods, demonstrating the efficacy of our strategy in extending CLIP's image-text alignment to RIS.
Read more4/9/2024
0
Improving Referring Image Segmentation using Vision-Aware Text Features
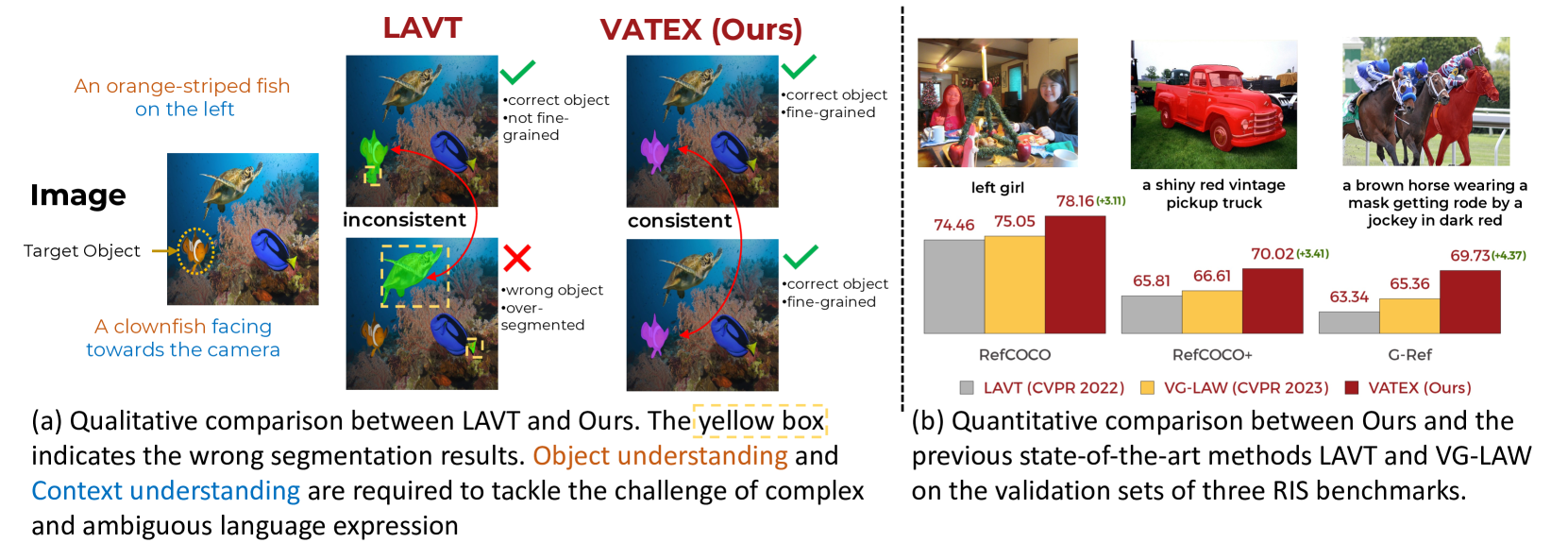
Hai Nguyen-Truong, E-Ro Nguyen, Tuan-Anh Vu, Minh-Triet Tran, Binh-Son Hua, Sai-Kit Yeung
Referring image segmentation is a challenging task that involves generating pixel-wise segmentation masks based on natural language descriptions. Existing methods have relied mostly on visual features to generate the segmentation masks while treating text features as supporting components. This over-reliance on visual features can lead to suboptimal results, especially in complex scenarios where text prompts are ambiguous or context-dependent. To overcome these challenges, we present a novel framework VATEX to improve referring image segmentation by enhancing object and context understanding with Vision-Aware Text Feature. Our method involves using CLIP to derive a CLIP Prior that integrates an object-centric visual heatmap with text description, which can be used as the initial query in DETR-based architecture for the segmentation task. Furthermore, by observing that there are multiple ways to describe an instance in an image, we enforce feature similarity between text variations referring to the same visual input by two components: a novel Contextual Multimodal Decoder that turns text embeddings into vision-aware text features, and a Meaning Consistency Constraint to ensure further the coherent and consistent interpretation of language expressions with the context understanding obtained from the image. Our method achieves a significant performance improvement on three benchmark datasets RefCOCO, RefCOCO+ and G-Ref. Code is available at: https://nero1342.github.io/VATEX_RIS.
Read more4/15/2024