Extending CLIP's Image-Text Alignment to Referring Image Segmentation

0

Sign in to get full access
Overview
• This paper presents RISCLIP, a framework for referring image segmentation that leverages the CLIP (Contrastive Language-Image Pre-training) model.
• Referring image segmentation is the task of segmenting an object in an image based on a textual description or "referring expression".
• RISCLIP uses CLIP to bridge the gap between the textual referring expression and the visual image, enabling accurate and efficient object segmentation.
Plain English Explanation
RISCLIP is a system that allows you to describe an object in an image using words, and then the computer will automatically highlight or "segment" that specific object for you. This is a useful tool for a variety of applications, such as identifying specific items in product images or analyzing remote sensing data.
The key innovation of RISCLIP is that it uses a powerful AI model called CLIP, which has been trained on a huge amount of text and image data. CLIP can understand the relationship between words and visual concepts, allowing it to match the textual description you provide with the corresponding object in the image. This helps RISCLIP accurately segment the object you're referring to, even if it's a complex or unusual object.
RISCLIP builds on this CLIP foundation to create a complete system for referring image segmentation. It takes your textual description, analyzes the image, and then highlights the specific object you're talking about. This makes it much easier to work with images, especially when you need to focus on a particular element or component.
Technical Explanation
RISCLIP uses the CLIP (Contrastive Language-Image Pre-training) model as its foundation. CLIP is a pre-trained AI model that has learned to understand the relationships between text and visual concepts by analyzing a large dataset of image-text pairs. This allows CLIP to bridge the gap between textual descriptions and visual content, which is crucial for the referring image segmentation task.
The RISCLIP framework consists of several key components:
-
CLIP Encoder: RISCLIP uses the CLIP model to encode both the textual referring expression and the input image into a shared latent representation.
-
Referring Segmentation Head: RISCLIP then uses a specialized neural network module to take the encoded text and image features and predict a segmentation mask for the object being referred to.
-
Training and Inference: RISCLIP is trained on a dataset of images with corresponding textual referring expressions and segmentation masks. During inference, the user provides a new image and referring expression, and RISCLIP outputs the segmentation mask for the described object.
The key innovation of RISCLIP is its ability to leverage the powerful cross-modal understanding of CLIP to enable efficient and accurate referring image segmentation. This contrasts with previous approaches that relied on more complex architectures or required extensive fine-tuning on domain-specific data. RISCLIP's approach can be seen as an extension of techniques like MedCLIP, which also use CLIP to bridge text and image understanding.
Critical Analysis
The RISCLIP paper presents a compelling and well-executed approach to referring image segmentation. The authors demonstrate strong results on benchmark datasets, showing that RISCLIP outperforms previous state-of-the-art methods.
However, the paper does not address some potential limitations or areas for further research. For example, it would be interesting to see how RISCLIP performs on more complex scenes with multiple, overlapping objects, or how it handles ambiguous or abstract referring expressions. Additional research could also explore ways to further improve the efficiency and generalization of the model, similar to techniques like LOSH.
Additionally, the paper does not discuss potential ethical considerations or societal implications of this technology. As with any powerful AI system, there may be concerns around bias, privacy, or potential misuse that should be carefully considered.
Overall, RISCLIP represents an important step forward in referring image segmentation, but there remains room for further refinement and exploration of the broader implications of this work.
Conclusion
RISCLIP presents a novel framework for referring image segmentation that leverages the powerful cross-modal understanding of the CLIP model. By bridging the gap between textual descriptions and visual content, RISCLIP enables accurate and efficient object segmentation based on natural language input.
This technology has a wide range of potential applications, from improving medical image analysis to enhancing video highlight detection. As AI systems become increasingly adept at understanding and manipulating visual and textual data, RISCLIP-like approaches could revolutionize the way we interact with and extract insights from digital content.
Overall, the RISCLIP paper showcases the potential of leveraging advanced language models like CLIP to tackle complex computer vision tasks. As the field of AI continues to evolve, we can expect to see more innovative solutions that bridge the gap between text and images, unlocking new possibilities for how we perceive, analyze, and interact with the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Extending CLIP's Image-Text Alignment to Referring Image Segmentation
Seoyeon Kim, Minguk Kang, Dongwon Kim, Jaesik Park, Suha Kwak
Referring Image Segmentation (RIS) is a cross-modal task that aims to segment an instance described by a natural language expression. Recent methods leverage large-scale pretrained unimodal models as backbones along with fusion techniques for joint reasoning across modalities. However, the inherent cross-modal nature of RIS raises questions about the effectiveness of unimodal backbones. We propose RISCLIP, a novel framework that effectively leverages the cross-modal nature of CLIP for RIS. Observing CLIP's inherent alignment between image and text features, we capitalize on this starting point and introduce simple but strong modules that enhance unimodal feature extraction and leverage rich alignment knowledge in CLIP's image-text shared-embedding space. RISCLIP exhibits outstanding results on all three major RIS benchmarks and also outperforms previous CLIP-based methods, demonstrating the efficacy of our strategy in extending CLIP's image-text alignment to RIS.
Read more4/9/2024

0
MARIS: Referring Image Segmentation via Mutual-Aware Attention Features
Mengxi Zhang, Yiming Liu, Xiangjun Yin, Huanjing Yue, Jingyu Yang
Referring image segmentation (RIS) aims to segment a particular region based on a language expression prompt. Existing methods incorporate linguistic features into visual features and obtain multi-modal features for mask decoding. However, these methods may segment the visually salient entity instead of the correct referring region, as the multi-modal features are dominated by the abundant visual context. In this paper, we propose MARIS, a referring image segmentation method that leverages the Segment Anything Model (SAM) and introduces a mutual-aware attention mechanism to enhance the cross-modal fusion via two parallel branches. Specifically, our mutual-aware attention mechanism consists of Vision-Guided Attention and Language-Guided Attention, which bidirectionally model the relationship between visual and linguistic features. Correspondingly, we design a Mask Decoder to enable explicit linguistic guidance for more consistent segmentation with the language expression. To this end, a multi-modal query token is proposed to integrate linguistic information and interact with visual information simultaneously. Extensive experiments on three benchmark datasets show that our method outperforms the state-of-the-art RIS methods. Our code will be publicly available.
Read more5/22/2024

0
HARIS: Human-Like Attention for Reference Image Segmentation
Mengxi Zhang, Heqing Lian, Yiming Liu, Jie Chen
Referring image segmentation (RIS) aims to locate the particular region corresponding to the language expression. Existing methods incorporate features from different modalities in a emph{bottom-up} manner. This design may get some unnecessary image-text pairs, which leads to an inaccurate segmentation mask. In this paper, we propose a referring image segmentation method called HARIS, which introduces the Human-Like Attention mechanism and uses the parameter-efficient fine-tuning (PEFT) framework. To be specific, the Human-Like Attention gets a emph{feedback} signal from multi-modal features, which makes the network center on the specific objects and discard the irrelevant image-text pairs. Besides, we introduce the PEFT framework to preserve the zero-shot ability of pre-trained encoders. Extensive experiments on three widely used RIS benchmarks and the PhraseCut dataset demonstrate that our method achieves state-of-the-art performance and great zero-shot ability.
Read more5/22/2024
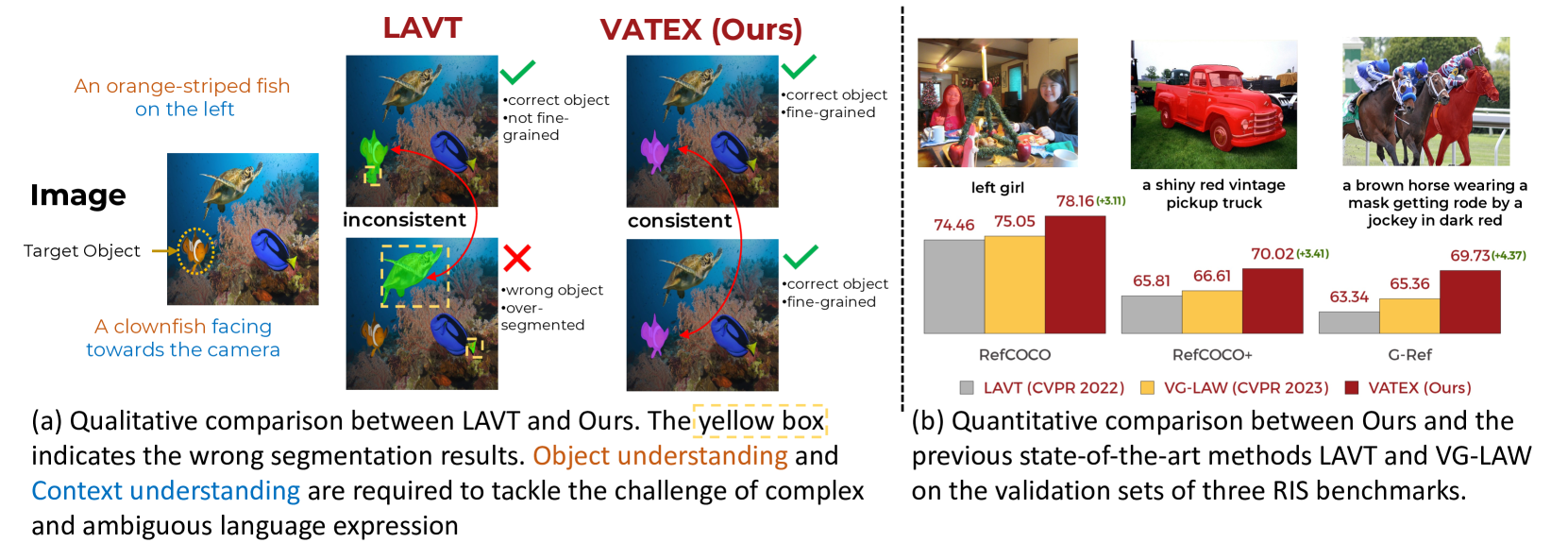
0
Improving Referring Image Segmentation using Vision-Aware Text Features
Hai Nguyen-Truong, E-Ro Nguyen, Tuan-Anh Vu, Minh-Triet Tran, Binh-Son Hua, Sai-Kit Yeung
Referring image segmentation is a challenging task that involves generating pixel-wise segmentation masks based on natural language descriptions. Existing methods have relied mostly on visual features to generate the segmentation masks while treating text features as supporting components. This over-reliance on visual features can lead to suboptimal results, especially in complex scenarios where text prompts are ambiguous or context-dependent. To overcome these challenges, we present a novel framework VATEX to improve referring image segmentation by enhancing object and context understanding with Vision-Aware Text Feature. Our method involves using CLIP to derive a CLIP Prior that integrates an object-centric visual heatmap with text description, which can be used as the initial query in DETR-based architecture for the segmentation task. Furthermore, by observing that there are multiple ways to describe an instance in an image, we enforce feature similarity between text variations referring to the same visual input by two components: a novel Contextual Multimodal Decoder that turns text embeddings into vision-aware text features, and a Meaning Consistency Constraint to ensure further the coherent and consistent interpretation of language expressions with the context understanding obtained from the image. Our method achieves a significant performance improvement on three benchmark datasets RefCOCO, RefCOCO+ and G-Ref. Code is available at: https://nero1342.github.io/VATEX_RIS.
Read more4/15/2024