Near-Optimal Learning and Planning in Separated Latent MDPs
2406.07920
0
0
🤿
Abstract
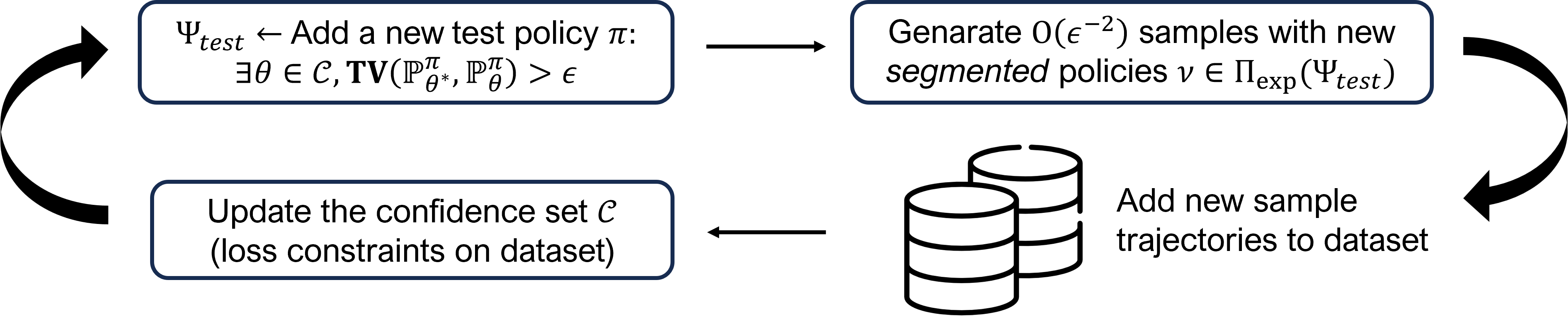
We study computational and statistical aspects of learning Latent Markov Decision Processes (LMDPs). In this model, the learner interacts with an MDP drawn at the beginning of each epoch from an unknown mixture of MDPs. To sidestep known impossibility results, we consider several notions of separation of the constituent MDPs. The main thrust of this paper is in establishing a nearly-sharp
Create account to get full access
Overview
- This paper explores the computational and statistical aspects of learning Latent Markov Decision Processes (LMDPs).
- In LMDPs, the learner interacts with a Markov Decision Process (MDP) drawn at the beginning of each epoch from an unknown mixture of MDPs.
- To bypass known impossibility results, the authors consider different notions of separation between the constituent MDPs.
- The primary focus of the paper is on establishing a nearly-sharp statistical threshold for the horizon length required for efficient learning.
- On the computational side, the authors show that under a weaker assumption of separability under the optimal policy, there is a quasi-polynomial algorithm with time complexity scaling in terms of the statistical threshold.
- They also present a near-matching time complexity lower bound under the exponential time hypothesis.
Plain English Explanation
In this research, the authors are studying a particular type of reinforcement learning problem called Latent Markov Decision Processes (LMDPs). In an LMDP, the learner interacts with a Markov Decision Process (MDP) that is randomly selected from an unknown set of MDPs at the beginning of each "epoch" or time period.
To make this problem tractable, the researchers consider different ways of ensuring that the MDPs in the set are sufficiently different from each other. They then focus on determining the minimum length of time (the "horizon length") that the learner needs to interact with the environment in order to efficiently learn the underlying LMDP.
On the computational side, the researchers show that under a slightly weaker assumption about the separability of the MDPs, there is an algorithm that can solve the problem in a reasonable amount of time, with the runtime scaling with the statistical threshold they identified. They also prove that this is about as fast as any algorithm can be, assuming a common complexity theory assumption.
The key insights here are about understanding the inherent difficulty of the LMDP learning problem and developing algorithms that can provably solve it efficiently, which could have important implications for real-world reinforcement learning applications with complex, uncertain environments.
Technical Explanation
The paper focuses on the computational and statistical aspects of learning Latent Markov Decision Processes (LMDPs). In an LMDP, the learner interacts with an MDP that is randomly drawn from an unknown mixture of MDPs at the beginning of each "epoch" or time period.
To bypass known impossibility results for this problem, the authors consider several notions of "separation" between the constituent MDPs in the mixture. The main technical contribution is in establishing a nearly-sharp
On the computational side, the authors show that under a weaker assumption of separability under the optimal policy, there exists a quasi-polynomial algorithm with time complexity scaling in terms of the statistical threshold. They also prove a near-matching time complexity lower bound under the Exponential Time Hypothesis, demonstrating the tightness of their algorithmic result.
These findings build on prior work in offline, oracle-efficient learning of Contextual MDPs and primal-dual algorithms for offline constrained reinforcement learning, as well as theoretical results on the inherent difficulty of exploration versus prediction in reinforcement learning.
Critical Analysis
The key strengths of this research are the rigorous theoretical analysis and the tight characterization of the computational and statistical thresholds for learning LMDPs. By considering different notions of separability between the constituent MDPs, the authors are able to sidestep known impossibility results and develop provably efficient algorithms.
That said, the assumptions required for the positive results, such as the weaker separability condition under the optimal policy, may limit the practical applicability of the methods. Additionally, the paper does not explore the performance of the algorithms in real-world settings or provide empirical validation of the theoretical findings.
It would also be interesting to see the authors extend their analysis to the infinite-horizon average reward setting, which is arguably more relevant for many real-world applications.
Overall, this work represents a significant theoretical advance in the understanding of learning in complex, uncertain environments. However, further research is needed to bridge the gap between the theoretical results and practical implementation.
Conclusion
This paper presents a rigorous study of the computational and statistical aspects of learning Latent Markov Decision Processes (LMDPs), a challenging reinforcement learning problem with uncertain environments. The authors establish nearly-sharp thresholds for the horizon length required for efficient learning and develop quasi-polynomial algorithms with provable guarantees.
These theoretical insights could have important implications for reinforcement learning in real-world applications with complex, changing environments, such as robotics, healthcare, or finance. However, further work is needed to translate these findings into practical solutions and to explore the performance of the algorithms in realistic settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
RL in Latent MDPs is Tractable: Online Guarantees via Off-Policy Evaluation
Jeongyeol Kwon, Shie Mannor, Constantine Caramanis, Yonathan Efroni
0
0
In many real-world decision problems there is partially observed, hidden or latent information that remains fixed throughout an interaction. Such decision problems can be modeled as Latent Markov Decision Processes (LMDPs), where a latent variable is selected at the beginning of an interaction and is not disclosed to the agent. In the last decade, there has been significant progress in solving LMDPs under different structural assumptions. However, for general LMDPs, there is no known learning algorithm that provably matches the existing lower bound (Kwon et al., 2021). We introduce the first sample-efficient algorithm for LMDPs without any additional structural assumptions. Our result builds off a new perspective on the role of off-policy evaluation guarantees and coverage coefficients in LMDPs, a perspective, that has been overlooked in the context of exploration in partially observed environments. Specifically, we establish a novel off-policy evaluation lemma and introduce a new coverage coefficient for LMDPs. Then, we show how these can be used to derive near-optimal guarantees of an optimistic exploration algorithm. These results, we believe, can be valuable for a wide range of interactive learning problems beyond LMDPs, and especially, for partially observed environments.
6/27/2024
🏅
Offline Oracle-Efficient Learning for Contextual MDPs via Layerwise Exploration-Exploitation Tradeoff
Jian Qian, Haichen Hu, David Simchi-Levi
0
0
Motivated by the recent discovery of a statistical and computational reduction from contextual bandits to offline regression (Simchi-Levi and Xu, 2021), we address the general (stochastic) Contextual Markov Decision Process (CMDP) problem with horizon H (as known as CMDP with H layers). In this paper, we introduce a reduction from CMDPs to offline density estimation under the realizability assumption, i.e., a model class M containing the true underlying CMDP is provided in advance. We develop an efficient, statistically near-optimal algorithm requiring only O(HlogT) calls to an offline density estimation algorithm (or oracle) across all T rounds of interaction. This number can be further reduced to O(HloglogT) if T is known in advance. Our results mark the first efficient and near-optimal reduction from CMDPs to offline density estimation without imposing any structural assumptions on the model class. A notable feature of our algorithm is the design of a layerwise exploration-exploitation tradeoff tailored to address the layerwise structure of CMDPs. Additionally, our algorithm is versatile and applicable to pure exploration tasks in reward-free reinforcement learning.
5/29/2024
🔍
A Primal-Dual Algorithm for Offline Constrained Reinforcement Learning with Linear MDPs
Kihyuk Hong, Ambuj Tewari
0
0
We study offline reinforcement learning (RL) with linear MDPs under the infinite-horizon discounted setting which aims to learn a policy that maximizes the expected discounted cumulative reward using a pre-collected dataset. Existing algorithms for this setting either require a uniform data coverage assumptions or are computationally inefficient for finding an $epsilon$-optimal policy with $O(epsilon^{-2})$ sample complexity. In this paper, we propose a primal dual algorithm for offline RL with linear MDPs in the infinite-horizon discounted setting. Our algorithm is the first computationally efficient algorithm in this setting that achieves sample complexity of $O(epsilon^{-2})$ with partial data coverage assumption. Our work is an improvement upon a recent work that requires $O(epsilon^{-4})$ samples. Moreover, we extend our algorithm to work in the offline constrained RL setting that enforces constraints on additional reward signals.
6/4/2024
🏅
Anytime-Constrained Reinforcement Learning
Jeremy McMahan, Xiaojin Zhu
0
0
We introduce and study constrained Markov Decision Processes (cMDPs) with anytime constraints. An anytime constraint requires the agent to never violate its budget at any point in time, almost surely. Although Markovian policies are no longer sufficient, we show that there exist optimal deterministic policies augmented with cumulative costs. In fact, we present a fixed-parameter tractable reduction from anytime-constrained cMDPs to unconstrained MDPs. Our reduction yields planning and learning algorithms that are time and sample-efficient for tabular cMDPs so long as the precision of the costs is logarithmic in the size of the cMDP. However, we also show that computing non-trivial approximately optimal policies is NP-hard in general. To circumvent this bottleneck, we design provable approximation algorithms that efficiently compute or learn an arbitrarily accurate approximately feasible policy with optimal value so long as the maximum supported cost is bounded by a polynomial in the cMDP or the absolute budget. Given our hardness results, our approximation guarantees are the best possible under worst-case analysis.
6/14/2024