RNNs, CNNs and Transformers in Human Action Recognition: A Survey and A Hybrid Model

0

Sign in to get full access
Overview
- This paper provides a comprehensive survey of three popular deep learning architectures used for human action recognition: Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Transformers.
- The authors also propose a novel hybrid model that combines the strengths of these approaches to improve human action recognition performance.
Plain English Explanation
This research paper explores the use of different deep learning models for the task of recognizing human actions in video data. The three main models discussed are:
-
Recurrent Neural Networks (RNNs): These models are well-suited for processing sequential data, such as video frames, and can capture the temporal dynamics of human actions.
-
Convolutional Neural Networks (CNNs): These models excel at extracting spatial features from image-like data, making them useful for analyzing the visual aspects of human actions.
-
Transformers: This relatively new architecture has shown promising results in various tasks, including action recognition, by effectively modeling long-range dependencies in the data.
The authors of the paper not only provide a comprehensive survey of these models and their applications in human action recognition but also propose a novel hybrid approach that combines the strengths of these different architectures. This hybrid model aims to leverage the complementary capabilities of RNNs, CNNs, and Transformers to achieve improved performance on the task of recognizing human actions in video data.
Technical Explanation
The paper begins by providing a background on the three deep learning architectures - RNNs, CNNs, and Transformers - and their respective strengths and weaknesses in the context of human action recognition.
For RNNs, the authors discuss how they can effectively model the temporal dynamics of human actions by processing video frames in a sequential manner. CNNs, on the other hand, are shown to be adept at extracting relevant spatial features from individual video frames, capturing the visual characteristics of the actions.
The Transformer architecture, which has gained popularity in recent years, is then introduced. Transformers are known for their ability to capture long-range dependencies in the data, making them a promising approach for human action recognition tasks.
Building on this background, the authors propose a hybrid model that combines the strengths of these three architectures. The proposed model incorporates components from RNNs, CNNs, and Transformers, with the goal of leveraging the complementary capabilities of these architectures to achieve superior performance on human action recognition tasks.
The paper also includes a detailed review of the existing literature on the application of these deep learning models in human action recognition, providing a comprehensive summary of the state-of-the-art approaches and their performance on benchmark datasets.
Critical Analysis
The paper provides a well-researched and thorough survey of the use of RNNs, CNNs, and Transformers for human action recognition. The authors' decision to propose a novel hybrid model that combines these architectures is a promising approach, as it aims to address the limitations of individual models and capitalize on their respective strengths.
One potential limitation of the paper is that it does not provide a detailed evaluation of the proposed hybrid model, as the focus is primarily on the survey and background aspects. Although the authors mention the potential benefits of the hybrid approach, a more in-depth analysis of its performance, including a comparison with state-of-the-art models, would have strengthened the paper's contribution.
Additionally, the paper does not delve into the potential challenges or caveats associated with the use of these deep learning models for human action recognition. Discussing factors such as data requirements, computational complexity, and potential biases in the models could have provided a more holistic understanding of the field.
Nevertheless, the paper serves as a valuable resource for researchers and practitioners interested in the application of deep learning techniques, particularly RNNs, CNNs, and Transformers, for the task of human action recognition. The proposed hybrid model also presents an intriguing direction for future research in this area.
Conclusion
This research paper provides a comprehensive survey of the use of Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Transformers for human action recognition. The authors not only review the strengths and weaknesses of these architectures but also propose a novel hybrid model that combines their complementary capabilities to improve performance on this task.
The paper's findings highlight the potential of leveraging the unique strengths of different deep learning models to tackle complex problems in computer vision and video analysis. The proposed hybrid approach, if further developed and evaluated, could contribute to advancements in human action recognition and have practical applications in areas such as video surveillance, human-computer interaction, and sports analysis.
Overall, this research paper offers a valuable resource for researchers and practitioners interested in exploring the intersection of deep learning and human action recognition, providing a solid foundation for future work in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RNNs, CNNs and Transformers in Human Action Recognition: A Survey and A Hybrid Model
Khaled Alomar, Halil Ibrahim Aysel, Xiaohao Cai
Human Action Recognition (HAR) encompasses the task of monitoring human activities across various domains, including but not limited to medical, educational, entertainment, visual surveillance, video retrieval, and the identification of anomalous activities. Over the past decade, the field of HAR has witnessed substantial progress by leveraging Convolutional Neural Networks (CNNs) to effectively extract and comprehend intricate information, thereby enhancing the overall performance of HAR systems. Recently, the domain of computer vision has witnessed the emergence of Vision Transformers (ViTs) as a potent solution. The efficacy of transformer architecture has been validated beyond the confines of image analysis, extending their applicability to diverse video-related tasks. Notably, within this landscape, the research community has shown keen interest in HAR, acknowledging its manifold utility and widespread adoption across various domains. This article aims to present an encompassing survey that focuses on CNNs and the evolution of Recurrent Neural Networks (RNNs) to ViTs given their importance in the domain of HAR. By conducting a thorough examination of existing literature and exploring emerging trends, this study undertakes a critical analysis and synthesis of the accumulated knowledge in this field. Additionally, it investigates the ongoing efforts to develop hybrid approaches. Following this direction, this article presents a novel hybrid model that seeks to integrate the inherent strengths of CNNs and ViTs.
Read more8/16/2024
🤔
0
From CNNs to Transformers in Multimodal Human Action Recognition: A Survey
Muhammad Bilal Shaikh, Syed Mohammed Shamsul Islam, Douglas Chai, Naveed Akhtar
Due to its widespread applications, human action recognition is one of the most widely studied research problems in Computer Vision. Recent studies have shown that addressing it using multimodal data leads to superior performance as compared to relying on a single data modality. During the adoption of deep learning for visual modelling in the last decade, action recognition approaches have mainly relied on Convolutional Neural Networks (CNNs). However, the recent rise of Transformers in visual modelling is now also causing a paradigm shift for the action recognition task. This survey captures this transition while focusing on Multimodal Human Action Recognition (MHAR). Unique to the induction of multimodal computational models is the process of fusing the features of the individual data modalities. Hence, we specifically focus on the fusion design aspects of the MHAR approaches. We analyze the classic and emerging techniques in this regard, while also highlighting the popular trends in the adaption of CNN and Transformer building blocks for the overall problem. In particular, we emphasize on recent design choices that have led to more efficient MHAR models. Unlike existing reviews, which discuss Human Action Recognition from a broad perspective, this survey is specifically aimed at pushing the boundaries of MHAR research by identifying promising architectural and fusion design choices to train practicable models. We also provide an outlook of the multimodal datasets from their scale and evaluation viewpoint. Finally, building on the reviewed literature, we discuss the challenges and future avenues for MHAR.
Read more5/28/2024
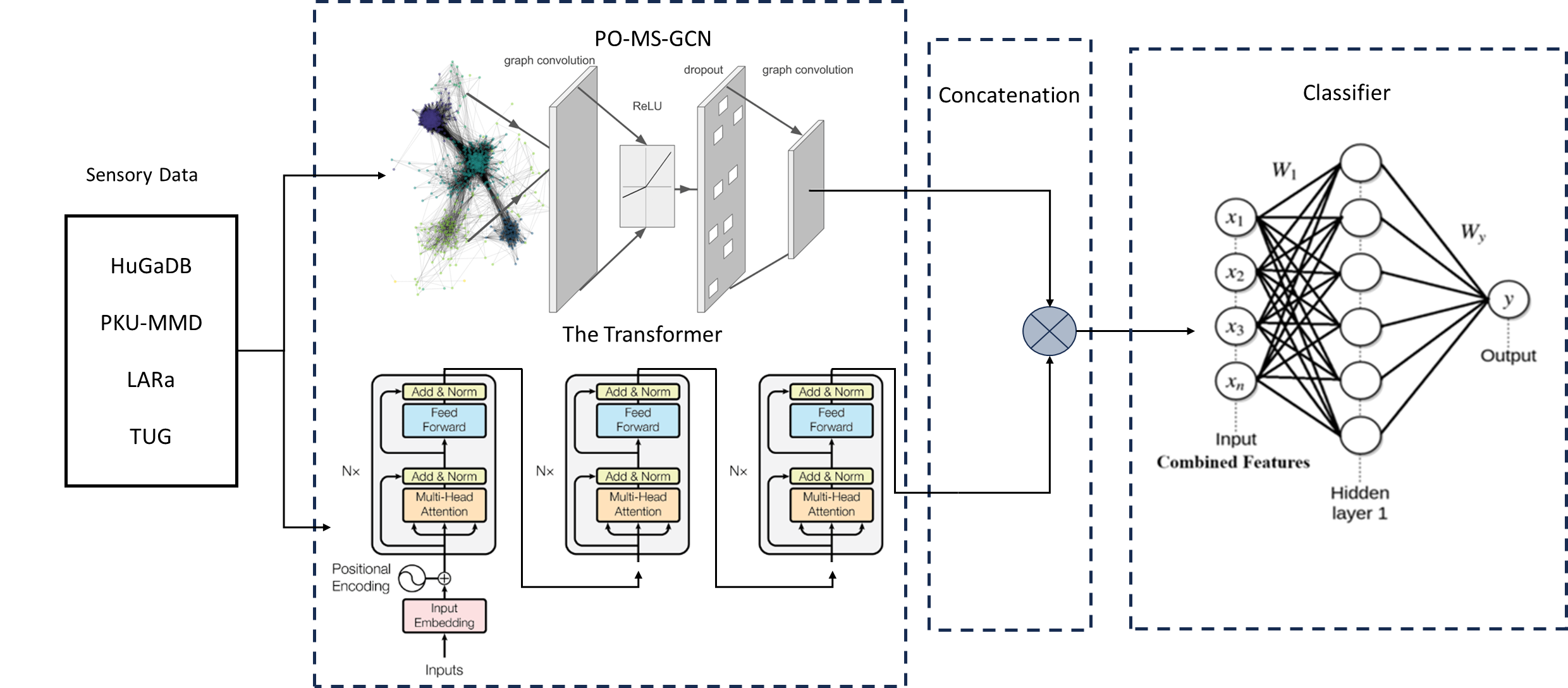
0
Feature Fusion for Human Activity Recognition using Parameter-Optimized Multi-Stage Graph Convolutional Network and Transformer Models
Mohammad Belal (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Taimur Hassan (Abu Dhabi University, Abu Dhabi, United Arab Emirates), Abdelfatah Ahmed (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Ahmad Aljarah (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Nael Alsheikh (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Irfan Hussain (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates)
Human activity recognition (HAR) is a crucial area of research that involves understanding human movements using computer and machine vision technology. Deep learning has emerged as a powerful tool for this task, with models such as Convolutional Neural Networks (CNNs) and Transformers being employed to capture various aspects of human motion. One of the key contributions of this work is the demonstration of the effectiveness of feature fusion in improving HAR accuracy by capturing spatial and temporal features, which has important implications for the development of more accurate and robust activity recognition systems. The study uses sensory data from HuGaDB, PKU-MMD, LARa, and TUG datasets. Two model, the PO-MS-GCN and a Transformer were trained and evaluated, with PO-MS-GCN outperforming state-of-the-art models. HuGaDB and TUG achieved high accuracies and f1-scores, while LARa and PKU-MMD had lower scores. Feature fusion improved results across datasets.
Read more6/26/2024

0
A Critical Analysis on Machine Learning Techniques for Video-based Human Activity Recognition of Surveillance Systems: A Review
Shahriar Jahan, Roknuzzaman, Md Robiul Islam
Upsurging abnormal activities in crowded locations such as airports, train stations, bus stops, shopping malls, etc., urges the necessity for an intelligent surveillance system. An intelligent surveillance system can differentiate between normal and suspicious activities from real-time video analysis that will enable to take appropriate measures regarding the level of an anomaly instantaneously and efficiently. Video-based human activity recognition has intrigued many researchers with its pressing issues and a variety of applications ranging from simple hand gesture recognition to crucial behavior recognition in a surveillance system. This paper provides a critical survey of video-based Human Activity Recognition (HAR) techniques beginning with an examination of basic approaches for detecting and recognizing suspicious behavior followed by a critical analysis of machine learning and deep learning techniques such as Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), Hidden Markov Model (HMM), K-means Clustering etc. A detailed investigation and comparison are done on these learning techniques on the basis of feature extraction techniques, parameter initialization, and optimization algorithms, accuracy, etc. The purpose of this review is to prioritize positive schemes and to assist researchers with emerging advancements in this field's future endeavors. This paper also pragmatically discusses existing challenges in the field of HAR and examines the prospects in the field.
Read more9/4/2024