On the Road to Clarity: Exploring Explainable AI for World Models in a Driver Assistance System
2404.17350
0
0
Abstract
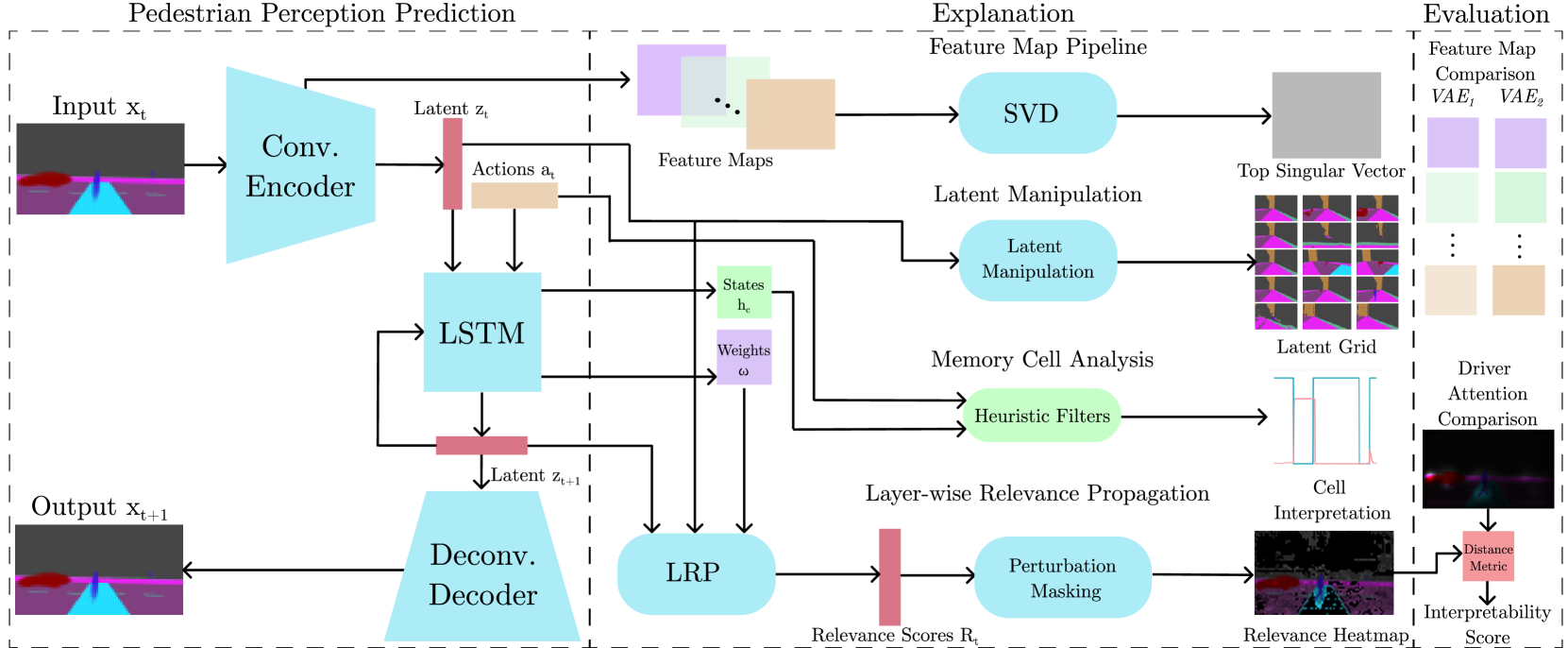
In Autonomous Driving (AD) transparency and safety are paramount, as mistakes are costly. However, neural networks used in AD systems are generally considered black boxes. As a countermeasure, we have methods of explainable AI (XAI), such as feature relevance estimation and dimensionality reduction. Coarse graining techniques can also help reduce dimensionality and find interpretable global patterns. A specific coarse graining method is Renormalization Groups from statistical physics. It has previously been applied to Restricted Boltzmann Machines (RBMs) to interpret unsupervised learning. We refine this technique by building a transparent backbone model for convolutional variational autoencoders (VAE) that allows mapping latent values to input features and has performance comparable to trained black box VAEs. Moreover, we propose a custom feature map visualization technique to analyze the internal convolutional layers in the VAE to explain internal causes of poor reconstruction that may lead to dangerous traffic scenarios in AD applications. In a second key contribution, we propose explanation and evaluation techniques for the internal dynamics and feature relevance of prediction networks. We test a long short-term memory (LSTM) network in the computer vision domain to evaluate the predictability and in future applications potentially safety of prediction models. We showcase our methods by analyzing a VAE-LSTM world model that predicts pedestrian perception in an urban traffic situation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of explainable AI (XAI) techniques to enhance the transparency and interpretability of world models in a driver assistance system.
- The research was partially funded by the Federal Ministry of Education and Research (BMBF) in Germany, through the 'NEUPA' and 'KI-IoT' projects.
- The authors acknowledge contributions from Robert, Ellen, and Anita de Mello Koch for their insights, advice, and providing source code.
Plain English Explanation
Autonomous driving systems rely on complex machine learning models, known as "world models," to understand the environment and make decisions. However, these models can be difficult for humans to interpret and understand. Explainable AI techniques aim to make these models more transparent, so that users can better comprehend how the system is making decisions.
In this research, the authors explore different XAI methods to improve the interpretability of world models used in a driver assistance system. They investigate approaches like disentangled explanations and model-agnostic explainability frameworks to provide users with a clearer understanding of how the system perceives and reacts to the driving environment.
By making the world models more interpretable, the researchers aim to build trust and confidence in the autonomous driving system, as well as identify potential issues or biases that may be present in the model's decision-making process. Ultimately, this work contributes to the broader goal of developing explainable AI systems for autonomous vehicles, which is crucial for their safe and widespread adoption.
Technical Explanation
The paper presents a study on enhancing the interpretability of world models used in a driver assistance system through the application of various explainable AI (XAI) techniques. The researchers investigate several approaches, including:
-
Disentangled Explanations: The authors explore methods to generate disentangled explanations that can provide users with a clearer understanding of the specific factors influencing the model's predictions.
-
Model-Agnostic Explainability Frameworks: The researchers evaluate model-agnostic explainability frameworks that can be applied to the world models without requiring access to their internal architecture.
-
Latent Pathway Interpretation: The paper also investigates techniques to enhance the interpretability of the world models' internal representations, allowing users to better understand the reasoning behind the system's decisions.
The research was conducted as part of two projects funded by the Federal Ministry of Education and Research (BMBF) in Germany: 'NEUPA' and 'KI-IoT'. The authors acknowledge the valuable contributions of Robert, Ellen, and Anita de Mello Koch, who provided insights, advice, and source code for the study.
Critical Analysis
The paper raises important considerations regarding the transparency and interpretability of world models used in autonomous driving systems. By exploring various XAI techniques, the authors demonstrate the potential to enhance user understanding and trust in these complex models.
However, the paper also acknowledges several limitations and areas for further research. For instance, the authors note that the effectiveness of the XAI methods may be dependent on the specific world model architecture and the driving scenarios considered. Additionally, the paper suggests that more comprehensive evaluation of the proposed approaches is necessary to assess their real-world impact and practical implications.
Furthermore, the research focuses primarily on the technical aspects of XAI integration, but does not delve deeply into the broader societal and ethical implications of this technology. Aspects such as bias mitigation, privacy considerations, and the potential for misuse or over-reliance on the explanations provided by the XAI systems could be valuable areas for further investigation.
Overall, this paper represents a valuable contribution to the field of explainable AI for autonomous driving, but continued research and multidisciplinary collaboration will be crucial to address the complex challenges and implications of this technology.
Conclusion
This research explores the use of explainable AI (XAI) techniques to enhance the transparency and interpretability of world models used in a driver assistance system. By investigating methods such as disentangled explanations, model-agnostic explainability frameworks, and latent pathway interpretation, the authors aim to improve user understanding and trust in these complex autonomous driving models.
The findings of this study contribute to the broader efforts to develop explainable AI systems for autonomous vehicles, which is a crucial step towards their safe and widespread adoption. However, the paper also highlights the need for further research to address the limitations and broader societal implications of this technology.
As autonomous driving systems become more advanced and integrated into our daily lives, the importance of developing interpretable and accountable AI models will only continue to grow. This research represents a valuable step in that direction, paving the way for a future where AI-powered transportation systems can be understood and trusted by the users they serve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Causality-Aware Local Interpretable Model-Agnostic Explanations
Martina Cinquini, Riccardo Guidotti
0
0
A main drawback of eXplainable Artificial Intelligence (XAI) approaches is the feature independence assumption, hindering the study of potential variable dependencies. This leads to approximating black box behaviors by analyzing the effects on randomly generated feature values that may rarely occur in the original samples. This paper addresses this issue by integrating causal knowledge in an XAI method to enhance transparency and enable users to assess the quality of the generated explanations. Specifically, we propose a novel extension to a widely used local and model-agnostic explainer, which encodes explicit causal relationships within the data surrounding the instance being explained. Extensive experiments show that our approach overcomes the original method in terms of faithfully replicating the black-box model's mechanism and the consistency and reliability of the generated explanations.
4/16/2024
New!Solving the enigma: Deriving optimal explanations of deep networks
Michail Mamalakis, Antonios Mamalakis, Ingrid Agartz, Lynn Egeland M{o}rch-Johnsen, Graham Murray, John Suckling, Pietro Lio
0
0
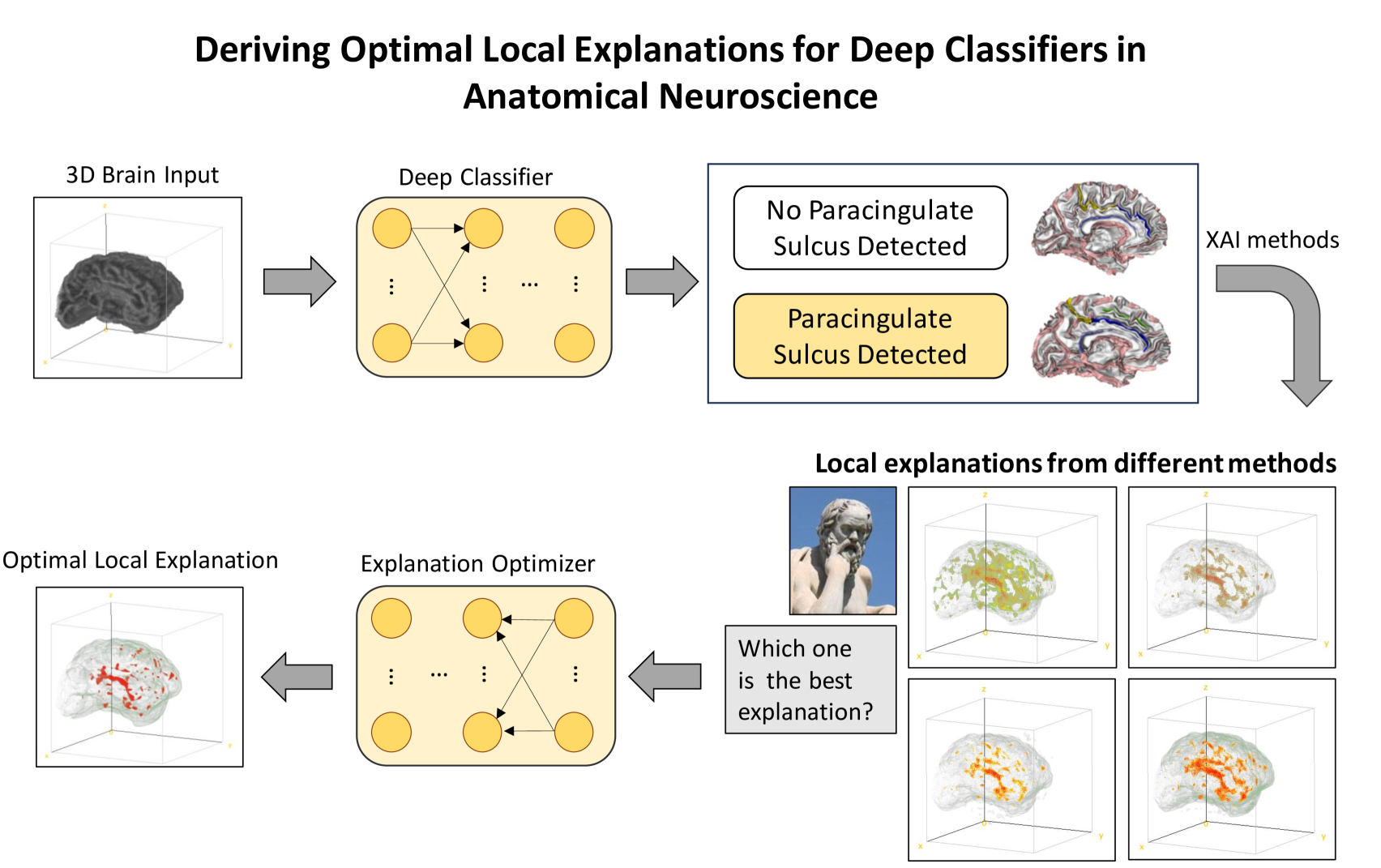
The accelerated progress of artificial intelligence (AI) has popularized deep learning models across domains, yet their inherent opacity poses challenges, notably in critical fields like healthcare, medicine and the geosciences. Explainable AI (XAI) has emerged to shed light on these black box models, helping decipher their decision making process. Nevertheless, different XAI methods yield highly different explanations. This inter-method variability increases uncertainty and lowers trust in deep networks' predictions. In this study, for the first time, we propose a novel framework designed to enhance the explainability of deep networks, by maximizing both the accuracy and the comprehensibility of the explanations. Our framework integrates various explanations from established XAI methods and employs a non-linear explanation optimizer to construct a unique and optimal explanation. Through experiments on multi-class and binary classification tasks in 2D object and 3D neuroscience imaging, we validate the efficacy of our approach. Our explanation optimizer achieved superior faithfulness scores, averaging 155% and 63% higher than the best performing XAI method in the 3D and 2D applications, respectively. Additionally, our approach yielded lower complexity, increasing comprehensibility. Our results suggest that optimal explanations based on specific criteria are derivable and address the issue of inter-method variability in the current XAI literature.
5/17/2024
🧠
Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces
Pattarawat Chormai, Jan Herrmann, Klaus-Robert Muller, Gr'egoire Montavon
0
0
Explainable AI aims to overcome the black-box nature of complex ML models like neural networks by generating explanations for their predictions. Explanations often take the form of a heatmap identifying input features (e.g. pixels) that are relevant to the model's decision. These explanations, however, entangle the potentially multiple factors that enter into the overall complex decision strategy. We propose to disentangle explanations by extracting at some intermediate layer of a neural network, subspaces that capture the multiple and distinct activation patterns (e.g. visual concepts) that are relevant to the prediction. To automatically extract these subspaces, we propose two new analyses, extending principles found in PCA or ICA to explanations. These novel analyses, which we call principal relevant component analysis (PRCA) and disentangled relevant subspace analysis (DRSA), maximize relevance instead of e.g. variance or kurtosis. This allows for a much stronger focus of the analysis on what the ML model actually uses for predicting, ignoring activations or concepts to which the model is invariant. Our approach is general enough to work alongside common attribution techniques such as Shapley Value, Integrated Gradients, or LRP. Our proposed methods show to be practically useful and compare favorably to the state of the art as demonstrated on benchmarks and three use cases.
4/16/2024
📉
T-Explainer: A Model-Agnostic Explainability Framework Based on Gradients
Evandro S. Ortigossa, F'abio F. Dias, Brian Barr, Claudio T. Silva, Luis Gustavo Nonato
0
0
The development of machine learning applications has increased significantly in recent years, motivated by the remarkable ability of learning-powered systems to discover and generalize intricate patterns hidden in massive datasets. Modern learning models, while powerful, often exhibit a level of complexity that renders them opaque black boxes, resulting in a notable lack of transparency that hinders our ability to decipher their decision-making processes. Opacity challenges the interpretability and practical application of machine learning, especially in critical domains where understanding the underlying reasons is essential for informed decision-making. Explainable Artificial Intelligence (XAI) rises to meet that challenge, unraveling the complexity of black boxes by providing elucidating explanations. Among the various XAI approaches, feature attribution/importance XAI stands out for its capacity to delineate the significance of input features in the prediction process. However, most existing attribution methods have limitations, such as instability, when divergent explanations may result from similar or even the same instance. In this work, we introduce T-Explainer, a novel local additive attribution explainer based on Taylor expansion endowed with desirable properties, such as local accuracy and consistency, while stable over multiple runs. We demonstrate T-Explainer's effectiveness through benchmark experiments with well-known attribution methods. In addition, T-Explainer is developed as a comprehensive XAI framework comprising quantitative metrics to assess and visualize attribution explanations.
4/26/2024