Exploring Latent Pathways: Enhancing the Interpretability of Autonomous Driving with a Variational Autoencoder
2404.01750
0
0

Abstract
Autonomous driving presents a complex challenge, which is usually addressed with artificial intelligence models that are end-to-end or modular in nature. Within the landscape of modular approaches, a bio-inspired neural circuit policy model has emerged as an innovative control module, offering a compact and inherently interpretable system to infer a steering wheel command from abstract visual features. Here, we take a leap forward by integrating a variational autoencoder with the neural circuit policy controller, forming a solution that directly generates steering commands from input camera images. By substituting the traditional convolutional neural network approach to feature extraction with a variational autoencoder, we enhance the system's interpretability, enabling a more transparent and understandable decision-making process. In addition to the architectural shift toward a variational autoencoder, this study introduces the automatic latent perturbation tool, a novel contribution designed to probe and elucidate the latent features within the variational autoencoder. The automatic latent perturbation tool automates the interpretability process, offering granular insights into how specific latent variables influence the overall model's behavior. Through a series of numerical experiments, we demonstrate the interpretative power of the variational autoencoder-neural circuit policy model and the utility of the automatic latent perturbation tool in making the inner workings of autonomous driving systems more transparent.
Create account to get full access
Overview
- This paper explores using a Variational Autoencoder (VAE) to enhance the interpretability of autonomous driving systems.
- The researchers aim to learn latent pathways that capture the hidden decision-making process of the autonomous driving model.
- By making the model more interpretable, the goal is to increase trust and transparency in autonomous driving technology.
Plain English Explanation
The paper looks at a way to make autonomous driving systems more understandable. Currently, these systems can be "black boxes" - their inner workings are hard for humans to see and comprehend. The researchers want to change that by using a special kind of artificial intelligence called a Variational Autoencoder (VAE).
A VAE can find hidden patterns and relationships in data that aren't immediately obvious. The researchers apply this to data from autonomous driving models, with the goal of uncovering the "thought process" the model uses to make decisions. By making this thought process more transparent, they hope to build trust and confidence in self-driving car technology.
Imagine you're trying to understand how a toddler solves a puzzle. You can't just look at the final solution - you need to see the intermediate steps and thought process. Similarly, this research aims to peek inside the "mind" of an autonomous driving system to better understand how it navigates the road. Making the system more interpretable could lead to safer, more trustworthy self-driving cars.
Technical Explanation
The key elements of the paper include:
- Experiment Design: The researchers trained a VAE on data from an autonomous driving model, including images, vehicle control signals, and other inputs/outputs.
- VAE Architecture: The VAE learns a compressed, low-dimensional representation of the driving data. This latent representation is intended to capture the underlying decision-making process.
- Insights: Analysis of the learned latent pathways revealed interpretable features like road geometry, traffic, and driver intent. These insights can help explain the autonomous model's behavior.
Critical Analysis
The paper acknowledges some limitations of the approach, such as the challenge of validating the interpretability of the latent representations. More work is needed to ensure the learned pathways accurately reflect the true decision-making process.
Additionally, the paper does not address potential issues around privacy and data security that could arise from opening up the "black box" of autonomous driving systems. Careful consideration is required to balance interpretability with protecting sensitive information.
Overall, the research represents a promising step towards making autonomous driving more transparent and trustworthy. However, further validation and real-world testing are needed before deploying such interpretability techniques in production self-driving cars.
Conclusion
This paper demonstrates how Variational Autoencoders can be used to enhance the interpretability of autonomous driving systems. By uncovering the hidden "thought process" of the driving model, the aim is to increase trust and confidence in self-driving car technology. While more work is needed, this research represents an important advance towards making autonomous vehicles more transparent and accountable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
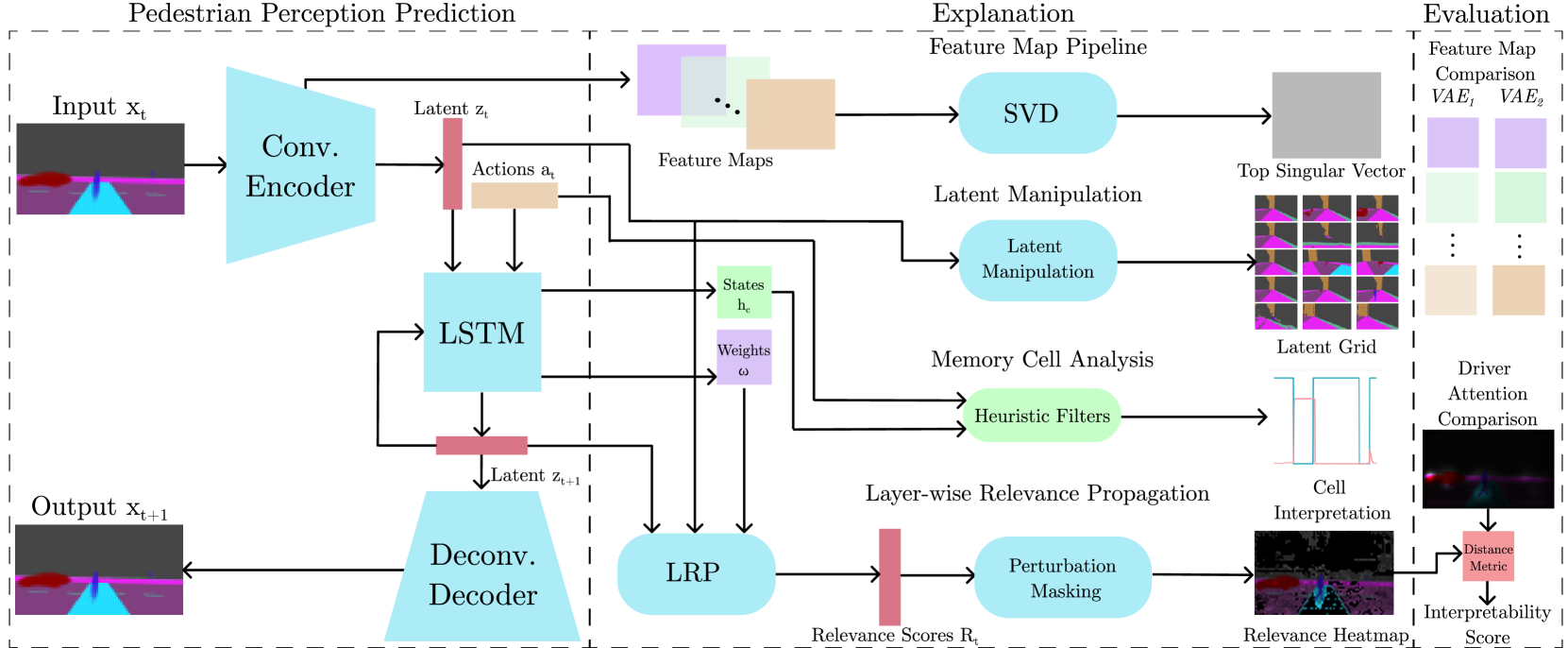
On the Road to Clarity: Exploring Explainable AI for World Models in a Driver Assistance System
Mohamed Roshdi, Julian Petzold, Mostafa Wahby, Hussein Ebrahim, Mladen Berekovic, Heiko Hamann
0
0
In Autonomous Driving (AD) transparency and safety are paramount, as mistakes are costly. However, neural networks used in AD systems are generally considered black boxes. As a countermeasure, we have methods of explainable AI (XAI), such as feature relevance estimation and dimensionality reduction. Coarse graining techniques can also help reduce dimensionality and find interpretable global patterns. A specific coarse graining method is Renormalization Groups from statistical physics. It has previously been applied to Restricted Boltzmann Machines (RBMs) to interpret unsupervised learning. We refine this technique by building a transparent backbone model for convolutional variational autoencoders (VAE) that allows mapping latent values to input features and has performance comparable to trained black box VAEs. Moreover, we propose a custom feature map visualization technique to analyze the internal convolutional layers in the VAE to explain internal causes of poor reconstruction that may lead to dangerous traffic scenarios in AD applications. In a second key contribution, we propose explanation and evaluation techniques for the internal dynamics and feature relevance of prediction networks. We test a long short-term memory (LSTM) network in the computer vision domain to evaluate the predictability and in future applications potentially safety of prediction models. We showcase our methods by analyzing a VAE-LSTM world model that predicts pedestrian perception in an urban traffic situation.
4/29/2024
🔎
Poisson Variational Autoencoder
Hadi Vafaii, Dekel Galor, Jacob L. Yates
0
0
Variational autoencoders (VAE) employ Bayesian inference to interpret sensory inputs, mirroring processes that occur in primate vision across both ventral (Higgins et al., 2021) and dorsal (Vafaii et al., 2023) pathways. Despite their success, traditional VAEs rely on continuous latent variables, which deviates sharply from the discrete nature of biological neurons. Here, we developed the Poisson VAE (P-VAE), a novel architecture that combines principles of predictive coding with a VAE that encodes inputs into discrete spike counts. Combining Poisson-distributed latent variables with predictive coding introduces a metabolic cost term in the model loss function, suggesting a relationship with sparse coding which we verify empirically. Additionally, we analyze the geometry of learned representations, contrasting the P-VAE to alternative VAE models. We find that the P-VAEencodes its inputs in relatively higher dimensions, facilitating linear separability of categories in a downstream classification task with a much better (5x) sample efficiency. Our work provides an interpretable computational framework to study brain-like sensory processing and paves the way for a deeper understanding of perception as an inferential process.
5/24/2024
💬
Language Model-Based Paired Variational Autoencoders for Robotic Language Learning
Ozan Ozdemir, Matthias Kerzel, Cornelius Weber, Jae Hee Lee, Stefan Wermter
0
0
Human infants learn language while interacting with their environment in which their caregivers may describe the objects and actions they perform. Similar to human infants, artificial agents can learn language while interacting with their environment. In this work, first, we present a neural model that bidirectionally binds robot actions and their language descriptions in a simple object manipulation scenario. Building on our previous Paired Variational Autoencoders (PVAE) model, we demonstrate the superiority of the variational autoencoder over standard autoencoders by experimenting with cubes of different colours, and by enabling the production of alternative vocabularies. Additional experiments show that the model's channel-separated visual feature extraction module can cope with objects of different shapes. Next, we introduce PVAE-BERT, which equips the model with a pretrained large-scale language model, i.e., Bidirectional Encoder Representations from Transformers (BERT), enabling the model to go beyond comprehending only the predefined descriptions that the network has been trained on; the recognition of action descriptions generalises to unconstrained natural language as the model becomes capable of understanding unlimited variations of the same descriptions. Our experiments suggest that using a pretrained language model as the language encoder allows our approach to scale up for real-world scenarios with instructions from human users.
5/7/2024
🚀
Causal Flow-based Variational Auto-Encoder for Disentangled Causal Representation Learning
Di Fan, Yannian Kou, Chuanhou Gao
0
0
Disentangled representation learning aims to learn low-dimensional representations of data, where each dimension corresponds to an underlying generative factor. Currently, Variational Auto-Encoder (VAE) are widely used for disentangled representation learning, with the majority of methods assuming independence among generative factors. However, in real-world scenarios, generative factors typically exhibit complex causal relationships. We thus design a new VAE-based framework named Disentangled Causal Variational Auto-Encoder (DCVAE), which includes a variant of autoregressive flows known as causal flows, capable of learning effective causal disentangled representations. We provide a theoretical analysis of the disentanglement identifiability of DCVAE, ensuring that our model can effectively learn causal disentangled representations. The performance of DCVAE is evaluated on both synthetic and real-world datasets, demonstrating its outstanding capability in achieving causal disentanglement and performing intervention experiments. Moreover, DCVAE exhibits remarkable performance on downstream tasks and has the potential to learn the true causal structure among factors.
5/9/2024