Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces
2212.14855
0
0
🧠
Abstract
Explainable AI aims to overcome the black-box nature of complex ML models like neural networks by generating explanations for their predictions. Explanations often take the form of a heatmap identifying input features (e.g. pixels) that are relevant to the model's decision. These explanations, however, entangle the potentially multiple factors that enter into the overall complex decision strategy. We propose to disentangle explanations by extracting at some intermediate layer of a neural network, subspaces that capture the multiple and distinct activation patterns (e.g. visual concepts) that are relevant to the prediction. To automatically extract these subspaces, we propose two new analyses, extending principles found in PCA or ICA to explanations. These novel analyses, which we call principal relevant component analysis (PRCA) and disentangled relevant subspace analysis (DRSA), maximize relevance instead of e.g. variance or kurtosis. This allows for a much stronger focus of the analysis on what the ML model actually uses for predicting, ignoring activations or concepts to which the model is invariant. Our approach is general enough to work alongside common attribution techniques such as Shapley Value, Integrated Gradients, or LRP. Our proposed methods show to be practically useful and compare favorably to the state of the art as demonstrated on benchmarks and three use cases.
Create account to get full access
Overview
- Explainable AI aims to make complex machine learning (ML) models like neural networks more interpretable by generating explanations for their predictions
- Typical explanations use heatmaps to highlight important input features, but these can be entangled, mixing multiple factors that contribute to the overall decision
- This paper proposes new techniques, called Principal Relevant Component Analysis (PRCA) and Disentangled Relevant Subspace Analysis (DRSA), to extract distinct activation patterns or "concepts" from neural networks that are relevant to the model's predictions
Plain English Explanation
Machine learning models, especially complex ones like neural networks, can be very powerful but also difficult to understand. Explainable AI aims to make these "black box" models more interpretable by explaining how they arrive at their predictions.
A common approach is to generate heatmaps that highlight the most important input features, like pixels in an image, that the model used to make its decision. However, these heatmaps can be messy, entangling multiple factors that all contributed to the final prediction in complex ways.
This paper proposes new techniques to "disentangle" these explanations. The key idea is to look at the activations in the inner layers of the neural network and extract distinct "concepts" or activation patterns that are most relevant to the model's ultimate prediction.
The proposed methods, called Principal Relevant Component Analysis (PRCA) and Disentangled Relevant Subspace Analysis (DRSA), essentially find the most important directions or subspaces in the neural network's hidden representations that best explain its final decision. This allows for cleaner, more interpretable explanations compared to standard heatmaps.
The authors demonstrate that these new techniques work well in practice and can provide more meaningful insights than previous explainability methods, as shown through experiments and case studies.
Technical Explanation
The paper proposes two novel analysis techniques, PRCA and DRSA, to disentangle the explanations provided by complex machine learning models like neural networks.
PRCA and DRSA build on principles from dimensionality reduction techniques like Principal Component Analysis (PCA) and Independent Component Analysis (ICA), but with a key difference - instead of maximizing variance or kurtosis, they maximize the relevance of the extracted components or subspaces to the model's actual prediction.
This allows the methods to focus on just the most important factors used by the model, ignoring activations or "concepts" that the model is invariant to. The extracted subspaces can then be visualized or further analyzed to provide more interpretable explanations compared to standard heatmap-based approaches.
The paper demonstrates the effectiveness of PRCA and DRSA through experiments on benchmark datasets as well as several real-world use cases, showing favorable performance compared to state-of-the-art explainability methods like Shapley Value, Integrated Gradients, and Layer-wise Relevance Propagation (LRP).
Critical Analysis
The paper presents a promising approach to improving the interpretability of complex machine learning models. By focusing the explanation on the most relevant factors used by the model, rather than entangled heatmaps, the proposed PRCA and DRSA techniques can potentially provide users with more meaningful and actionable insights.
However, the authors acknowledge some limitations of their methods. For example, the techniques rely on the availability of well-trained neural networks, which may not always be the case in practice. Additionally, the explanations generated by PRCA and DRSA are still dependent on the specific model architecture and training process, which could limit their generalizability.
Further research could explore ways to make the explanations more model-agnostic, or to integrate the explainability analysis more tightly into the model training process. There are also open questions around the best way to visualize and communicate the extracted "concepts" to end users in an intuitive manner.
Overall, this paper represents a valuable contribution to the field of explainable AI, and the proposed techniques could be a useful tool for practitioners looking to gain deeper insights into their complex machine learning models.
Conclusion
This paper introduces two new analysis methods, PRCA and DRSA, that aim to provide more disentangled and interpretable explanations for the predictions of complex machine learning models like neural networks. By focusing the explanation on the most relevant factors used by the model, rather than entangled heatmaps, these techniques can potentially offer users more meaningful insights into the model's decision-making process.
The authors demonstrate the practical utility of PRCA and DRSA through experiments and case studies, showing favorable performance compared to existing explainability approaches. While the methods still have some limitations, this work represents an important step forward in the field of explainable AI, and the proposed techniques could be a valuable tool for researchers and practitioners looking to better understand and communicate the inner workings of their machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
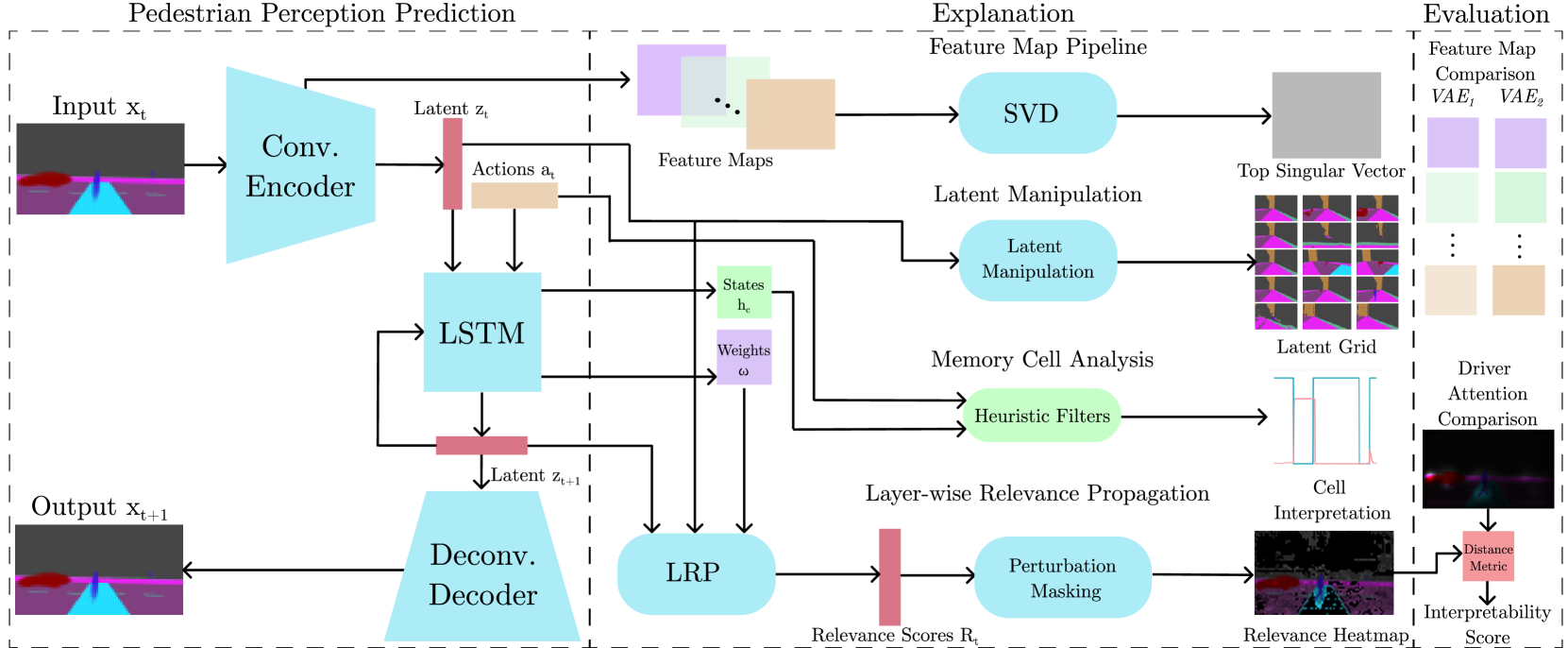
On the Road to Clarity: Exploring Explainable AI for World Models in a Driver Assistance System
Mohamed Roshdi, Julian Petzold, Mostafa Wahby, Hussein Ebrahim, Mladen Berekovic, Heiko Hamann
0
0
In Autonomous Driving (AD) transparency and safety are paramount, as mistakes are costly. However, neural networks used in AD systems are generally considered black boxes. As a countermeasure, we have methods of explainable AI (XAI), such as feature relevance estimation and dimensionality reduction. Coarse graining techniques can also help reduce dimensionality and find interpretable global patterns. A specific coarse graining method is Renormalization Groups from statistical physics. It has previously been applied to Restricted Boltzmann Machines (RBMs) to interpret unsupervised learning. We refine this technique by building a transparent backbone model for convolutional variational autoencoders (VAE) that allows mapping latent values to input features and has performance comparable to trained black box VAEs. Moreover, we propose a custom feature map visualization technique to analyze the internal convolutional layers in the VAE to explain internal causes of poor reconstruction that may lead to dangerous traffic scenarios in AD applications. In a second key contribution, we propose explanation and evaluation techniques for the internal dynamics and feature relevance of prediction networks. We test a long short-term memory (LSTM) network in the computer vision domain to evaluate the predictability and in future applications potentially safety of prediction models. We showcase our methods by analyzing a VAE-LSTM world model that predicts pedestrian perception in an urban traffic situation.
4/29/2024
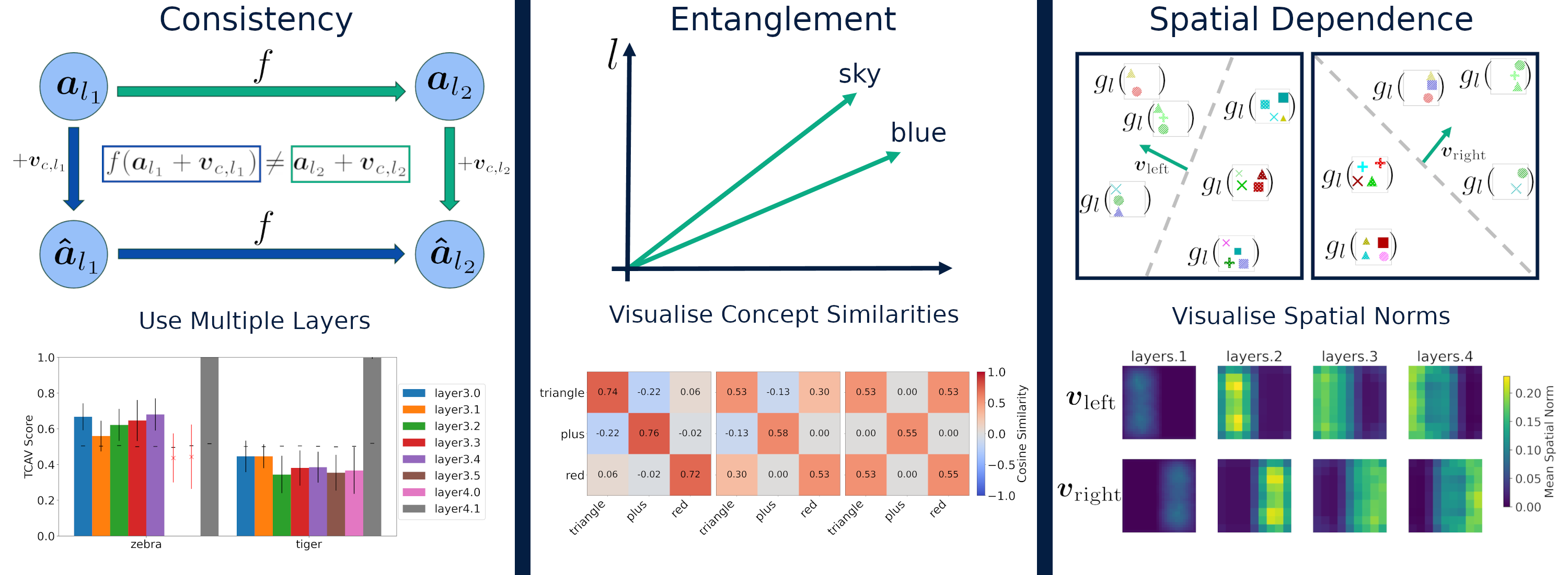
Explaining Explainability: Understanding Concept Activation Vectors
Angus Nicolson, Lisa Schut, J. Alison Noble, Yarin Gal
0
0
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
4/8/2024
🚀
Global Concept Explanations for Graphs by Contrastive Learning
Jonas Teufel, Pascal Friederich
0
0
Beyond improving trust and validating model fairness, xAI practices also have the potential to recover valuable scientific insights in application domains where little to no prior human intuition exists. To that end, we propose a method to extract global concept explanations from the predictions of graph neural networks to develop a deeper understanding of the tasks underlying structure-property relationships. We identify concept explanations as dense clusters in the self-explaining Megan models subgraph latent space. For each concept, we optimize a representative prototype graph and optionally use GPT-4 to provide hypotheses about why each structure has a certain effect on the prediction. We conduct computational experiments on synthetic and real-world graph property prediction tasks. For the synthetic tasks we find that our method correctly reproduces the structural rules by which they were created. For real-world molecular property regression and classification tasks, we find that our method rediscovers established rules of thumb. More specifically, our results for molecular mutagenicity prediction indicate more fine-grained resolution of structural details than existing explainability methods, consistent with previous results from chemistry literature. Overall, our results show promising capability to extract the underlying structure-property relationships for complex graph property prediction tasks.
4/26/2024
👁️
An explainable three dimension framework to uncover learning patterns: A unified look in variable sulci recognition
Michail Mamalakis, Heloise de Vareilles, Atheer AI-Manea, Samantha C. Mitchell, Ingrid Arartz, Lynn Egeland Morch-Johnsen, Jane Garrison, Jon Simons, Pietro Lio, John Suckling, Graham Murray
0
0
Detecting the significant features of the learning process of an artificial intelligence framework in the entire training and validation dataset can be determined as 'global' explanations. Studies in the literature lack of accurate, low-complexity, and three-dimensional (3D) global explanations which are crucial in neuroimaging, a field with a complex representational space that demands more than basic two-dimensional interpretations. To fill this gap, we developed a novel explainable artificial intelligence (XAI) 3D-Framework that provides robust, faithful, and low-complexity global explanations. We evaluated our framework on various 3D deep learning networks trained, validated, and tested on a well-annotated cohort of 596 subjects from the TOP-OSLO study. The focus was on the presence and absence of the paracingulate sulcus, a variable feature of brain morphology correlated with psychotic conditions. Our proposed 3D-Framework outperforms traditional XAI methods in terms of faithfulness for global explanations. As a result, we were able to use these robust explanations to uncover new patterns that not only enhance the credibility and reliability of the training process but also reveal promising new biomarkers and significantly related sub-regions. For the first time, our developed 3D-Framework proposes a way for the scientific community to utilize global explanations to discover novel patterns in this specific neuroscientific application and beyond. This study can helps improve the trustworthiness of AI training processes and push the boundaries of our understanding by revealing new patterns in neuroscience and beyond.
6/11/2024