RoadPainter: Points Are Ideal Navigators for Topology transformER

0
Sign in to get full access
Overview
- The paper introduces a novel deep learning model called RoadPainter that uses point clouds as input to perform topology reasoning for autonomous driving tasks.
- RoadPainter leverages a transformer-based architecture to effectively capture and represent the complex topological structures of roads.
- The key contribution is that points, rather than images or grids, are used as the fundamental input representation, allowing the model to better reason about road topology.
Plain English Explanation
RoadPainter: Points Are Ideal Navigators for Topology transformER presents a new deep learning model called RoadPainter that is designed to help autonomous vehicles understand the complex topology of roads.
The core idea is that using individual points, rather than images or grids, as the input representation allows the model to better capture the intricate structure of roads. This is important for tasks like lane detection, path planning, and navigating intersections, where understanding the overall topology of the road network is crucial.
RoadPainter uses a transformer-based architecture, which is well-suited for modeling the relationships between different parts of the road network. By processing the input as a set of points, rather than a fixed grid, the model can more flexibly adapt to the variable shapes and configurations of real-world roads.
The researchers show that RoadPainter outperforms other state-of-the-art methods on a range of autonomous driving benchmarks, demonstrating the benefits of its point-based, topology-aware approach.
Technical Explanation
RoadPainter: Points Are Ideal Navigators for Topology transformER introduces a novel deep learning model for autonomous driving tasks that leverages point clouds as the fundamental input representation.
The key innovation of RoadPainter is its use of a transformer-based architecture to effectively capture and represent the complex topological structures of roads. Unlike traditional approaches that rely on image-based or grid-based inputs, RoadPainter processes the input as a set of 3D points, allowing it to better reason about the overall topology of the road network.
The transformer-based design of RoadPainter enables the model to learn rich representations of the relationships between different parts of the road, which is crucial for tasks like lane detection, path planning, and navigating intersections. By processing the input as a point cloud, the model can more flexibly adapt to the variable shapes and configurations of real-world roads, rather than being constrained by a fixed grid structure.
The researchers evaluate RoadPainter on several autonomous driving benchmarks and demonstrate that it outperforms other state-of-the-art methods, highlighting the benefits of its point-based, topology-aware approach.
Critical Analysis
The paper presents a compelling approach to leveraging point clouds for topology reasoning in autonomous driving tasks. By using a transformer-based architecture and treating the input as a set of points rather than a grid, RoadPainter is able to better capture the complex and variable nature of real-world road networks.
However, the paper does not address some potential limitations of the approach. For example, the performance of RoadPainter may be affected by the quality and accuracy of the input point clouds, which can be influenced by factors like sensor noise, occlusions, and environmental conditions. Additionally, the computational complexity of the transformer-based architecture may pose challenges for real-time deployment in autonomous vehicles, especially on resource-constrained hardware.
Further research could explore ways to improve the robustness and efficiency of RoadPainter, such as by incorporating techniques for point cloud denoising, sensor fusion, or model optimization. It would also be valuable to investigate the generalization capabilities of the model across different road environments and driving scenarios.
Conclusion
RoadPainter: Points Are Ideal Navigators for Topology transformER presents a novel deep learning approach that leverages point clouds and a transformer-based architecture to perform effective topology reasoning for autonomous driving tasks. By using points as the fundamental input representation, the model is able to better capture the complex and variable structures of real-world road networks, leading to improved performance on a range of benchmarks.
The paper's key contribution is the insight that point-based representations, combined with powerful transformer-based modeling, can offer significant advantages over traditional grid-based or image-based approaches for tasks that require a deep understanding of road topology. As autonomous driving technologies continue to evolve, the ideas and techniques explored in this work could have important implications for the development of more robust and capable self-driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RoadPainter: Points Are Ideal Navigators for Topology transformER
Zhongxing Ma, Shuang Liang, Yongkun Wen, Weixin Lu, Guowei Wan
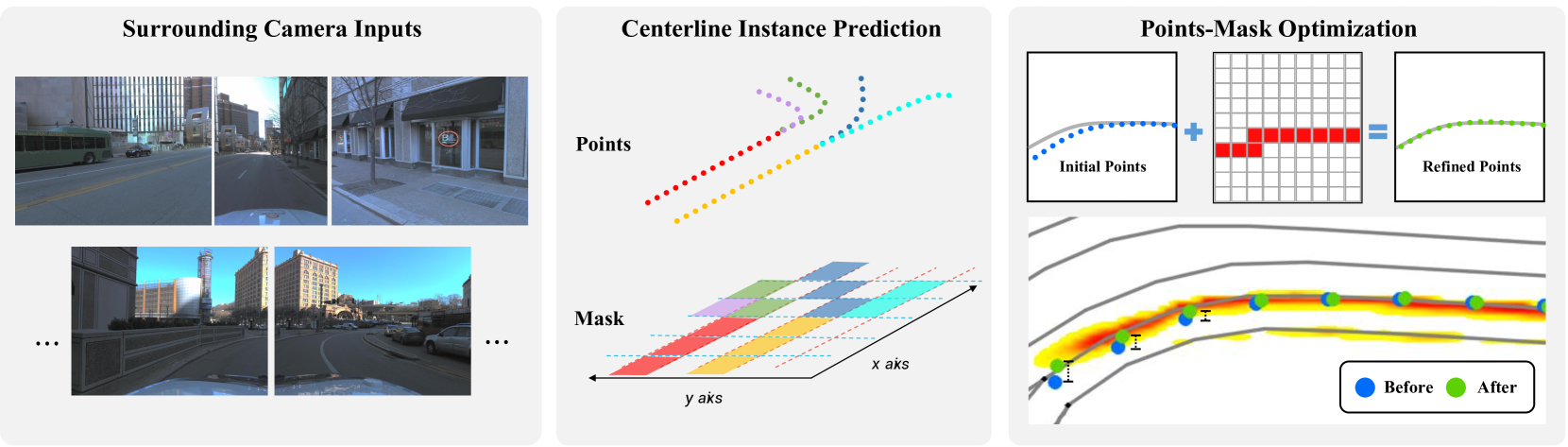
Topology reasoning aims to provide a precise understanding of road scenes, enabling autonomous systems to identify safe and efficient routes. In this paper, we present RoadPainter, an innovative approach for detecting and reasoning the topology of lane centerlines using multi-view images. The core concept behind RoadPainter is to extract a set of points from each centerline mask to improve the accuracy of centerline prediction. We start by implementing a transformer decoder that integrates a hybrid attention mechanism and a real-virtual separation strategy to predict coarse lane centerlines and establish topological associations. Then, we generate centerline instance masks guided by the centerline points from the transformer decoder. Moreover, we derive an additional set of points from each mask and combine them with previously detected centerline points for further refinement. Additionally, we introduce an optional module that incorporates a Standard Definition (SD) map to further optimize centerline detection and enhance topological reasoning performance. Experimental evaluations on the OpenLane-V2 dataset demonstrate the state-of-the-art performance of RoadPainter.
Read more7/23/2024

0
New!TopoMaskV2: Enhanced Instance-Mask-Based Formulation for the Road Topology Problem
M. Esat Kalfaoglu, Halil Ibrahim Ozturk, Ozsel Kilinc, Alptekin Temizel
Recently, the centerline has become a popular representation of lanes due to its advantages in solving the road topology problem. To enhance centerline prediction, we have developed a new approach called TopoMask. Unlike previous methods that rely on keypoints or parametric methods, TopoMask utilizes an instance-mask-based formulation coupled with a masked-attention-based transformer architecture. We introduce a quad-direction label representation to enrich the mask instances with flow information and design a corresponding post-processing technique for mask-to-centerline conversion. Additionally, we demonstrate that the instance-mask formulation provides complementary information to parametric Bezier regressions, and fusing both outputs leads to improved detection and topology performance. Moreover, we analyze the shortcomings of the pillar assumption in the Lift Splat technique and adapt a multi-height bin configuration. Experimental results show that TopoMask achieves state-of-the-art performance in the OpenLane-V2 dataset, increasing from 44.1 to 49.4 for Subset-A and 44.7 to 51.8 for Subset-B in the V1.1 OLS baseline.
Read more9/18/2024

0
Enhancing 3D Lane Detection and Topology Reasoning with 2D Lane Priors
Han Li, Zehao Huang, Zitian Wang, Wenge Rong, Naiyan Wang, Si Liu
3D lane detection and topology reasoning are essential tasks in autonomous driving scenarios, requiring not only detecting the accurate 3D coordinates on lane lines, but also reasoning the relationship between lanes and traffic elements. Current vision-based methods, whether explicitly constructing BEV features or not, all establish the lane anchors/queries in 3D space while ignoring the 2D lane priors. In this study, we propose Topo2D, a novel framework based on Transformer, leveraging 2D lane instances to initialize 3D queries and 3D positional embeddings. Furthermore, we explicitly incorporate 2D lane features into the recognition of topology relationships among lane centerlines and between lane centerlines and traffic elements. Topo2D achieves 44.5% OLS on multi-view topology reasoning benchmark OpenLane-V2 and 62.6% F-Socre on single-view 3D lane detection benchmark OpenLane, exceeding the performance of existing state-of-the-art methods.
Read more6/6/2024

0
Learning Lane Graphs from Aerial Imagery Using Transformers
Martin Buchner, Simon Dorer, Abhinav Valada
The robust and safe operation of automated vehicles underscores the critical need for detailed and accurate topological maps. At the heart of this requirement is the construction of lane graphs, which provide essential information on lane connectivity, vital for navigating complex urban environments autonomously. While transformer-based models have been effective in creating map topologies from vehicle-mounted sensor data, their potential for generating such graphs from aerial imagery remains untapped. This work introduces a novel approach to generating successor lane graphs from aerial imagery, utilizing the advanced capabilities of transformer models. We frame successor lane graphs as a collection of maximal length paths and predict them using a Detection Transformer (DETR) architecture. We demonstrate the efficacy of our method through extensive experiments on the diverse and large-scale UrbanLaneGraph dataset, illustrating its accuracy in generating successor lane graphs and highlighting its potential for enhancing autonomous vehicle navigation in complex environments.
Read more7/9/2024