Learning Lane Graphs from Aerial Imagery Using Transformers

0

Sign in to get full access
Overview
- This paper proposes a novel approach for learning lane graphs from aerial imagery using transformer models.
- The proposed method leverages the Structure-Aware Lane Graph Transformer Model and Transfer Learning Study of Motion Transformer-based Trajectory to extract and represent lane information from overhead images.
- The research also explores how NLP-Enabled Trajectory-Map Matching in Urban Road and VT-Former: An Exploratory Study of Vehicle Trajectory Prediction techniques can be applied to improve lane graph extraction and representation.
- The proposed LaneSegNet model is designed to identify and segment lane markings from aerial imagery, which are then used to construct the final lane graph.
Plain English Explanation
This paper presents a new way to extract information about road lanes from overhead aerial images using a type of machine learning model called a transformer. The key idea is to use the transformer architecture, which has been successful in tasks like natural language processing, to analyze the spatial and contextual relationships in aerial imagery and build a graph-based representation of the road lanes.
The researchers leveraged several existing techniques to develop their approach. They used a "structure-aware" transformer model to capture the inherent structure of road networks, and applied transfer learning from models trained on vehicle trajectory data to improve the lane graph extraction. They also incorporated natural language processing methods to help match the extracted lane information with map data.
The final model, called LaneSegNet, is designed to identify and segment the actual lane markings visible in the aerial images. This lane segmentation information is then used to construct a complete graph-level representation of the road network, which could be useful for applications like autonomous driving, traffic monitoring, and urban planning.
The key innovation here is applying powerful transformer models, which have revolutionized fields like language and speech, to the problem of extracting detailed road network information from aerial imagery. This allows the model to learn complex spatial relationships and contextual cues that would be difficult to capture with more traditional computer vision techniques.
Technical Explanation
The core of the proposed approach is the LaneSegNet model, which is built upon a transformer architecture to learn lane representations from aerial imagery. The transformer model is well-suited for this task as it can effectively capture the inherent structure and spatial relationships present in road networks.
The LaneSegNet architecture consists of a series of transformer encoder and decoder layers that operate on visual features extracted from the input aerial images. The encoder layers learn contextual embeddings that encode the spatial and semantic information about the lane markings, while the decoder layers progressively refine this representation to produce the final lane segmentation.
To enhance the model's performance, the researchers leverage several complementary techniques:
-
Structure-Aware Lane Graph Transformer: This module incorporates a graph neural network component to explicitly model the structural properties of the road network, such as lane connectivity and topology. This helps the model better understand the overall lane configuration.
-
Transfer Learning from Trajectory Data: The researchers fine-tune the transformer model using datasets of vehicle trajectory data, which captures dynamic information about how vehicles move through the road network. This transfer learning approach improves the model's ability to reason about lane-level details.
-
NLP-Enabled Trajectory-Map Matching: The researchers explore applying natural language processing techniques to align the extracted lane information with existing map data. This helps to further enrich the lane graph representation and make it more consistent with real-world road networks.
The key experimental results show that the proposed LaneSegNet model is able to accurately segment lane markings from aerial images and construct comprehensive lane graphs. The incorporation of the various transformer-based techniques leads to significant performance improvements compared to baseline computer vision approaches.
Critical Analysis
The paper presents a thoughtful and well-designed approach for learning lane graphs from aerial imagery using transformer models. The researchers have leveraged several state-of-the-art techniques in a coherent manner to tackle this challenging computer vision problem.
One potential limitation of the study is the reliance on relatively small-scale datasets for training and evaluation. While the results demonstrate the effectiveness of the proposed approach, it would be valuable to see how the model performs on larger, more diverse aerial imagery datasets that capture a wider range of road network complexities and environmental conditions.
Additionally, the paper does not provide a detailed analysis of the computational efficiency and real-time inference capabilities of the LaneSegNet model. Given the intended applications in autonomous driving and traffic monitoring, understanding the model's deployment feasibility would be an important consideration.
Another area for potential future research could be exploring the integration of the lane graph representations learned by LaneSegNet with other road network modeling techniques, such as those based on semantic segmentation or instance segmentation. Combining complementary approaches could lead to even more robust and comprehensive representations of the road infrastructure.
Overall, the paper presents a compelling and innovative use of transformer models for the challenging problem of lane graph extraction from aerial imagery. The proposed approach offers promising directions for further research and development in this rapidly evolving field.
Conclusion
This paper introduces a novel transformer-based model, LaneSegNet, for learning detailed lane graph representations from aerial imagery. The key innovation is the application of transformer architectures, which have revolutionized fields like natural language processing, to the problem of extracting and modeling road network information from overhead visual data.
The researchers have leveraged a range of complementary techniques, including structure-aware graph modeling, transfer learning from trajectory data, and natural language processing-based map alignment, to enhance the performance of the LaneSegNet model. The resulting lane graphs could be highly valuable for a variety of applications, such as autonomous driving, traffic monitoring, and urban planning.
While the paper demonstrates promising results, there are opportunities for further research to address potential limitations and explore ways to integrate the lane graph representations with other road network modeling approaches. Overall, this work represents an exciting step forward in the application of advanced machine learning techniques to the challenge of understanding and representing transportation infrastructure from aerial imagery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Lane Graphs from Aerial Imagery Using Transformers
Martin Buchner, Simon Dorer, Abhinav Valada
The robust and safe operation of automated vehicles underscores the critical need for detailed and accurate topological maps. At the heart of this requirement is the construction of lane graphs, which provide essential information on lane connectivity, vital for navigating complex urban environments autonomously. While transformer-based models have been effective in creating map topologies from vehicle-mounted sensor data, their potential for generating such graphs from aerial imagery remains untapped. This work introduces a novel approach to generating successor lane graphs from aerial imagery, utilizing the advanced capabilities of transformer models. We frame successor lane graphs as a collection of maximal length paths and predict them using a Detection Transformer (DETR) architecture. We demonstrate the efficacy of our method through extensive experiments on the diverse and large-scale UrbanLaneGraph dataset, illustrating its accuracy in generating successor lane graphs and highlighting its potential for enhancing autonomous vehicle navigation in complex environments.
Read more7/9/2024
0
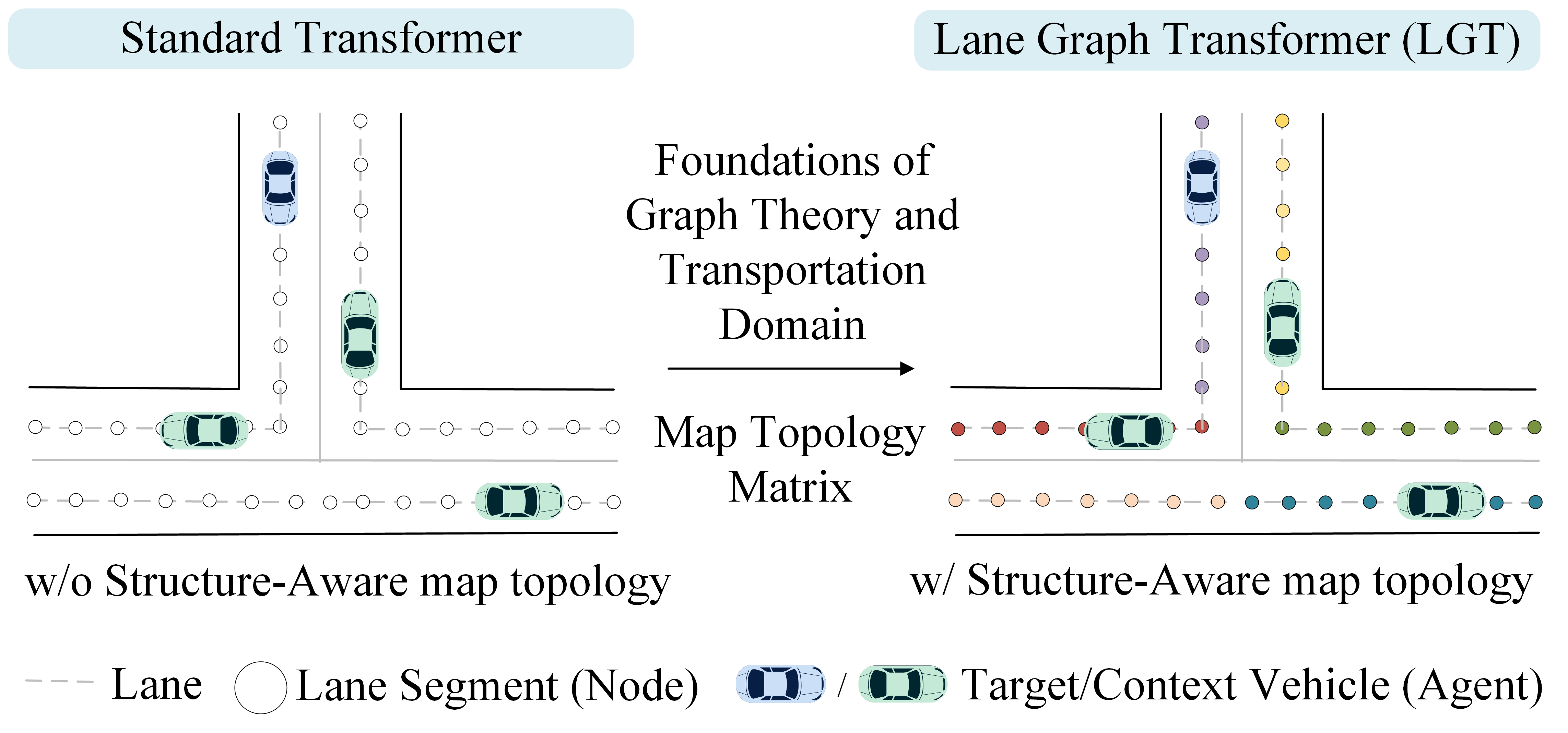
A Structure-Aware Lane Graph Transformer Model for Vehicle Trajectory Prediction
Sun Zhanbo, Dong Caiyin, Ji Ang, Zhao Ruibin, Zhao Yu
Accurate prediction of future trajectories for surrounding vehicles is vital for the safe operation of autonomous vehicles. This study proposes a Lane Graph Transformer (LGT) model with structure-aware capabilities. Its key contribution lies in encoding the map topology structure into the attention mechanism. To address variations in lane information from different directions, four Relative Positional Encoding (RPE) matrices are introduced to capture the local details of the map topology structure. Additionally, two Shortest Path Distance (SPD) matrices are employed to capture distance information between two accessible lanes. Numerical results indicate that the proposed LGT model achieves a significantly higher prediction performance on the Argoverse 2 dataset. Specifically, the minFDE$_6$ metric was decreased by 60.73% compared to the Argoverse 2 baseline model (Nearest Neighbor) and the b-minFDE$_6$ metric was reduced by 2.65% compared to the baseline LaneGCN model. Furthermore, ablation experiments demonstrated that the consideration of map topology structure led to a 4.24% drop in the b-minFDE$_6$ metric, validating the effectiveness of this model.
Read more5/31/2024
0
Transfer Learning Study of Motion Transformer-based Trajectory Predictions
Lars Ullrich, Alex McMaster, Knut Graichen
Trajectory planning in autonomous driving is highly dependent on predicting the emergent behavior of other road users. Learning-based methods are currently showing impressive results in simulation-based challenges, with transformer-based architectures technologically leading the way. Ultimately, however, predictions are needed in the real world. In addition to the shifts from simulation to the real world, many vehicle- and country-specific shifts, i.e. differences in sensor systems, fusion and perception algorithms as well as traffic rules and laws, are on the agenda. Since models that can cover all system setups and design domains at once are not yet foreseeable, model adaptation plays a central role. Therefore, a simulation-based study on transfer learning techniques is conducted on basis of a transformer-based model. Furthermore, the study aims to provide insights into possible trade-offs between computational time and performance to support effective transfers into the real world.
Read more8/9/2024
0
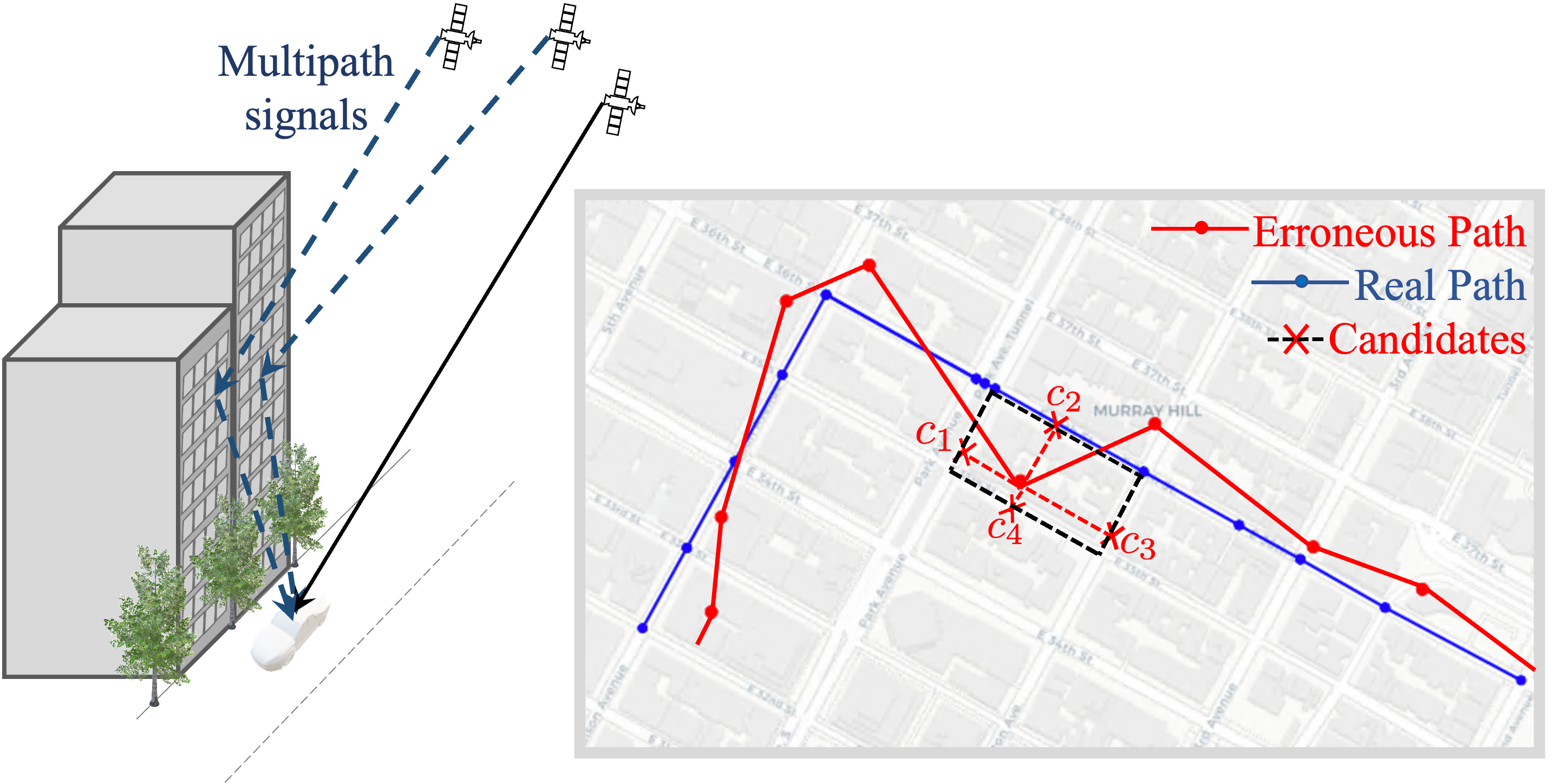
NLP-enabled trajectory map-matching in urban road networks using transformer sequence-to-sequence model
Sevin Mohammadi, Andrew W. Smyth
Large-scale geolocation telematics data acquired from connected vehicles has the potential to significantly enhance mobility infrastructures and operational systems within smart cities. To effectively utilize this data, it is essential to accurately match the geolocation data to the road segments. However, this matching is often not trivial due to the low sampling rate and errors exacerbated by multipath effects in urban environments. Traditionally, statistical modeling techniques such as Hidden-Markov models incorporating domain knowledge into the matching process have been extensively used for map-matching tasks. However, rule-based map-matching tasks are noise-sensitive and inefficient in processing large-scale trajectory data. Deep learning techniques directly learn the relationship between observed data and road networks from the data, often without the need for hand-crafted rules or domain knowledge. This renders them an efficient approach for map-matching large-scale datasets and makes them more robust to the noise. This paper introduces a sequence-to-sequence deep-learning model, specifically the transformer-based encoder-decoder model, to perform as a surrogate for map-matching algorithms. The encoder-decoder architecture initially encodes the series of noisy GPS points into a representation that automatically captures autoregressive behavior and spatial correlations between GPS points. Subsequently, the decoder associates data points with the road network features and thus transforms these representations into a sequence of road segments. The model is trained and evaluated using GPS traces collected in Manhattan, New York. Achieving an accuracy of 76%, transformer-based encoder-decoder models extensively employed in natural language processing presented a promising performance for translating noisy GPS data to the navigated routes in urban road networks.
Read more4/22/2024