Robo-Instruct: Simulator-Augmented Instruction Alignment For Finetuning CodeLLMs
2405.20179
0
0

Abstract
Large language models (LLMs) have shown great promise at generating robot programs from natural language given domain-specific robot application programming interfaces (APIs). However, the performance gap between proprietary LLMs and smaller open-weight LLMs remains wide. This raises a question: Can we fine-tune smaller open-weight LLMs for generating domain-specific robot programs to close the performance gap with proprietary LLMs? While Self-Instruct is a promising solution by generating a diverse set of training data, it cannot verify the correctness of these programs. In contrast, a robot simulator with a well-defined world can identify execution errors but limits the diversity of programs that it can verify. In this work, we introduce Robo-Instruct, which brings the best of both worlds -- it promotes the diversity of Self-Instruct while providing the correctness of simulator-based checking. Robo-Instruct introduces RoboSim to synthesize a consistent world state on the fly by inferring properties relevant to the program being checked, and simulating actions accordingly. Furthermore, the instructions and programs generated by Self-Instruct may be subtly inconsistent -- such as the program missing a step implied by the instruction. Robo-Instruct further addresses this with InstAlign, an instruction-program alignment procedure that revises the task instruction to reflect the actual results of the generated program. Given a few seed task descriptions and the robot APIs, Robo-Instruct is capable of generating a training dataset using only a small open-weight model. This dataset can then be used to fine-tune small open-weight language models, enabling them to match or even exceed the performance of several proprietary LLMs, such as GPT-3.5-Turbo and Gemini-Pro.
Create account to get full access
Overview
- This paper introduces "Robo-Instruct", a system that uses a simulator-based approach to align large language models (LLMs) with task-specific instructions for fine-tuning code-focused LLMs.
- The key ideas are to generate synthetic instruction-following demonstrations using a simulator, and then use these demonstrations to fine-tune the LLM to better follow natural language instructions.
- This approach aims to improve the performance of code-focused LLMs on tasks that require following complex, open-ended instructions.
Plain English Explanation
In this paper, the researchers present a new technique called "Robo-Instruct" to help train large language models (LLMs) to better understand and follow natural language instructions, especially when it comes to coding and programming tasks.
The core idea is to use a simulator to generate synthetic demonstrations of following instructions. For example, the simulator could create examples of a virtual robot carrying out step-by-step instructions to complete a task. The researchers then use these simulated demonstrations to fine-tune the LLM, helping it learn how to interpret and execute open-ended instructions more effectively.
This is important because many real-world tasks that we want to use LLMs for, like coding or operating complex systems, require following detailed instructions in natural language. By fine-tuning the LLM on instruction-following examples from the simulator, the researchers hope to make the model better at understanding and carrying out these types of instructions.
The key benefit of this approach is that it allows the LLM to learn instruction-following skills in a safe, controlled simulation environment, before applying those skills to the real world. This could lead to more capable and reliable LLMs for a variety of applications that involve following complex instructions.
Technical Explanation
The Robo-Instruct system works by first generating synthetic instruction-following demonstrations using a simulator. This simulator can create examples of a virtual agent or "robot" carrying out step-by-step instructions to complete various tasks, like writing code or manipulating objects.
The researchers then use these simulated demonstrations to fine-tune a pre-trained code-focused LLM, like CodeLLM. The fine-tuning process aligns the LLM to better understand and execute the types of natural language instructions present in the synthetic demonstrations.
This approach builds on prior work in areas like learning reward models for robot skills, self-alignment of instructable reward models, and domain-specific fine-tuning of LLMs. The key innovation in Robo-Instruct is the use of a simulator to generate high-quality, task-specific instruction-following demonstrations that can then be used to fine-tune the LLM.
Through experiments, the researchers demonstrate that this simulator-augmented fine-tuning approach can significantly improve the performance of code-focused LLMs on tasks that require following complex, open-ended natural language instructions, compared to standard fine-tuning techniques.
Critical Analysis
The Robo-Instruct approach presents a promising direction for improving the instruction-following capabilities of LLMs, but there are a few potential limitations and areas for further research:
-
Simulator Fidelity: The effectiveness of the approach relies on the simulator's ability to generate high-quality, realistic demonstrations of instruction-following. If the simulated examples do not accurately reflect real-world instruction-following behavior, the fine-tuning process may not transfer well to the actual task.
-
Generalization: While the fine-tuned LLM may perform better on the specific types of instructions used in the simulator, it's unclear how well the model would generalize to novel, unseen instructions. Further research is needed to assess the model's ability to transfer its instruction-following skills to new domains.
-
Safety and Robustness: When applying LLMs to safety-critical, real-world applications like robotics or critical infrastructure, it's important to ensure the models are safe, reliable, and robust to edge cases. The paper does not discuss potential safety and robustness considerations in depth.
-
Scalability: Generating high-quality synthetic demonstrations for a wide range of tasks and instructions may be computationally expensive and time-consuming. Scalability could be a challenge, especially for organizations with limited resources.
Despite these potential limitations, the Robo-Instruct approach represents an important step towards developing more capable and trustworthy LLMs for applications that involve following complex, open-ended instructions. Further research in this direction could lead to significant advancements in the field of language-guided autonomy and human-AI collaboration.
Conclusion
The Robo-Instruct paper introduces a novel technique for fine-tuning code-focused LLMs to better understand and execute natural language instructions. By leveraging a simulator to generate synthetic instruction-following demonstrations, the researchers have developed a way to align LLMs with task-specific instruction-following skills in a controlled, safe environment.
This work has the potential to improve the performance of LLMs on a variety of real-world applications that require following complex, open-ended instructions, such as coding, robotics, and the operation of complex systems. While there are still some challenges to address, the Robo-Instruct approach represents an exciting step forward in the development of more capable and trustworthy language models for instruction-following tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
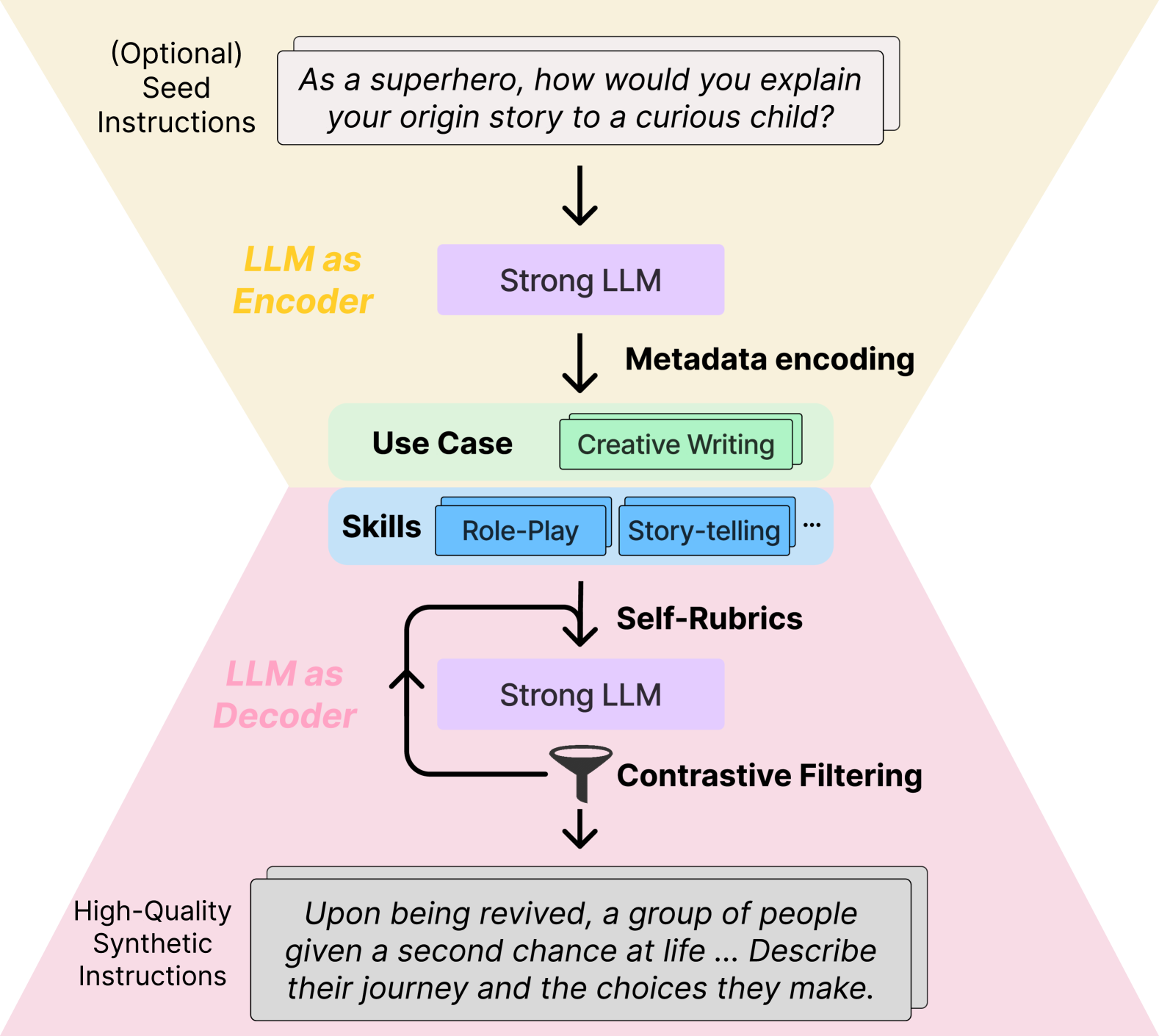
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
0
0
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
4/10/2024

Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
0
0
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
6/17/2024

Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models
Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, Jingren Zhou
0
0
One core capability of large language models (LLMs) is to follow natural language instructions. However, the issue of automatically constructing high-quality training data to enhance the complex instruction-following abilities of LLMs without manual annotation remains unresolved. In this paper, we introduce AutoIF, the first scalable and reliable method for automatically generating instruction-following training data. AutoIF transforms the validation of instruction-following data quality into code verification, requiring LLMs to generate instructions, the corresponding code to check the correctness of the instruction responses, and unit test samples to verify the code's correctness. Then, execution feedback-based rejection sampling can generate data for Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) training. AutoIF achieves significant improvements across three training algorithms, SFT, Offline DPO, and Online DPO, when applied to the top open-source LLMs, Qwen2 and LLaMA3, in self-alignment and strong-to-weak distillation settings. Our code is publicly available at https://github.com/QwenLM/AutoIF.
6/21/2024
💬
Learning Reward for Robot Skills Using Large Language Models via Self-Alignment
Yuwei Zeng, Yao Mu, Lin Shao
0
0
Learning reward functions remains the bottleneck to equip a robot with a broad repertoire of skills. Large Language Models (LLM) contain valuable task-related knowledge that can potentially aid in the learning of reward functions. However, the proposed reward function can be imprecise, thus ineffective which requires to be further grounded with environment information. We proposed a method to learn rewards more efficiently in the absence of humans. Our approach consists of two components: We first use the LLM to propose features and parameterization of the reward, then update the parameters through an iterative self-alignment process. In particular, the process minimizes the ranking inconsistency between the LLM and the learnt reward functions based on the execution feedback. The method was validated on 9 tasks across 2 simulation environments. It demonstrates a consistent improvement over training efficacy and efficiency, meanwhile consuming significantly fewer GPT tokens compared to the alternative mutation-based method.
5/17/2024