SALMON: Self-Alignment with Instructable Reward Models
2310.05910
0
0
⛏️
Abstract
Supervised Fine-Tuning (SFT) on response demonstrations combined with Reinforcement Learning from Human Feedback (RLHF) constitutes a powerful paradigm for aligning LLM-based AI agents. However, a significant limitation of such an approach is its dependency on high-quality human annotations, making its application to intricate tasks challenging due to difficulties in obtaining consistent response demonstrations and in-distribution response preferences. This paper presents a novel approach, namely SALMON, to align base language models with minimal human supervision, using only a small set of human-defined principles, yet achieving superior performance. Central to our approach is an instructable reward model. Trained on synthetic preference data, this model can generate reward scores based on arbitrary human-defined principles. By merely adjusting these principles during the RL training phase, we gain full control over the preferences with the instructable reward model, subsequently influencing the behavior of the RL-trained policy models, and reducing the reliance on the collection of online human preferences. Applying our method to the LLaMA-2-70b base language model, we developed an AI assistant named Dromedary-2. With only 6 exemplars for in-context learning and 31 human-defined principles, Dromedary-2 significantly surpasses the performance of several state-of-the-art AI systems, including LLaMA-2-Chat-70b, on various benchmark datasets. We have open-sourced the code and model weights to encourage further research into aligning LLM-based AI agents with enhanced supervision efficiency, improved controllability, and scalable oversight.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach called SALMON to align base language models with minimal human supervision.
- SALMON uses a small set of human-defined principles to train an instructable reward model, which can then be used to guide the reinforcement learning (RL) training of policy models.
- This approach reduces the reliance on collecting high-quality human annotations and in-distribution response preferences, which are often challenging to obtain for complex tasks.
- The authors apply SALMON to the LLaMA-2-70b base language model and develop an AI assistant named Dromedary-2, which significantly outperforms several state-of-the-art AI systems on various benchmark datasets.
Plain English Explanation
The paper introduces a new way to train AI language models to behave in alignment with human values and preferences. Traditionally, this has been done by having humans provide a lot of detailed feedback and examples of desired responses (Supervised Fine-Tuning (SFT) on response demonstrations combined with Reinforcement Learning from Human Feedback (RLHF)). However, this can be challenging, as it's hard to get consistent and comprehensive feedback from humans, especially for complex tasks.
The key innovation in this paper is the SALMON approach, which uses a small set of high-level human-defined principles to train a "reward model." This reward model can then be used to guide the reinforcement learning (RL) process, teaching the AI assistant to behave according to those principles. This reduces the need for extensive human feedback, making the alignment process more efficient and scalable.
The authors apply SALMON to the LLaMA-2-70b language model, creating an AI assistant called Dromedary-2. With just 6 examples for context and 31 human-defined principles, Dromedary-2 outperforms several other state-of-the-art AI systems on various benchmarks. This demonstrates the power of the SALMON approach in aligning AI agents with human values and preferences using minimal supervision.
Technical Explanation
The key elements of the SALMON approach are:
-
Instructable Reward Model: The authors train a reward model on synthetic preference data, which can generate reward scores based on arbitrary human-defined principles. This allows them to have full control over the preferences that will guide the RL training.
-
RL Training with Instructable Reward: During the RL training phase, the authors can adjust the human-defined principles, and the instructable reward model will generate the corresponding rewards to shape the behavior of the policy models.
-
Application to LLaMA-2-70b: The authors apply the SALMON approach to the LLaMA-2-70b base language model, creating an AI assistant called Dromedary-2. They use only 6 exemplars for in-context learning and 31 human-defined principles to train Dromedary-2.
-
Benchmark Evaluation: Dromedary-2 is evaluated on various benchmark datasets and is shown to significantly outperform several state-of-the-art AI systems, including LLaMA-2-Chat-70b.
The key insight behind SALMON is that by using an instructable reward model, the authors can reduce the reliance on collecting high-quality human annotations and in-distribution response preferences, which are often challenging to obtain, especially for complex tasks. This allows for more efficient and scalable alignment of language models with human values and preferences.
Critical Analysis
The SALMON approach presented in this paper is a promising step towards more efficient and controllable alignment of large language models with human values. However, there are a few potential limitations and areas for further research:
-
Generalization of Principles: The authors demonstrate the effectiveness of SALMON using a specific set of 31 human-defined principles. It would be interesting to see how well the approach generalizes to a broader or more diverse set of principles, and how the model's performance and behavior might be affected.
-
Robustness to Principle Shifts: The paper does not extensively explore the model's behavior when the human-defined principles are shifted or modified during the RL training phase. It would be valuable to understand the model's sensitivity to such changes and how it might impact the resulting behavior.
-
Interpretability and Transparency: While the instructable reward model provides a way to control the model's preferences, the paper does not delve into the interpretability and transparency of the underlying principles and their influence on the model's decision-making process. Exploring these aspects could be important for building trust and understanding in these AI systems.
-
Scalability and Generalization: The authors demonstrate the effectiveness of SALMON on a specific language model and task. It would be interesting to see how well the approach scales to larger models and more diverse domains, as well as how it compares to other state-of-the-art alignment approaches, such as CodeCLM, FGAIf, and SambaLingo.
Overall, the SALMON approach presents a promising direction for aligning large language models with human values and preferences using minimal supervision. Further research and exploration of the approach's limitations and potential extensions could lead to valuable insights for the field of AI alignment.
Conclusion
The paper introduces a novel approach called SALMON that can align base language models with human values and preferences using a small set of human-defined principles. This approach reduces the reliance on high-quality human annotations and in-distribution response preferences, which are often challenging to obtain, especially for complex tasks.
By applying SALMON to the LLaMA-2-70b base language model, the authors develop an AI assistant named Dromedary-2 that significantly outperforms several state-of-the-art AI systems on various benchmark datasets. This demonstrates the potential of the SALMON approach in creating more efficient and controllable alignment of language models with human values.
While the paper presents a promising solution, there are still areas for further research, such as exploring the generalization of the approach to a broader set of principles, understanding its robustness to principle shifts, and investigating the interpretability and transparency of the underlying decision-making process. Addressing these aspects could lead to valuable insights for the field of AI alignment and the development of more trustworthy and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Aligning language models with human preferences
Tomasz Korbak
0
0
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
4/19/2024
💬
The Real, the Better: Aligning Large Language Models with Online Human Behaviors
Guanying Jiang, Lingyong Yan, Haibo Shi, Dawei Yin
0
0
Large language model alignment is widely used and studied to avoid LLM producing unhelpful and harmful responses. However, the lengthy training process and predefined preference bias hinder adaptation to online diverse human preferences. To this end, this paper proposes an alignment framework, called Reinforcement Learning with Human Behavior (RLHB), to align LLMs by directly leveraging real online human behaviors. By taking the generative adversarial framework, the generator is trained to respond following expected human behavior; while the discriminator tries to verify whether the triplets of query, response, and human behavior come from real online environments. Behavior modeling in natural-language form and the multi-model joint training mechanism enable an active and sustainable online alignment. Experimental results confirm the effectiveness of our proposed methods by both human and automatic evaluations.
5/2/2024
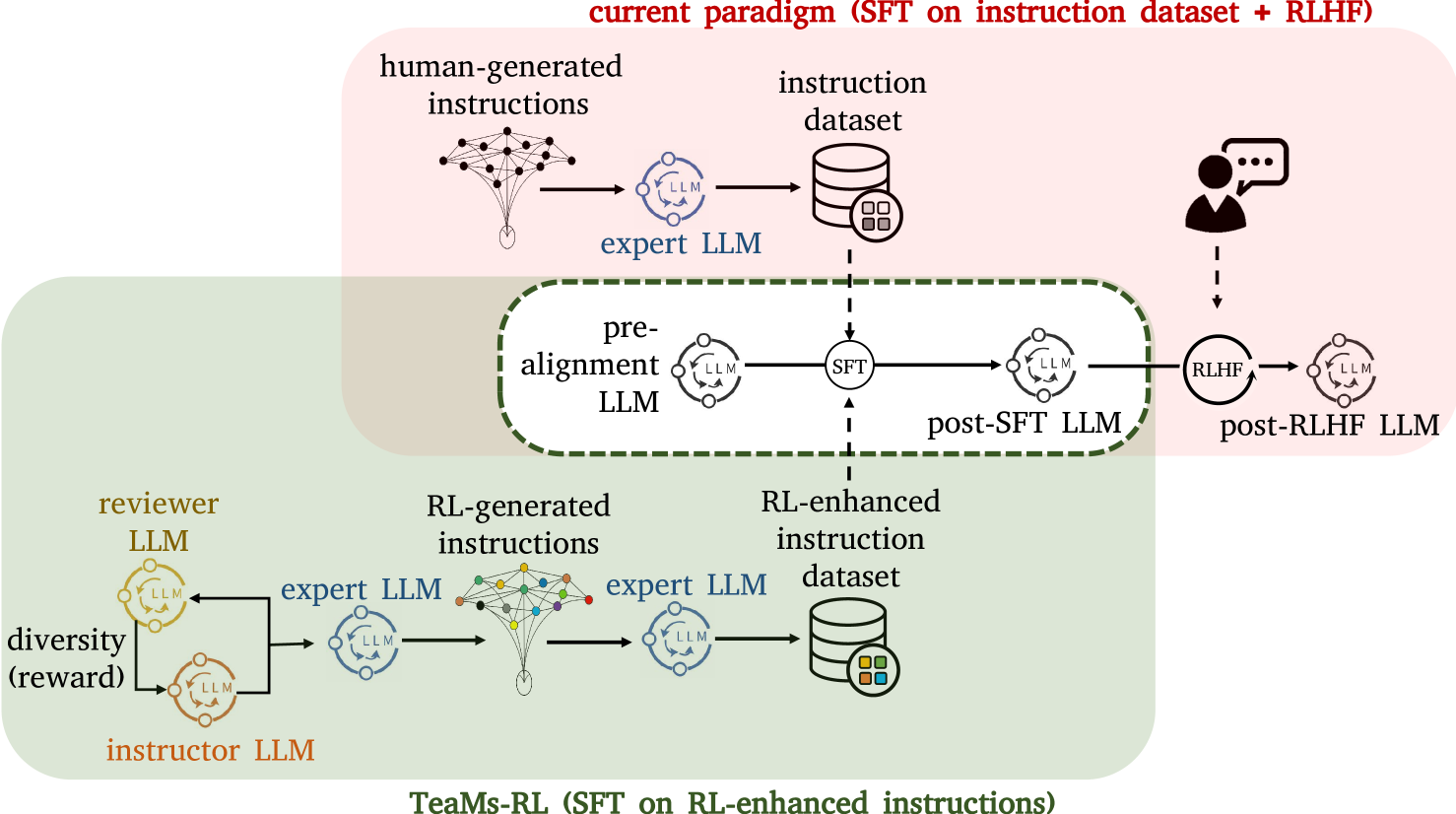
TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning
Shangding Gu, Alois Knoll, Ming Jin
0
0
The development of Large Language Models (LLMs) often confronts challenges stemming from the heavy reliance on human annotators in the reinforcement learning with human feedback (RLHF) framework, or the frequent and costly external queries tied to the self-instruct paradigm. In this work, we pivot to Reinforcement Learning (RL) -- but with a twist. Diverging from the typical RLHF, which refines LLMs following instruction data training, we use RL to directly generate the foundational instruction dataset that alone suffices for fine-tuning. Our method, TeaMs-RL, uses a suite of textual operations and rules, prioritizing the diversification of training datasets. It facilitates the generation of high-quality data without excessive reliance on external advanced models, paving the way for a single fine-tuning step and negating the need for subsequent RLHF stages. Our findings highlight key advantages of our approach: reduced need for human involvement and fewer model queries (only $5.73%$ of WizardLM's total), along with enhanced capabilities of LLMs in crafting and comprehending complex instructions compared to strong baselines, and substantially improved model privacy protection.
5/7/2024
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Songyang Gao, Qiming Ge, Wei Shen, Shihan Dou, Junjie Ye, Xiao Wang, Rui Zheng, Yicheng Zou, Zhi Chen, Hang Yan, Qi Zhang, Dahua Lin
0
0
The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset is published on url{https://github.com/Wizardcoast/Linear_Alignment.git}.
5/7/2024