Towards Robust Instruction Tuning on Multimodal Large Language Models
2402.14492
0
0

Abstract
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
Create account to get full access
Overview
- This paper introduces InstrAug, a technique for automatically augmenting instructions to improve the performance of large language models on multimodal instruction-following tasks.
- The key idea is to generate new instructions by paraphrasing or perturbing existing ones, which can then be used to fine-tune the language model and enhance its understanding of instructions.
- The authors demonstrate the effectiveness of InstrAug on several benchmark datasets, showing that it outperforms previous instruction fine-tuning approaches.
Plain English Explanation
The paper proposes a new method called InstrAug to help language models better understand and follow instructions. Language models are large AI systems that can process and generate human language, but they can struggle with tasks that require following specific instructions, like explaining a complex process or translating between languages.
The key idea behind InstrAug is to automatically generate new instructions by making small changes to existing ones. For example, the instruction "Bake the cake for 30 minutes at 350 degrees Fahrenheit" could be paraphrased as "Cook the cake for half an hour at a temperature of 350 degrees." These new instructions can then be used to fine-tune the language model, helping it learn to better understand and follow a wider variety of instructions.
The authors show that this approach, which builds on prior work in textual data augmentation, leads to significant performance improvements on several benchmark datasets that involve following instructions, compared to previous fine-tuning methods. This suggests that InstrAug could be a valuable tool for helping language models become more capable at a wide range of instruction-following tasks.
Technical Explanation
The paper introduces a new technique called InstrAug for automatically augmenting instructions to improve the performance of large language models on multimodal instruction-following tasks. The key idea is to generate new instructions by paraphrasing or perturbing existing ones, which can then be used to fine-tune the language model and enhance its understanding of instructions.
The authors propose several instruction augmentation techniques, including:
- Paraphrasing: Generating new instructions that convey the same meaning using different wording.
- Lexical substitution: Replacing words in the instructions with synonyms or related terms.
- Structural perturbation: Changing the syntactic structure of the instructions, such as reordering or adding/removing phrases.
These augmented instructions are then used to fine-tune a pre-trained language model, such as GPT-3, using an instruction-following loss function that encourages the model to accurately follow the instructions.
The authors evaluate InstrAug on several benchmark datasets that involve multimodal instruction-following tasks, such as COOK and LEGO. They show that InstrAug outperforms previous instruction fine-tuning approaches, demonstrating the effectiveness of their automatic instruction augmentation technique.
Critical Analysis
The paper provides a novel and promising approach to improving the instruction-following capabilities of large language models. By automatically generating diverse instructions through paraphrasing and perturbation, the authors are able to effectively fine-tune the models and enhance their performance on a range of multimodal tasks.
However, the paper does not address some potential limitations and areas for further research:
- Generalization: While the authors demonstrate the effectiveness of InstrAug on several benchmark datasets, it's unclear how well the approach would generalize to real-world instruction-following tasks, which may involve more complex and varied instructions.
- Scalability: The paper does not discuss the computational and resource requirements of the instruction augmentation process, which could be a limiting factor in applying the technique at scale.
- Ethical Considerations: The paper does not explore potential ethical concerns, such as the use of language models for generating instructions that could be harmful or misleading.
Further research could address these limitations and explore ways to make InstrAug more robust, scalable, and ethically-aligned.
Conclusion
This paper introduces a novel technique called InstrAug for automatically augmenting instructions to improve the performance of large language models on multimodal instruction-following tasks. By generating diverse instructions through paraphrasing and perturbation, the authors are able to effectively fine-tune language models and enhance their understanding of instructions.
The results demonstrate the effectiveness of InstrAug, which outperforms previous instruction fine-tuning approaches on several benchmark datasets. This suggests that InstrAug could be a valuable tool for helping language models become more capable at a wide range of instruction-following tasks, with potential applications in areas like education, task planning, and human-AI collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Hieu Tran, Zhichao Yang, Zonghai Yao, Hong Yu
0
0
To enhance the performance of large language models (LLMs) in biomedical natural language processing (BioNLP) by introducing a domain-specific instruction dataset and examining its impact when combined with multi-task learning principles. We created the BioInstruct, comprising 25,005 instructions to instruction-tune LLMs(LLaMA 1 & 2, 7B & 13B version). The instructions were created by prompting the GPT-4 language model with three-seed samples randomly drawn from an 80 human curated instructions. We employed Low-Rank Adaptation(LoRA) for parameter-efficient fine-tuning. We then evaluated these instruction-tuned LLMs on several BioNLP tasks, which can be grouped into three major categories: question answering(QA), information extraction(IE), and text generation(GEN). We also examined whether categories(e.g., QA, IE, and generation) of instructions impact model performance. Comparing with LLMs without instruction-tuned, our instruction-tuned LLMs demonstrated marked performance gains: 17.3% in QA, 5.7% in IE, and 96% in Generation tasks. Our 7B-parameter instruction-tuned LLaMA 1 model was competitive or even surpassed other LLMs in the biomedical domain that were also fine-tuned from LLaMA 1 with vast domain-specific data or a variety of tasks. Our results also show that the performance gain is significantly higher when instruction fine-tuning is conducted with closely related tasks. Our findings align with the observations of multi-task learning, suggesting the synergies between two tasks. The BioInstruct dataset serves as a valuable resource and instruction tuned LLMs lead to the best performing BioNLP applications.
6/10/2024

New!MM-Instruct: Generated Visual Instructions for Large Multimodal Model Alignment
Jihao Liu, Xin Huang, Jinliang Zheng, Boxiao Liu, Jia Wang, Osamu Yoshie, Yu Liu, Hongsheng Li
0
0
This paper introduces MM-Instruct, a large-scale dataset of diverse and high-quality visual instruction data designed to enhance the instruction-following capabilities of large multimodal models (LMMs). While existing visual instruction datasets often focus on question-answering, they struggle to generalize to broader application scenarios such as creative writing, summarization, or image analysis. To address these limitations, we propose a novel approach to constructing MM-Instruct that leverages the strong instruction-following capabilities of existing LLMs to generate novel visual instruction data from large-scale but conventional image captioning datasets. MM-Instruct first leverages ChatGPT to automatically generate diverse instructions from a small set of seed instructions through augmenting and summarization. It then matches these instructions with images and uses an open-sourced large language model (LLM) to generate coherent answers to the instruction-image pairs. The LLM is grounded by the detailed text descriptions of images in the whole answer generation process to guarantee the alignment of the instruction data. Moreover, we introduce a benchmark based on the generated instruction data to evaluate the instruction-following capabilities of existing LMMs. We demonstrate the effectiveness of MM-Instruct by training a LLaVA-1.5 model on the generated data, denoted as LLaVA-Instruct, which exhibits significant improvements in instruction-following capabilities compared to LLaVA-1.5 models. The MM-Instruct dataset, benchmark, and pre-trained models are available at https://github.com/jihaonew/MM-Instruct.
7/1/2024
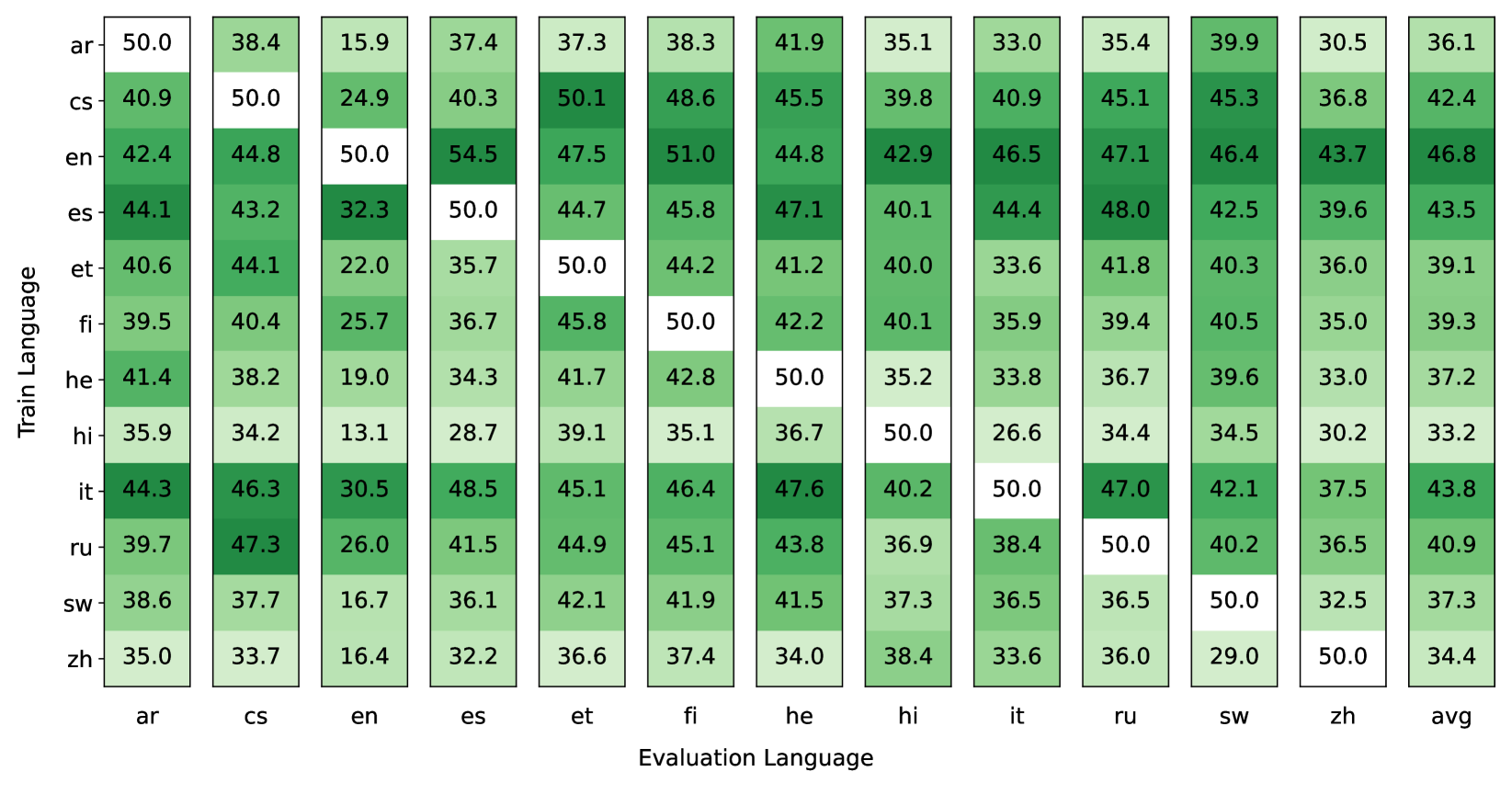
Multilingual Instruction Tuning With Just a Pinch of Multilinguality
Uri Shaham, Jonathan Herzig, Roee Aharoni, Idan Szpektor, Reut Tsarfaty, Matan Eyal
0
0
As instruction-tuned large language models (LLMs) gain global adoption, their ability to follow instructions in multiple languages becomes increasingly crucial. In this work, we investigate how multilinguality during instruction tuning of a multilingual LLM affects instruction-following across languages from the pre-training corpus. We first show that many languages transfer some instruction-following capabilities to other languages from even monolingual tuning. Furthermore, we find that only 40 multilingual examples integrated in an English tuning set substantially improve multilingual instruction-following, both in seen and unseen languages during tuning. In general, we observe that models tuned on multilingual mixtures exhibit comparable or superior performance in multiple languages compared to monolingually tuned models, despite training on 10x fewer examples in those languages. Finally, we find that diversifying the instruction tuning set with even just 2-4 languages significantly improves cross-lingual generalization. Our results suggest that building massively multilingual instruction-tuned models can be done with only a very small set of multilingual instruction-responses.
5/22/2024
✅
Instruction Tuning With Loss Over Instructions
Zhengyan Shi, Adam X. Yang, Bin Wu, Laurence Aitchison, Emine Yilmaz, Aldo Lipani
0
0
Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which trains LMs by applying a loss function to the instruction and prompt part rather than solely to the output part. Through experiments across 21 diverse benchmarks, we show that, in many scenarios, IM can effectively improve the LM performance on both NLP tasks (e.g., MMLU, TruthfulQA, and HumanEval) and open-ended generation benchmarks (e.g., MT-Bench and AlpacaEval). Remarkably, in the most advantageous case, IM boosts model performance on AlpacaEval 1.0 by over 100%. We identify two key factors influencing the effectiveness of IM: (1) The ratio between instruction length and output length in the training data; and (2) The number of training examples. We observe that IM is especially beneficial when trained on datasets with lengthy instructions paired with brief outputs, or under the Superficial Alignment Hypothesis (SAH) where a small amount of training examples are used for instruction tuning. Further analysis substantiates our hypothesis that the improvement can be attributed to reduced overfitting to instruction tuning datasets. Our work provides practical guidance for instruction tuning LMs, especially in low-resource scenarios.
5/24/2024