Robust Audiovisual Speech Recognition Models with Mixture-of-Experts

0

Sign in to get full access
Overview
- Presents a robust audiovisual speech recognition model using a mixture-of-experts architecture
- Aims to improve speech recognition performance in noisy environments by combining audio and visual modalities
- Experiments show the proposed model outperforms unimodal and other multimodal approaches on multiple speech recognition benchmarks
Plain English Explanation
This research paper introduces a new approach to improving speech recognition, which is the task of converting spoken language into text. The key idea is to combine audio (sound) and visual (lip movement) information to create a more robust and accurate speech recognition system, especially in noisy environments where audio alone may be unreliable.
The researchers use a mixture-of-experts architecture, which means the model has multiple "expert" components that specialize in different aspects of the speech recognition problem. These experts work together to produce the final output, allowing the model to adapt to different speaking styles, accents, or environmental conditions.
The proposed model was tested on several standard speech recognition benchmarks, and the results show it outperforms both unimodal (audio-only or visual-only) approaches as well as other multimodal techniques. This suggests the mixture-of-experts design is an effective way to leverage the complementary information from audio and visual cues to improve overall speech recognition performance.
Technical Explanation
The researchers develop a Robust Audiovisual Speech Recognition (RA-VSR) model that uses a mixture-of-experts architecture. The model takes both audio and visual inputs (lip movements) and learns to combine them effectively for speech recognition.
The key components of the RA-VSR model include:
- Audio and Visual Encoders: These encode the raw audio and video inputs into compact feature representations.
- Modality-Specific Experts: These are specialized sub-models that process the audio and visual features separately.
- Modality Fusion: The outputs of the audio and visual experts are combined using a gating mechanism that learns to weight the contributions of each modality.
- Shared Decoder: A single decoder network generates the final text output from the fused audio-visual features.
The mixture-of-experts design allows the model to adaptively leverage the most relevant information from audio and visual inputs based on the given scenario. This makes the system more robust to noisy or challenging conditions compared to unimodal or simpler multimodal approaches.
The researchers evaluate RA-VSR on several speech recognition benchmarks, including LRS3-TED, GRID, and TCD-TIMIT. The results demonstrate the proposed model's superior performance over state-of-the-art baselines, particularly in noisy environments.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to robust audiovisual speech recognition. The mixture-of-experts architecture is a compelling innovation that allows the model to dynamically adapt to different speaking conditions.
However, the paper does not discuss the computational cost or inference speed of the RA-VSR model, which may be an important consideration for real-world deployments. Additionally, the experiments are limited to relatively constrained datasets, and it would be valuable to see how the model performs on more diverse, unconstrained speech recognition tasks.
Another area for potential improvement is the interpretability of the model. While the mixture-of-experts design is intuitive, it would be helpful to understand better how the model is combining the audio and visual cues, and which types of inputs it is relying on more heavily in different scenarios.
Conclusion
This research paper introduces a novel mixture-of-experts approach to audiovisual speech recognition that outperforms both unimodal and other multimodal techniques. By adaptively fusing audio and visual information, the RA-VSR model demonstrates impressive robustness to noisy environments, suggesting it could be a valuable tool for real-world speech recognition applications.
The mixture-of-experts architecture is a promising direction for future research, and the authors have made a valuable contribution to the field of multimodal speech processing. While there are some areas for potential improvement, this work represents an important step forward in developing more reliable and versatile speech recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Robust Audiovisual Speech Recognition Models with Mixture-of-Experts
Yihan Wu, Yifan Peng, Yichen Lu, Xuankai Chang, Ruihua Song, Shinji Watanabe
Visual signals can enhance audiovisual speech recognition accuracy by providing additional contextual information. Given the complexity of visual signals, an audiovisual speech recognition model requires robust generalization capabilities across diverse video scenarios, presenting a significant challenge. In this paper, we introduce EVA, leveraging the mixture-of-Experts for audioVisual ASR to perform robust speech recognition for ``in-the-wild'' videos. Specifically, we first encode visual information into visual tokens sequence and map them into speech space by a lightweight projection. Then, we build EVA upon a robust pretrained speech recognition model, ensuring its generalization ability. Moreover, to incorporate visual information effectively, we inject visual information into the ASR model through a mixture-of-experts module. Experiments show our model achieves state-of-the-art results on three benchmarks, which demonstrates the generalization ability of EVA across diverse video domains.
Read more9/20/2024
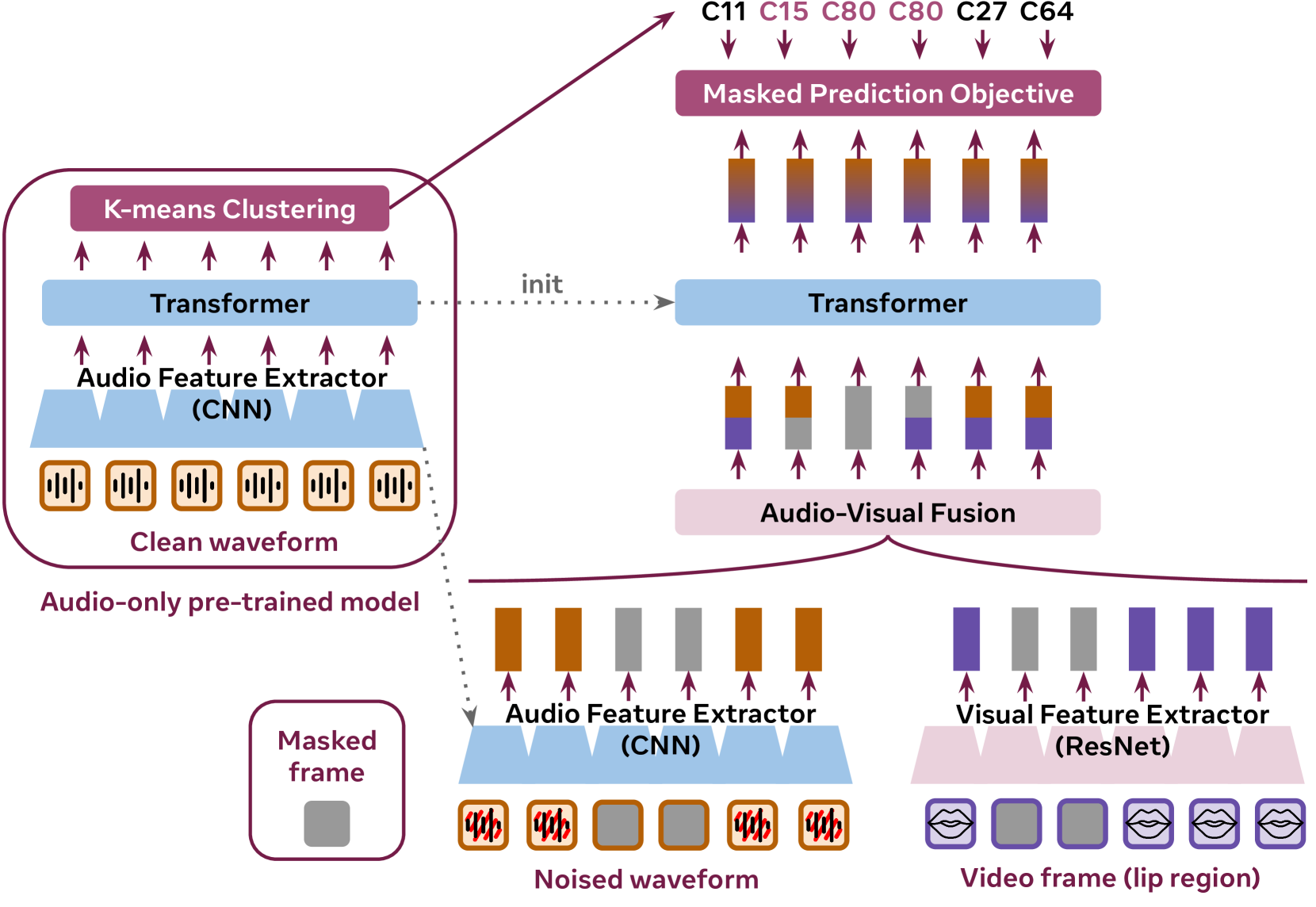
0
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception
HyoJung Han, Mohamed Anwar, Juan Pino, Wei-Ning Hsu, Marine Carpuat, Bowen Shi, Changhan Wang
Speech recognition and translation systems perform poorly on noisy inputs, which are frequent in realistic environments. Augmenting these systems with visual signals has the potential to improve robustness to noise. However, audio-visual (AV) data is only available in limited amounts and for fewer languages than audio-only resources. To address this gap, we present XLAVS-R, a cross-lingual audio-visual speech representation model for noise-robust speech recognition and translation in over 100 languages. It is designed to maximize the benefits of limited multilingual AV pre-training data, by building on top of audio-only multilingual pre-training and simplifying existing pre-training schemes. Extensive evaluation on the MuAViC benchmark shows the strength of XLAVS-R on downstream audio-visual speech recognition and translation tasks, where it outperforms the previous state of the art by up to 18.5% WER and 4.7 BLEU given noisy AV inputs, and enables strong zero-shot audio-visual ability with audio-only fine-tuning.
Read more8/13/2024
👁️
0
Versatile audio-visual learning for emotion recognition
Lucas Goncalves, Seong-Gyun Leem, Wei-Cheng Lin, Berrak Sisman, Carlos Busso
Most current audio-visual emotion recognition models lack the flexibility needed for deployment in practical applications. We envision a multimodal system that works even when only one modality is available and can be implemented interchangeably for either predicting emotional attributes or recognizing categorical emotions. Achieving such flexibility in a multimodal emotion recognition system is difficult due to the inherent challenges in accurately interpreting and integrating varied data sources. It is also a challenge to robustly handle missing or partial information while allowing direct switch between regression or classification tasks. This study proposes a versatile audio-visual learning (VAVL) framework for handling unimodal and multimodal systems for emotion regression or emotion classification tasks. We implement an audio-visual framework that can be trained even when audio and visual paired data is not available for part of the training set (i.e., audio only or only video is present). We achieve this effective representation learning with audio-visual shared layers, residual connections over shared layers, and a unimodal reconstruction task. Our experimental results reveal that our architecture significantly outperforms strong baselines on the CREMA-D, MSP-IMPROV, and CMU-MOSEI corpora. Notably, VAVL attains a new state-of-the-art performance in the emotional attribute prediction task on the MSP-IMPROV corpus.
Read more7/31/2024

0
RAVSS: Robust Audio-Visual Speech Separation in Multi-Speaker Scenarios with Missing Visual Cues
Tianrui Pan, Jie Liu, Bohan Wang, Jie Tang, Gangshan Wu
While existing Audio-Visual Speech Separation (AVSS) methods primarily concentrate on the audio-visual fusion strategy for two-speaker separation, they demonstrate a severe performance drop in the multi-speaker separation scenarios. Typically, AVSS methods employ guiding videos to sequentially isolate individual speakers from the given audio mixture, resulting in notable missing and noisy parts across various segments of the separated speech. In this study, we propose a simultaneous multi-speaker separation framework that can facilitate the concurrent separation of multiple speakers within a singular process. We introduce speaker-wise interactions to establish distinctions and correlations among speakers. Experimental results on the VoxCeleb2 and LRS3 datasets demonstrate that our method achieves state-of-the-art performance in separating mixtures with 2, 3, 4, and 5 speakers, respectively. Additionally, our model can utilize speakers with complete audio-visual information to mitigate other visual-deficient speakers, thereby enhancing its resilience to missing visual cues. We also conduct experiments where visual information for specific speakers is entirely absent or visual frames are partially missing. The results demonstrate that our model consistently outperforms others, exhibiting the smallest performance drop across all settings involving 2, 3, 4, and 5 speakers.
Read more7/31/2024