XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception

0
Sign in to get full access
Overview
- The paper proposes XLAVS-R, a cross-lingual audio-visual speech representation learning model for noise-robust speech perception.
- The model aims to learn robust speech representations that can generalize across languages and handle noisy speech.
- It utilizes a multi-task learning framework to jointly learn audio and visual speech representations.
Plain English Explanation
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception is a research paper that introduces a new way to teach computers to understand speech, even when it is noisy or spoken in different languages.
The key idea is to use both audio (sound) and visual (lip movements) information to learn robust speech representations. By combining these two modalities, the model can better understand speech, even in noisy environments or when the language is unfamiliar.
The researchers use a "multi-task learning" approach, which means the model is trained to do multiple related tasks at the same time. In this case, the model learns to represent both the audio and visual aspects of speech simultaneously. This allows the model to build a more comprehensive understanding of speech that can generalize to new languages and noisy conditions.
The goal is to create speech recognition systems that are more reliable and can work in a wider range of real-world scenarios, where noise and multi-lingual speech are common challenges.
Technical Explanation
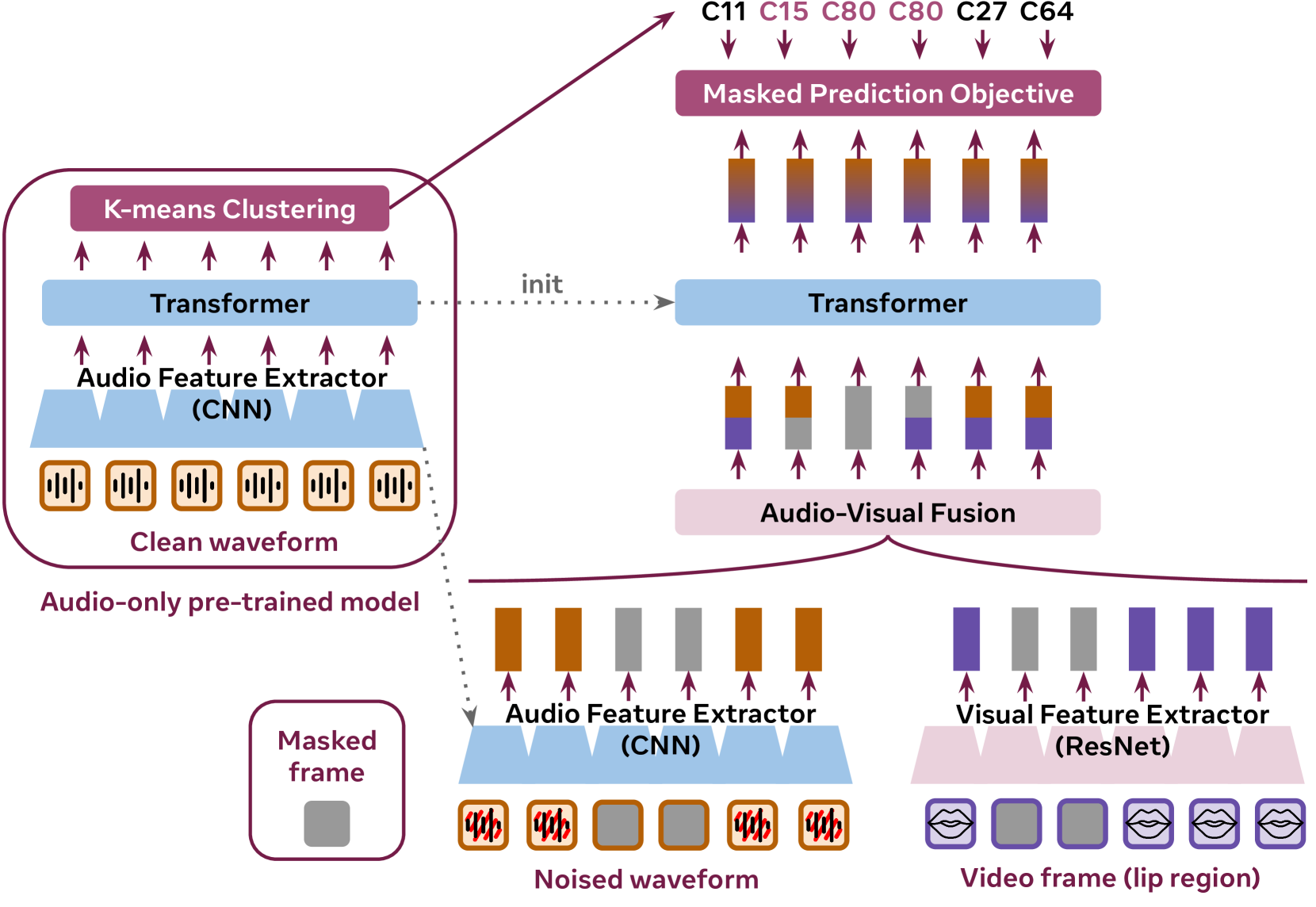
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception proposes a novel cross-lingual audio-visual speech representation learning model called XLAVS-R.
The model uses a multi-task learning framework to jointly learn audio and visual speech representations. The audio stream is processed using a convolutional neural network (CNN) encoder, while the visual stream is processed using a 3D CNN encoder. The encoded representations from both modalities are then combined using a cross-modal attention mechanism.
The model is trained on multiple languages, allowing it to learn speech representations that are robust to language variations. Additionally, the model is trained to handle noisy speech conditions by incorporating noise augmentation techniques during training.
The learned representations are evaluated on speech perception tasks, including cross-lingual speech recognition and noise-robust speech recognition. The results demonstrate that XLAVS-R outperforms unimodal and other state-of-the-art audio-visual speech recognition models, showcasing its ability to learn powerful cross-lingual and noise-robust speech representations.
Critical Analysis
The XLAVS-R paper presents a compelling approach to addressing the challenges of multilingual and noisy speech recognition. By leveraging both audio and visual modalities, the model is able to learn more robust and generalizable speech representations.
One potential limitation of the research is the reliance on simulated noise conditions during training. While this allows the model to handle a wide range of noise types, it may not fully capture the complexities of real-world noise encountered in practical applications. Additional evaluation on more diverse and realistic noise scenarios could further strengthen the claims about the model's noise-robustness.
Moreover, the paper does not provide detailed analyses of the model's performance on individual languages or noise conditions. A more granular understanding of the model's strengths and weaknesses across different languages and noise levels could inform future research and practical deployments.
Overall, the XLAVS-R approach represents an important step towards building more reliable and versatile speech recognition systems. Further exploration of the model's capabilities and limitations could lead to valuable insights for the field of multimodal speech processing.
Conclusion
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception introduces a novel cross-lingual audio-visual speech representation learning model that can handle noisy speech conditions. By jointly learning audio and visual speech representations, the model is able to achieve state-of-the-art performance on speech perception tasks, including cross-lingual and noise-robust speech recognition.
The research demonstrates the potential of multimodal learning approaches to build more robust and versatile speech processing systems. As speech technologies become increasingly important in our daily lives, the ability to handle diverse languages and noisy environments is crucial for their widespread adoption and real-world applicability.
The XLAVS-R model represents a significant step towards this goal, paving the way for further advancements in the field of multimodal speech processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception
HyoJung Han, Mohamed Anwar, Juan Pino, Wei-Ning Hsu, Marine Carpuat, Bowen Shi, Changhan Wang
Speech recognition and translation systems perform poorly on noisy inputs, which are frequent in realistic environments. Augmenting these systems with visual signals has the potential to improve robustness to noise. However, audio-visual (AV) data is only available in limited amounts and for fewer languages than audio-only resources. To address this gap, we present XLAVS-R, a cross-lingual audio-visual speech representation model for noise-robust speech recognition and translation in over 100 languages. It is designed to maximize the benefits of limited multilingual AV pre-training data, by building on top of audio-only multilingual pre-training and simplifying existing pre-training schemes. Extensive evaluation on the MuAViC benchmark shows the strength of XLAVS-R on downstream audio-visual speech recognition and translation tasks, where it outperforms the previous state of the art by up to 18.5% WER and 4.7 BLEU given noisy AV inputs, and enables strong zero-shot audio-visual ability with audio-only fine-tuning.
Read more8/13/2024
🗣️
0
Multilingual Audio-Visual Speech Recognition with Hybrid CTC/RNN-T Fast Conformer
Maxime Burchi, Krishna C. Puvvada, Jagadeesh Balam, Boris Ginsburg, Radu Timofte
Humans are adept at leveraging visual cues from lip movements for recognizing speech in adverse listening conditions. Audio-Visual Speech Recognition (AVSR) models follow similar approach to achieve robust speech recognition in noisy conditions. In this work, we present a multilingual AVSR model incorporating several enhancements to improve performance and audio noise robustness. Notably, we adapt the recently proposed Fast Conformer model to process both audio and visual modalities using a novel hybrid CTC/RNN-T architecture. We increase the amount of audio-visual training data for six distinct languages, generating automatic transcriptions of unlabelled multilingual datasets (VoxCeleb2 and AVSpeech). Our proposed model achieves new state-of-the-art performance on the LRS3 dataset, reaching WER of 0.8%. On the recently introduced MuAViC benchmark, our model yields an absolute average-WER reduction of 11.9% in comparison to the original baseline. Finally, we demonstrate the ability of the proposed model to perform audio-only, visual-only, and audio-visual speech recognition at test time.
Read more5/24/2024
🗣️
0
ViSpeR: Multilingual Audio-Visual Speech Recognition
Sanath Narayan, Yasser Abdelaziz Dahou Djilali, Ankit Singh, Eustache Le Bihan, Hakim Hacid
This work presents an extensive and detailed study on Audio-Visual Speech Recognition (AVSR) for five widely spoken languages: Chinese, Spanish, English, Arabic, and French. We have collected large-scale datasets for each language except for English, and have engaged in the training of supervised learning models. Our model, ViSpeR, is trained in a multi-lingual setting, resulting in competitive performance on newly established benchmarks for each language. The datasets and models are released to the community with an aim to serve as a foundation for triggering and feeding further research work and exploration on Audio-Visual Speech Recognition, an increasingly important area of research. Code available at href{https://github.com/YasserdahouML/visper}{https://github.com/YasserdahouML/visper}.
Read more6/4/2024

0
Learning Video Temporal Dynamics with Cross-Modal Attention for Robust Audio-Visual Speech Recognition
Sungnyun Kim, Kangwook Jang, Sangmin Bae, Hoirin Kim, Se-Young Yun
Audio-visual speech recognition (AVSR) aims to transcribe human speech using both audio and video modalities. In practical environments with noise-corrupted audio, the role of video information becomes crucial. However, prior works have primarily focused on enhancing audio features in AVSR, overlooking the importance of video features. In this study, we strengthen the video features by learning three temporal dynamics in video data: context order, playback direction, and the speed of video frames. Cross-modal attention modules are introduced to enrich video features with audio information so that speech variability can be taken into account when training on the video temporal dynamics. Based on our approach, we achieve the state-of-the-art performance on the LRS2 and LRS3 AVSR benchmarks for the noise-dominant settings. Our approach excels in scenarios especially for babble and speech noise, indicating the ability to distinguish the speech signal that should be recognized from lip movements in the video modality. We support the validity of our methodology by offering the ablation experiments for the temporal dynamics losses and the cross-modal attention architecture design.
Read more9/17/2024