Pre-trained Model Guided Fine-Tuning for Zero-Shot Adversarial Robustness

0
Sign in to get full access
Overview
- This paper explores a novel approach to improving the adversarial robustness of machine learning models through a process called "pre-trained model guided fine-tuning for zero-shot adversarial robustness."
- The researchers aim to develop models that can maintain high performance even when exposed to adversarial attacks, which are intentionally crafted inputs designed to fool the model.
- The proposed method leverages the knowledge and capabilities of pre-trained models to enhance the robustness of fine-tuned models, without requiring access to the original training data.
Plain English Explanation
The paper presents a way to make machine learning models more resistant to adversarial attacks, which are attempts to trick the models into making mistakes. The researchers use a two-step approach:
- They start with a pre-trained model, which is a model that has already been trained on a large dataset to perform a certain task, like image recognition or natural language processing.
- They then "fine-tune" this pre-trained model, which means they continue training it on a smaller, more specialized dataset related to the task they want the model to perform.
The key insight is that by guiding the fine-tuning process using the knowledge and capabilities of the pre-trained model, the researchers can create a new model that is both specialized for the task at hand and more robust to adversarial attacks. This is particularly valuable for applications of AI models where security and reliability are critical, such as in autonomous systems or healthcare.
Technical Explanation
The paper proposes a novel approach called "Pre-trained Model Guided Fine-Tuning for Zero-Shot Adversarial Robustness." The core idea is to leverage the knowledge and capabilities of a pre-trained model to enhance the adversarial robustness of a fine-tuned model, without requiring access to the original training data.
The researchers first train a pre-trained model on a large, general dataset. They then fine-tune this pre-trained model on a smaller, more specialized dataset related to the task they want the model to perform. Crucially, they guide the fine-tuning process by using a combination of the pre-trained model's output and a set of adversarial examples, which are inputs that have been deliberately modified to mislead the model.
This approach allows the fine-tuned model to inherit the general robustness of the pre-trained model, while also learning to be more resilient to the specific adversarial threats encountered during the fine-tuning stage. The researchers demonstrate the effectiveness of their method through experiments on various computer vision and natural language processing tasks, showing that it can significantly improve the adversarial robustness of fine-tuned models compared to traditional fine-tuning approaches.
Critical Analysis
The paper presents a promising approach to improving the adversarial robustness of machine learning models, but it also acknowledges several limitations and areas for future research.
One potential concern is the reliance on access to a pre-trained model, as this may not always be available, especially for more specialized or domain-specific tasks. The researchers suggest that their method could be extended to work with self-supervised pre-trained models, which could help address this limitation.
Additionally, the paper focuses primarily on evaluating the proposed method on standard adversarial attack benchmarks, such as FGSM and PGD. While these are widely used in the field, it would be valuable to assess the method's performance on more realistic, "real-world" adversarial attacks that may be more complex or diverse in nature.
Furthermore, the paper does not delve into the potential interpretability or explainability of the fine-tuned models, which could be an important consideration for certain applications where model decisions need to be transparent and accountable.
Conclusion
This paper presents a novel approach to enhancing the adversarial robustness of machine learning models through a process of pre-trained model guided fine-tuning. By leveraging the knowledge and capabilities of pre-trained models, the researchers demonstrate that it is possible to create fine-tuned models that are both specialized for a particular task and more resistant to adversarial attacks.
The implications of this research are significant, as improving the security and reliability of AI systems is crucial for their widespread adoption and deployment in critical applications. While the proposed method has some limitations, it represents an important step forward in the field of adversarial machine learning and could inspire further research to address the challenges of building truly robust and trustworthy AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pre-trained Model Guided Fine-Tuning for Zero-Shot Adversarial Robustness
Sibo Wang, Jie Zhang, Zheng Yuan, Shiguang Shan
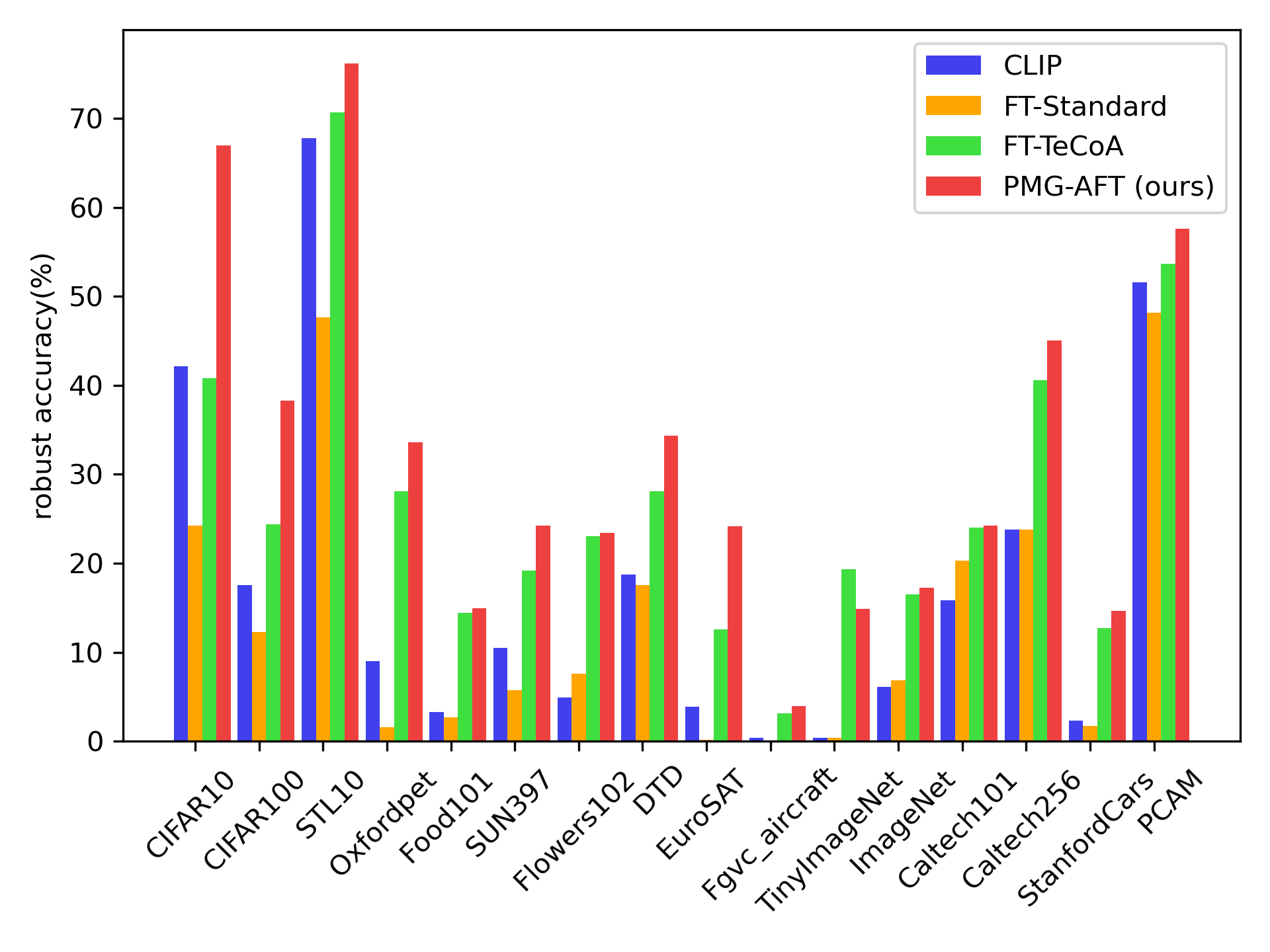
Large-scale pre-trained vision-language models like CLIP have demonstrated impressive performance across various tasks, and exhibit remarkable zero-shot generalization capability, while they are also vulnerable to imperceptible adversarial examples. Existing works typically employ adversarial training (fine-tuning) as a defense method against adversarial examples. However, direct application to the CLIP model may result in overfitting, compromising the model's capacity for generalization. In this paper, we propose Pre-trained Model Guided Adversarial Fine-Tuning (PMG-AFT) method, which leverages supervision from the original pre-trained model by carefully designing an auxiliary branch, to enhance the model's zero-shot adversarial robustness. Specifically, PMG-AFT minimizes the distance between the features of adversarial examples in the target model and those in the pre-trained model, aiming to preserve the generalization features already captured by the pre-trained model. Extensive Experiments on 15 zero-shot datasets demonstrate that PMG-AFT significantly outperforms the state-of-the-art method, improving the top-1 robust accuracy by an average of 4.99%. Furthermore, our approach consistently improves clean accuracy by an average of 8.72%. Our code is available at https://github.com/serendipity1122/Pre-trained-Model-Guided-Fine-Tuning-for-Zero-Shot-Adversarial-Robustness.
Read more4/11/2024

0
Revisiting the Robust Generalization of Adversarial Prompt Tuning
Fan Yang, Mingxuan Xia, Sangzhou Xia, Chicheng Ma, Hui Hui
Understanding the vulnerability of large-scale pre-trained vision-language models like CLIP against adversarial attacks is key to ensuring zero-shot generalization capacity on various downstream tasks. State-of-the-art defense mechanisms generally adopt prompt learning strategies for adversarial fine-tuning to improve the adversarial robustness of the pre-trained model while keeping the efficiency of adapting to downstream tasks. Such a setup leads to the problem of over-fitting which impedes further improvement of the model's generalization capacity on both clean and adversarial examples. In this work, we propose an adaptive Consistency-guided Adversarial Prompt Tuning (i.e., CAPT) framework that utilizes multi-modal prompt learning to enhance the alignment of image and text features for adversarial examples and leverage the strong generalization of pre-trained CLIP to guide the model-enhancing its robust generalization on adversarial examples while maintaining its accuracy on clean ones. We also design a novel adaptive consistency objective function to balance the consistency of adversarial inputs and clean inputs between the fine-tuning model and the pre-trained model. We conduct extensive experiments across 14 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show the superiority of CAPT over other state-of-the-art adaption methods. CAPT demonstrated excellent performance in terms of the in-distribution performance and the generalization under input distribution shift and across datasets.
Read more5/21/2024

0
Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
Christian Schlarmann, Naman Deep Singh, Francesco Croce, Matthias Hein
Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many large vision-language models (LVLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (LVLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of LVLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the down-stream LVLMs is required. The code and robust models are available at https://github.com/chs20/RobustVLM
Read more6/6/2024

0
Efficient and Versatile Robust Fine-Tuning of Zero-shot Models
Sungyeon Kim, Boseung Jeong, Donghyun Kim, Suha Kwak
Large-scale image-text pre-trained models enable zero-shot classification and provide consistent accuracy across various data distributions. Nonetheless, optimizing these models in downstream tasks typically requires fine-tuning, which reduces generalization to out-of-distribution (OOD) data and demands extensive computational resources. We introduce Robust Adapter (R-Adapter), a novel method for fine-tuning zero-shot models to downstream tasks while simultaneously addressing both these issues. Our method integrates lightweight modules into the pre-trained model and employs novel self-ensemble techniques to boost OOD robustness and reduce storage expenses substantially. Furthermore, we propose MPM-NCE loss designed for fine-tuning on vision-language downstream tasks. It ensures precise alignment of multiple image-text pairs and discriminative feature learning. By extending the benchmark for robust fine-tuning beyond classification to include diverse tasks such as cross-modal retrieval and open vocabulary segmentation, we demonstrate the broad applicability of R-Adapter. Our extensive experiments demonstrate that R-Adapter achieves state-of-the-art performance across a diverse set of tasks, tuning only 13% of the parameters of the CLIP encoders.
Read more8/13/2024