Robust COVID-19 Detection in CT Images with CLIP

0

Sign in to get full access
Overview
- The research paper explores the use of CLIP (Contrastive Language-Image Pre-training) for robust detection of COVID-19 in CT images.
- CLIP is a popular deep learning model that can understand the semantic relationship between images and text.
- The researchers investigate how CLIP can be leveraged for accurate COVID-19 detection, even in the presence of data distribution shifts or adversarial attacks.
Plain English Explanation
The researchers in this paper wanted to explore how a powerful AI model called CLIP could be used to reliably detect COVID-19 in CT scan images. CLIP is a deep learning model that has been trained to understand the connection between images and the words or captions that describe them.
The key idea is that CLIP's ability to grasp semantic relationships could make it useful for identifying COVID-19 patterns in medical images, even when the data changes or someone tries to trick the model. The researchers tested CLIP's performance on COVID-19 detection tasks and compared it to other AI models. They also looked at how CLIP held up against intentional attempts to confuse or "fool" the model.
Overall, the results suggest that CLIP can be a robust and effective tool for detecting COVID-19 in CT scans, potentially outperforming other approaches. This could have important implications for improving medical diagnosis and care, especially in challenging situations where standard AI models may struggle.
Technical Explanation
The researchers in this paper investigate the use of the CLIP (Contrastive Language-Image Pre-training) model for the task of robust COVID-19 detection in CT images. CLIP is a deep learning model that has been pre-trained on a large dataset of image-text pairs, allowing it to learn powerful semantic representations that can be applied to a variety of visual recognition tasks.
The key hypothesis is that CLIP's ability to understand the relationship between images and text can be leveraged for accurate COVID-19 detection, even in the presence of distribution shifts or adversarial attacks that can confuse other AI models. To test this, the researchers evaluate CLIP's performance on COVID-19 detection benchmarks and compare it to other state-of-the-art approaches.
The experiments demonstrate that CLIP achieves strong performance on COVID-19 detection, often outperforming specialized models trained solely on medical imaging data. Furthermore, the researchers show that CLIP is more robust to distribution shifts and adversarial attacks compared to other methods. This suggests that CLIP's broad and flexible representation learning capabilities can make it a valuable tool for medical image analysis, especially in challenging real-world scenarios.
Critical Analysis
The researchers provide a thorough and well-designed evaluation of CLIP's capabilities for COVID-19 detection in CT images. The use of distribution shifts and adversarial attacks to test the model's robustness is a particularly valuable contribution, as it helps uncover potential weaknesses that could be important in real-world medical applications.
However, the paper does not delve deeply into the limitations or caveats of the CLIP approach. For example, it is unclear how the model would perform on smaller or more diverse datasets, or how it compares to human radiologists in terms of accuracy and interpretability. Additionally, the researchers do not explore potential biases or fairness issues that could arise from using a general-purpose model like CLIP for medical diagnosis.
Further research is needed to fully understand the tradeoffs and potential pitfalls of deploying CLIP-based systems in clinical settings. Nonetheless, the strong performance and robustness demonstrated in this paper suggest that CLIP is a promising direction for improving the reliability and accessibility of COVID-19 detection in medical imaging.
Conclusion
This research paper presents a compelling case for using the CLIP model to enable robust and accurate detection of COVID-19 in CT images. The experiments show that CLIP can outperform specialized medical imaging models, particularly in the face of distribution shifts and adversarial attacks that can confuse other AI systems.
The findings have important implications for enhancing medical diagnosis and care, as CLIP's broad and flexible representation learning capabilities could make it a valuable tool for adapting to the challenges of real-world clinical scenarios. While further research is needed to fully understand the limitations and potential biases of this approach, the paper demonstrates the exciting potential of leveraging general-purpose language-vision models like CLIP for specialized medical imaging tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust COVID-19 Detection in CT Images with CLIP
Li Lin, Yamini Sri Krubha, Zhenhuan Yang, Cheng Ren, Thuc Duy Le, Irene Amerini, Xin Wang, Shu Hu
In the realm of medical imaging, particularly for COVID-19 detection, deep learning models face substantial challenges such as the necessity for extensive computational resources, the paucity of well-annotated datasets, and a significant amount of unlabeled data. In this work, we introduce the first lightweight detector designed to overcome these obstacles, leveraging a frozen CLIP image encoder and a trainable multilayer perception (MLP). Enhanced with Conditional Value at Risk (CVaR) for robustness and a loss landscape flattening strategy for improved generalization, our model is tailored for high efficacy in COVID-19 detection. Furthermore, we integrate a teacher-student framework to capitalize on the vast amounts of unlabeled data, enabling our model to achieve superior performance despite the inherent data limitations. Experimental results on the COV19-CT-DB dataset demonstrate the effectiveness of our approach, surpassing baseline by up to 10.6% in `macro' F1 score in supervised learning. The code is available at https://github.com/Purdue-M2/COVID-19_Detection_M2_PURDUE.
Read more9/10/2024
0
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
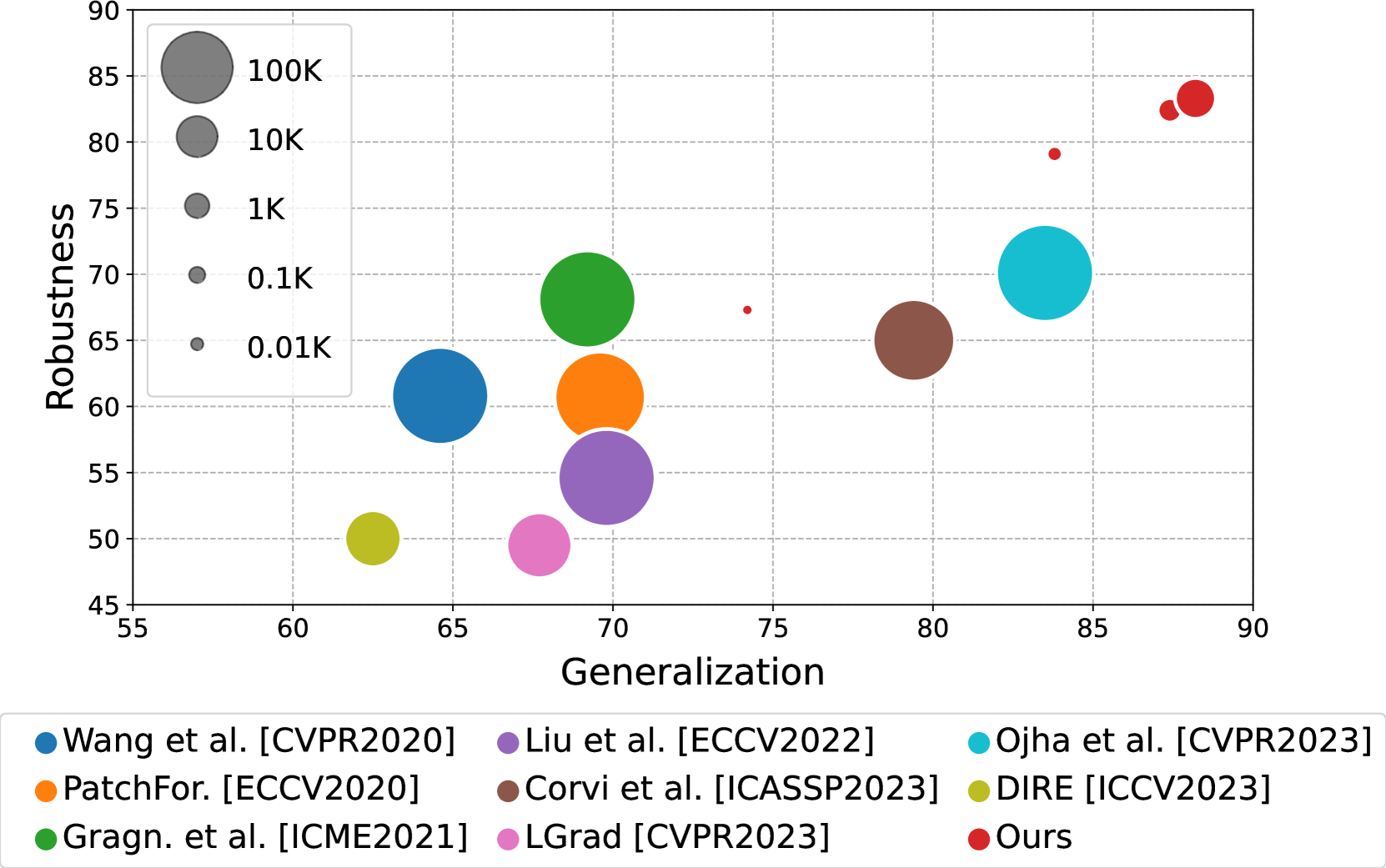
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
Read more4/30/2024
0
Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
Santosh, Li Lin, Irene Amerini, Xin Wang, Shu Hu
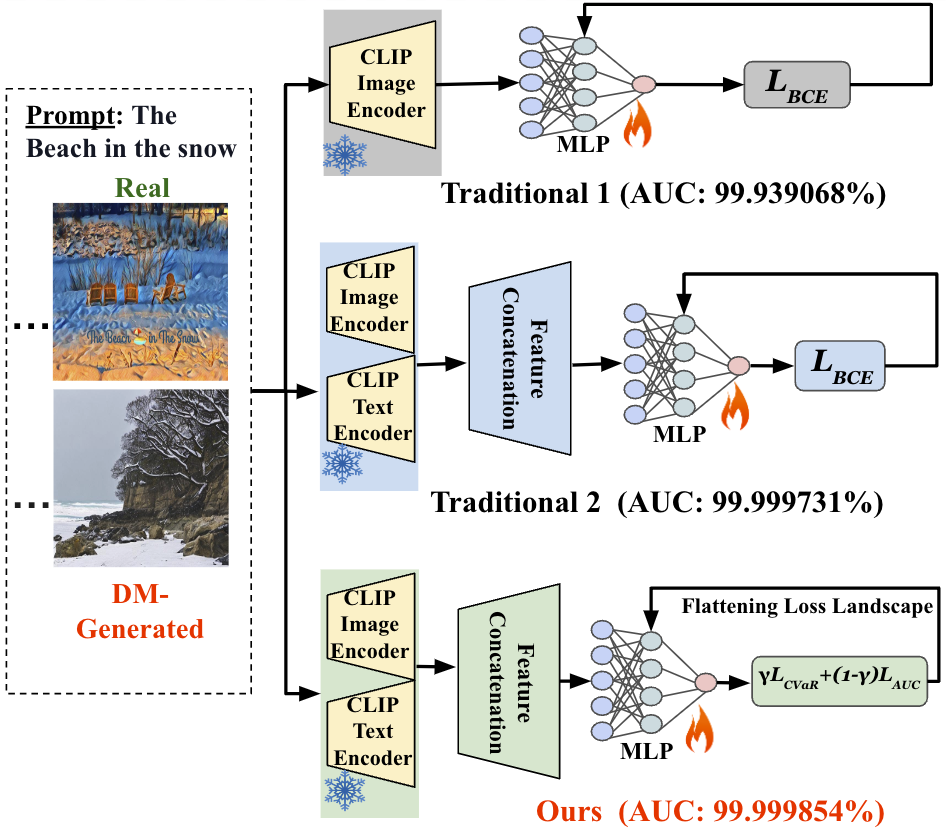
Diffusion models (DMs) have revolutionized image generation, producing high-quality images with applications spanning various fields. However, their ability to create hyper-realistic images poses significant challenges in distinguishing between real and synthetic content, raising concerns about digital authenticity and potential misuse in creating deepfakes. This work introduces a robust detection framework that integrates image and text features extracted by CLIP model with a Multilayer Perceptron (MLP) classifier. We propose a novel loss that can improve the detector's robustness and handle imbalanced datasets. Additionally, we flatten the loss landscape during the model training to improve the detector's generalization capabilities. The effectiveness of our method, which outperforms traditional detection techniques, is demonstrated through extensive experiments, underscoring its potential to set a new state-of-the-art approach in DM-generated image detection. The code is available at https://github.com/Purdue-M2/Robust_DM_Generated_Image_Detection.
Read more9/10/2024

0
MediCLIP: Adapting CLIP for Few-shot Medical Image Anomaly Detection
Ximiao Zhang, Min Xu, Dehui Qiu, Ruixin Yan, Ning Lang, Xiuzhuang Zhou
In the field of medical decision-making, precise anomaly detection in medical imaging plays a pivotal role in aiding clinicians. However, previous work is reliant on large-scale datasets for training anomaly detection models, which increases the development cost. This paper first focuses on the task of medical image anomaly detection in the few-shot setting, which is critically significant for the medical field where data collection and annotation are both very expensive. We propose an innovative approach, MediCLIP, which adapts the CLIP model to few-shot medical image anomaly detection through self-supervised fine-tuning. Although CLIP, as a vision-language model, demonstrates outstanding zero-/fewshot performance on various downstream tasks, it still falls short in the anomaly detection of medical images. To address this, we design a series of medical image anomaly synthesis tasks to simulate common disease patterns in medical imaging, transferring the powerful generalization capabilities of CLIP to the task of medical image anomaly detection. When only few-shot normal medical images are provided, MediCLIP achieves state-of-the-art performance in anomaly detection and location compared to other methods. Extensive experiments on three distinct medical anomaly detection tasks have demonstrated the superiority of our approach. The code is available at https://github.com/cnulab/MediCLIP.
Read more5/21/2024