MediCLIP: Adapting CLIP for Few-shot Medical Image Anomaly Detection
2405.11315
0
0

Abstract
In the field of medical decision-making, precise anomaly detection in medical imaging plays a pivotal role in aiding clinicians. However, previous work is reliant on large-scale datasets for training anomaly detection models, which increases the development cost. This paper first focuses on the task of medical image anomaly detection in the few-shot setting, which is critically significant for the medical field where data collection and annotation are both very expensive. We propose an innovative approach, MediCLIP, which adapts the CLIP model to few-shot medical image anomaly detection through self-supervised fine-tuning. Although CLIP, as a vision-language model, demonstrates outstanding zero-/fewshot performance on various downstream tasks, it still falls short in the anomaly detection of medical images. To address this, we design a series of medical image anomaly synthesis tasks to simulate common disease patterns in medical imaging, transferring the powerful generalization capabilities of CLIP to the task of medical image anomaly detection. When only few-shot normal medical images are provided, MediCLIP achieves state-of-the-art performance in anomaly detection and location compared to other methods. Extensive experiments on three distinct medical anomaly detection tasks have demonstrated the superiority of our approach. The code is available at https://github.com/cnulab/MediCLIP.
Create account to get full access
Overview
- This paper presents MediCLIP, a method that adapts the CLIP model for few-shot medical image anomaly detection.
- CLIP is a powerful pre-trained model that can perform zero-shot image classification, but it has not been widely used for medical image analysis tasks.
- MediCLIP aims to leverage CLIP's strengths to enable few-shot detection of anomalies in medical images, which is an important problem in healthcare.
Plain English Explanation
MediCLIP is a new technique that takes an existing AI model called CLIP and adapts it to work well for detecting unusual or abnormal things in medical images. CLIP is a very capable model that can recognize all sorts of objects and concepts in regular photos, but it hasn't been used much for analyzing medical images before.
The key idea behind MediCLIP is to take the CLIP model and fine-tune it on a small number of medical images that contain anomalies or abnormalities. This allows MediCLIP to learn the visual patterns and characteristics of medical anomalies, so that it can then identify them in new images, even if it has only seen a few examples. This "few-shot" learning capability is important for medical applications, where it's often difficult to gather large labeled datasets.
By building on the strong foundation of CLIP, MediCLIP can leverage its broad understanding of the visual world to more effectively detect anomalies in medical scans and images. This could be really helpful for tasks like screening for diseases or picking up on subtle signs of health issues that might be easy for human experts to miss.
Technical Explanation
The core innovation in MediCLIP is its adaptation of the CLIP model (link) for the task of few-shot medical image anomaly detection. CLIP is a powerful multimodal model pre-trained on a large corpus of image-text pairs, which enables it to perform zero-shot image classification by linking visual concepts to textual descriptions (link).
To leverage CLIP for medical anomaly detection, the authors fine-tune the model on a small number of labeled medical images containing anomalies. This fine-tuning process allows MediCLIP to learn the distinctive visual patterns and characteristics of medical anomalies, which it can then use to identify similar anomalies in new images (link).
The authors also explore different approaches for prompting the fine-tuned MediCLIP model, including using textual prompts and cross-modal prompts that combine text and image information (link). These prompting techniques help MediCLIP effectively leverage its multimodal understanding to detect anomalies in the few-shot learning setting.
Critical Analysis
The MediCLIP paper presents a promising approach for adapting the CLIP model to medical image analysis tasks, particularly in the challenging few-shot learning scenario. The authors demonstrate strong performance on several medical anomaly detection benchmarks, suggesting that their approach could be widely applicable.
However, the paper does not address some important limitations and caveats. For example, the authors only evaluate MediCLIP on a limited set of medical image datasets, and it's unclear how well the approach would generalize to other modalities or disease contexts. Additionally, the paper does not provide much insight into the types of anomalies that MediCLIP is able to detect, or the clinical relevance of those anomalies.
Further research would be needed to better understand the capabilities and limitations of MediCLIP, as well as its potential impact on real-world medical applications (link). Careful evaluation with input from domain experts would be crucial to ensure that MediCLIP is robust, reliable, and clinically meaningful.
Conclusion
Overall, the MediCLIP paper presents an intriguing approach for adapting the powerful CLIP model to the domain of medical image analysis. By leveraging CLIP's multimodal understanding and fine-tuning it for few-shot anomaly detection, the authors have developed a technique that could have significant implications for medical screening, diagnosis, and disease monitoring.
While the paper leaves some open questions and areas for further research, the strong empirical results suggest that MediCLIP is a promising step towards more effective and accessible medical image analysis tools. As AI continues to advance, innovations like MediCLIP will be crucial for translating these powerful technologies into real-world healthcare applications that can improve patient outcomes and support medical professionals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!CLIP3D-AD: Extending CLIP for 3D Few-Shot Anomaly Detection with Multi-View Images Generation
Zuo Zuo, Jiahao Dong, Yao Wu, Yanyun Qu, Zongze Wu
0
0
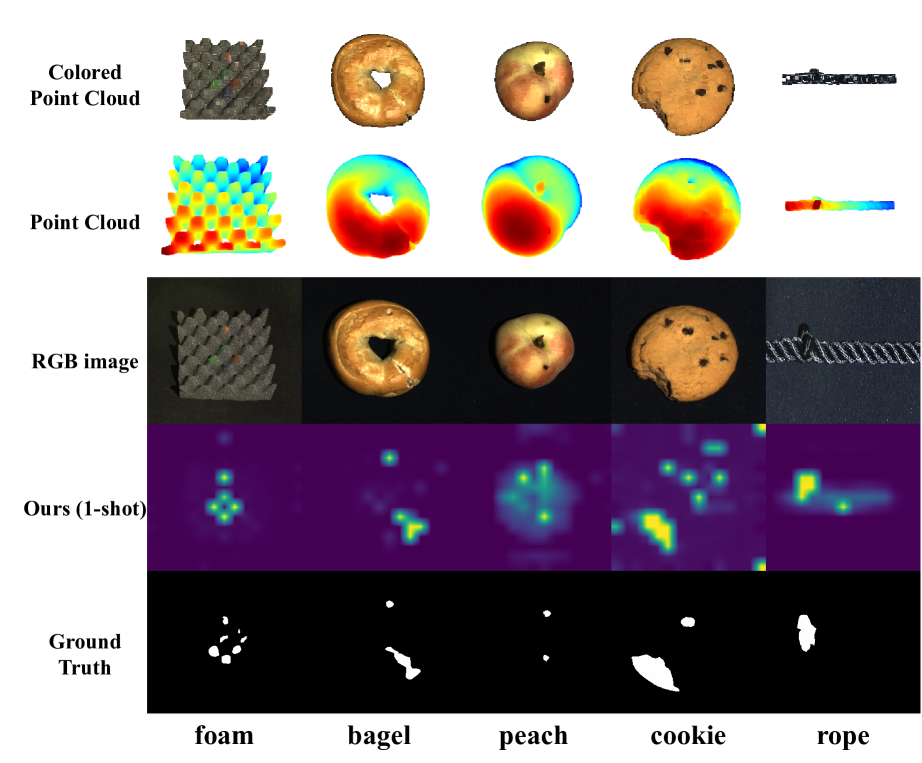
Few-shot anomaly detection methods can effectively address data collecting difficulty in industrial scenarios. Compared to 2D few-shot anomaly detection (2D-FSAD), 3D few-shot anomaly detection (3D-FSAD) is still an unexplored but essential task. In this paper, we propose CLIP3D-AD, an efficient 3D-FSAD method extended on CLIP. We successfully transfer strong generalization ability of CLIP into 3D-FSAD. Specifically, we synthesize anomalous images on given normal images as sample pairs to adapt CLIP for 3D anomaly classification and segmentation. For classification, we introduce an image adapter and a text adapter to fine-tune global visual features and text features. Meanwhile, we propose a coarse-to-fine decoder to fuse and facilitate intermediate multi-layer visual representations of CLIP. To benefit from geometry information of point cloud and eliminate modality and data discrepancy when processed by CLIP, we project and render point cloud to multi-view normal and anomalous images. Then we design multi-view fusion module to fuse features of multi-view images extracted by CLIP which are used to facilitate visual representations for further enhancing vision-language correlation. Extensive experiments demonstrate that our method has a competitive performance of 3D few-shot anomaly classification and segmentation on MVTec-3D AD dataset.
6/28/2024
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
0
0
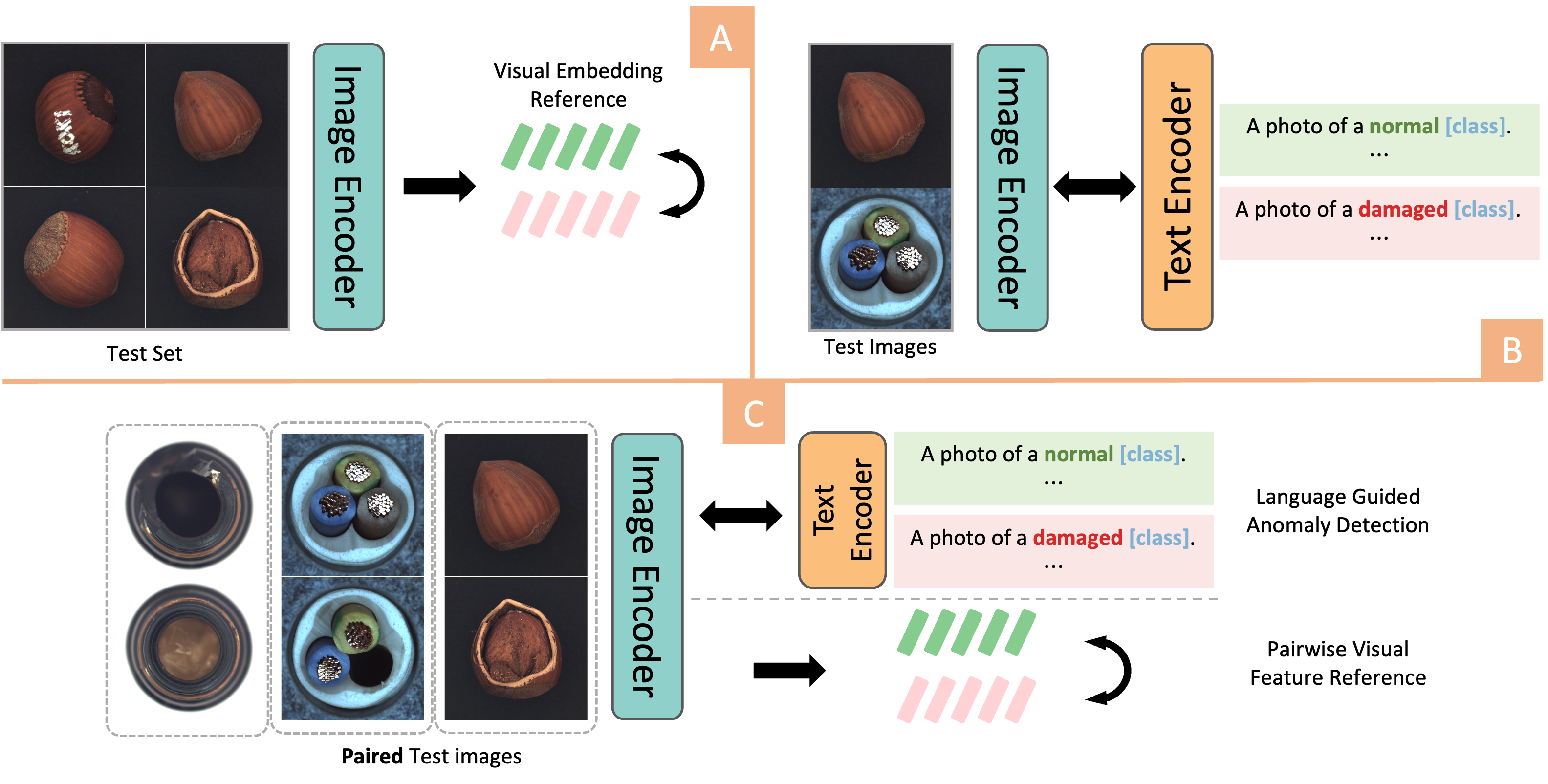
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
5/9/2024

CLIP in Medical Imaging: A Comprehensive Survey
Zihao Zhao, Yuxiao Liu, Han Wu, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Zhiming Cui, Qian Wang, Dinggang Shen
0
0
Contrastive Language-Image Pre-training (CLIP), a simple yet effective pre-training paradigm, successfully introduces text supervision to vision models. It has shown promising results across various tasks, attributable to its generalizability and interpretability. The use of CLIP has recently gained increasing interest in the medical imaging domain, serving both as a pre-training paradigm for aligning medical vision and language, and as a critical component in diverse clinical tasks. With the aim of facilitating a deeper understanding of this promising direction, this survey offers an in-depth exploration of the CLIP paradigm within the domain of medical imaging, regarding both refined CLIP pre-training and CLIP-driven applications. In this study, We (1) start with a brief introduction to the fundamentals of CLIP methodology. (2) Then, we investigate the adaptation of CLIP pre-training in the medical domain, focusing on how to optimize CLIP given characteristics of medical images and reports. (3) Furthermore, we explore the practical utilization of CLIP pre-trained models in various tasks, including classification, dense prediction, and cross-modal tasks. (4) Finally, we discuss existing limitations of CLIP in the context of medical imaging and propose forward-looking directions to address the demands of medical imaging domain. We expect that this comprehensive survey will provide researchers in the field of medical image analysis with a holistic understanding of the CLIP paradigm and its potential implications. The project page can be found on https://github.com/zhaozh10/Awesome-CLIP-in-Medical-Imaging.
5/22/2024
⛏️
Transductive Zero-Shot and Few-Shot CLIP
S'egol`ene Martin (OPIS, CVN), Yunshi Huang (ETS), Fereshteh Shakeri (ETS), Jean-Christophe Pesquet (OPIS, CVN), Ismail Ben Ayed (ETS)
0
0
Transductive inference has been widely investigated in few-shot image classification, but completely overlooked in the recent, fast growing literature on adapting vision-langage models like CLIP. This paper addresses the transductive zero-shot and few-shot CLIP classification challenge, in which inference is performed jointly across a mini-batch of unlabeled query samples, rather than treating each instance independently. We initially construct informative vision-text probability features, leading to a classification problem on the unit simplex set. Inspired by Expectation-Maximization (EM), our optimization-based classification objective models the data probability distribution for each class using a Dirichlet law. The minimization problem is then tackled with a novel block Majorization-Minimization algorithm, which simultaneously estimates the distribution parameters and class assignments. Extensive numerical experiments on 11 datasets underscore the benefits and efficacy of our batch inference approach.On zero-shot tasks with test batches of 75 samples, our approach yields near 20% improvement in ImageNet accuracy over CLIP's zero-shot performance. Additionally, we outperform state-of-the-art methods in the few-shot setting. The code is available at: https://github.com/SegoleneMartin/transductive-CLIP.
5/30/2024