Robust Image Classification in the Presence of Out-of-Distribution and Adversarial Samples Using Attractors in Neural Networks
2406.10579
0
0
🖼️
Abstract
The proper handling of out-of-distribution (OOD) samples in deep classifiers is a critical concern for ensuring the suitability of deep neural networks in safety-critical systems. Existing approaches developed for robust OOD detection in the presence of adversarial attacks lose their performance by increasing the perturbation levels. This study proposes a method for robust classification in the presence of OOD samples and adversarial attacks with high perturbation levels. The proposed approach utilizes a fully connected neural network that is trained to use training samples as its attractors, enhancing its robustness. This network has the ability to classify inputs and identify OOD samples as well. To evaluate this method, the network is trained on the MNIST dataset, and its performance is tested on adversarial examples. The results indicate that the network maintains its performance even when classifying adversarial examples, achieving 87.13% accuracy when dealing with highly perturbed MNIST test data. Furthermore, by using fashion-MNIST and CIFAR-10-bw as OOD samples, the network can distinguish these samples from MNIST samples with an accuracy of 98.84% and 99.28%, respectively. In the presence of severe adversarial attacks, these measures decrease slightly to 98.48% and 98.88%, indicating the robustness of the proposed method.
Create account to get full access
Overview
- This study proposes a method for robust classification in the presence of out-of-distribution (OOD) samples and adversarial attacks with high perturbation levels.
- The proposed approach uses a fully connected neural network trained to use training samples as its attractors, enhancing its robustness.
- The network can classify inputs and identify OOD samples, maintaining its performance even when classifying highly perturbed adversarial examples.
Plain English Explanation
Deep neural networks are increasingly being used in safety-critical systems, such as self-driving cars or medical diagnosis, where it is crucial that they can handle unexpected or "out-of-distribution" (OOD) data accurately. However, existing methods for detecting OOD samples often struggle when faced with adversarial attacks, which are malicious inputs designed to fool the network.
The researchers in this study developed a new approach to address this problem. They trained a neural network to use the original training data as "attractors" - points in the network's internal representation that it is drawn towards. This makes the network more robust, so that it can still classify inputs correctly even when they are adversarially perturbed, and can also reliably detect OOD samples.
When tested on the MNIST handwritten digit dataset, the network maintained 87.13% accuracy even on highly perturbed adversarial examples. It could also distinguish MNIST samples from OOD samples like fashion-MNIST and CIFAR-10 with over 98% accuracy, even in the presence of severe adversarial attacks.
This research is an important step towards making deep neural networks more reliable and suitable for safety-critical applications, by improving their ability to handle unexpected or adversarial data. Link to paper on OOD detection
Technical Explanation
The proposed approach utilizes a fully connected neural network that is trained to use the training samples from the MNIST dataset as its attractors. This enhances the network's robustness, allowing it to classify inputs and identify OOD samples even in the presence of adversarial attacks with high perturbation levels.
The network is trained on the MNIST dataset and its performance is evaluated on adversarial examples. The results show that the network maintains an accuracy of 87.13% when dealing with highly perturbed MNIST test data. Additionally, by using fashion-MNIST and CIFAR-10-bw as OOD samples, the network can distinguish these samples from MNIST samples with an accuracy of 98.84% and 99.28%, respectively. Even in the presence of severe adversarial attacks, these OOD detection measures only decrease slightly to 98.48% and 98.88%, demonstrating the robustness of the proposed method.
The key innovation in this work is the use of training samples as attractors, which helps the network learn a more robust internal representation. This allows the network to maintain its performance on adversarial examples and effectively detect OOD samples, even in the face of strong perturbations. Link to paper on adversarial examples and OOD detection
Critical Analysis
The paper provides a promising approach for improving the robustness of deep neural networks to OOD samples and adversarial attacks. However, the researchers only evaluated the method on a relatively simple dataset (MNIST) and two OOD datasets (fashion-MNIST and CIFAR-10-bw). It would be valuable to see how the approach performs on more complex, real-world datasets and a wider range of OOD samples.
Additionally, the paper does not provide much insight into the underlying mechanisms that allow the network to maintain its performance in the presence of adversarial attacks. Link to paper on understanding OOD detection Further analysis of the network's internal representations and decision-making process could shed light on the reasons for its robustness.
While the OOD detection results are impressive, the researchers could also explore ways to further improve the network's ability to detect adversarial examples, potentially by incorporating gradient regularization techniques. Link to paper on gradient regularization for OOD detection This could make the approach even more suitable for safety-critical applications.
Overall, this research represents an important step forward in developing more reliable deep learning systems, and the proposed method shows promise for enhancing the robustness of neural networks to OOD samples and adversarial attacks. Link to paper on subspace projection for OOD detection
Conclusion
This study presents a novel approach for robust classification in the presence of out-of-distribution (OOD) samples and adversarial attacks. By training a neural network to use the original training data as attractors, the researchers were able to enhance the network's robustness, allowing it to maintain high performance even on highly perturbed adversarial examples.
The results demonstrate the potential of this method for improving the reliability of deep neural networks in safety-critical applications, where the ability to handle unexpected or malicious inputs is crucial. While further research is needed to explore the approach's performance on more complex datasets and adversarial attacks, this work represents an important contribution to the field of robust deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
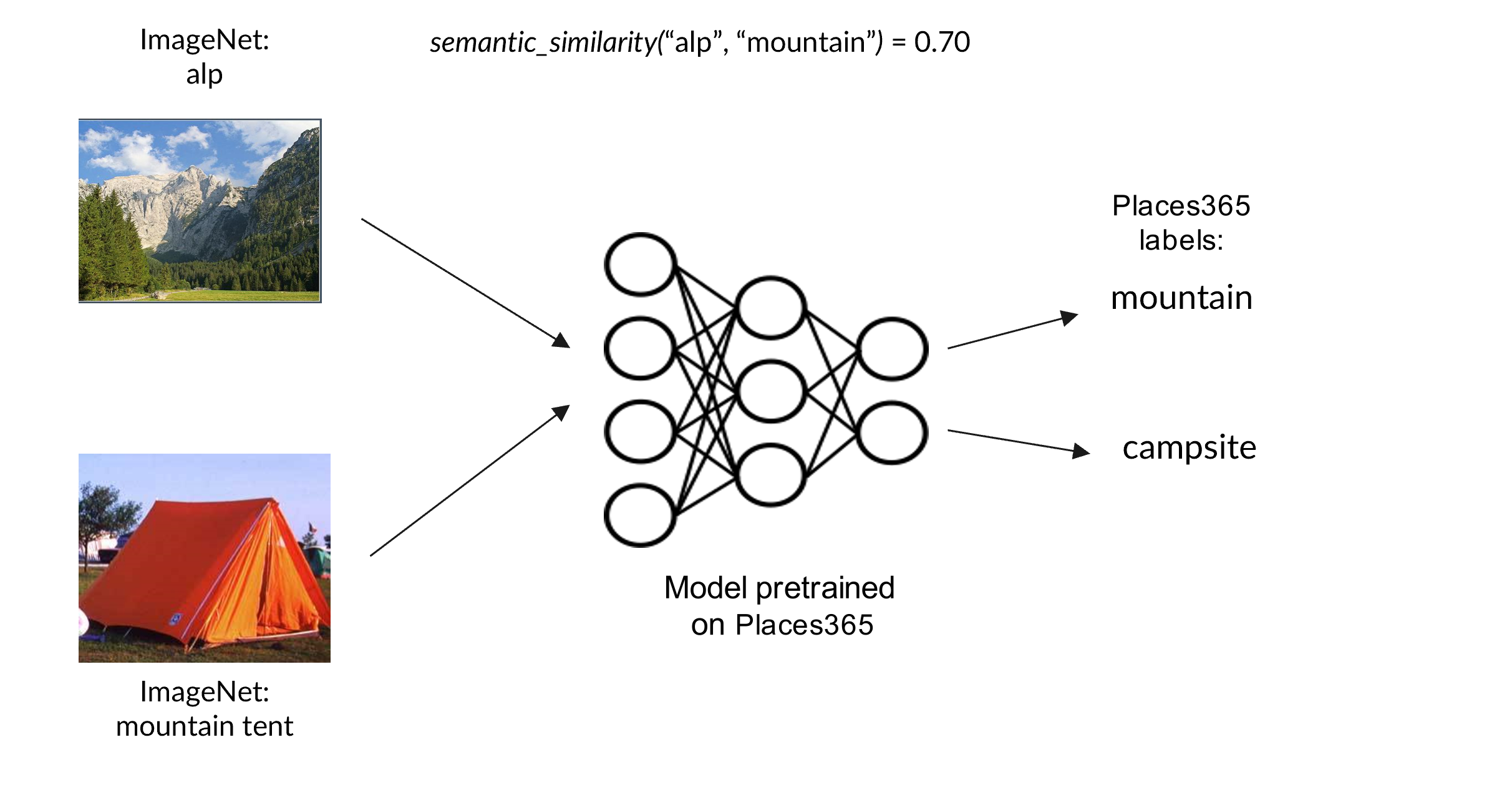
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
0
0
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
4/17/2024

Out-of-Distribution Data: An Acquaintance of Adversarial Examples -- A Survey
Naveen Karunanayake, Ravin Gunawardena, Suranga Seneviratne, Sanjay Chawla
0
0
Deep neural networks (DNNs) deployed in real-world applications can encounter out-of-distribution (OOD) data and adversarial examples. These represent distinct forms of distributional shifts that can significantly impact DNNs' reliability and robustness. Traditionally, research has addressed OOD detection and adversarial robustness as separate challenges. This survey focuses on the intersection of these two areas, examining how the research community has investigated them together. Consequently, we identify two key research directions: robust OOD detection and unified robustness. Robust OOD detection aims to differentiate between in-distribution (ID) data and OOD data, even when they are adversarially manipulated to deceive the OOD detector. Unified robustness seeks a single approach to make DNNs robust against both adversarial attacks and OOD inputs. Accordingly, first, we establish a taxonomy based on the concept of distributional shifts. This framework clarifies how robust OOD detection and unified robustness relate to other research areas addressing distributional shifts, such as OOD detection, open set recognition, and anomaly detection. Subsequently, we review existing work on robust OOD detection and unified robustness. Finally, we highlight the limitations of the existing work and propose promising research directions that explore adversarial and OOD inputs within a unified framework.
4/9/2024
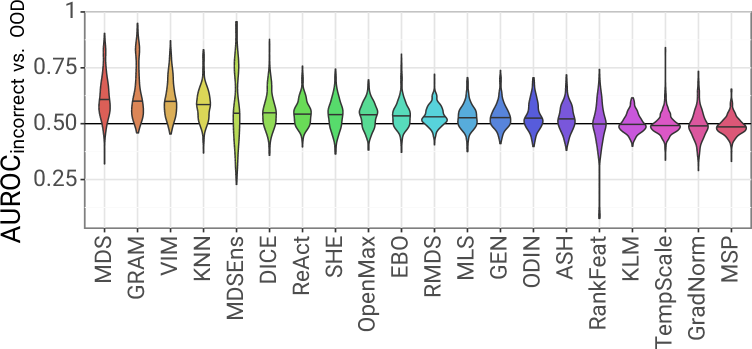
A noisy elephant in the room: Is your out-of-distribution detector robust to label noise?
Galadrielle Humblot-Renaux, Sergio Escalera, Thomas B. Moeslund
0
0
The ability to detect unfamiliar or unexpected images is essential for safe deployment of computer vision systems. In the context of classification, the task of detecting images outside of a model's training domain is known as out-of-distribution (OOD) detection. While there has been a growing research interest in developing post-hoc OOD detection methods, there has been comparably little discussion around how these methods perform when the underlying classifier is not trained on a clean, carefully curated dataset. In this work, we take a closer look at 20 state-of-the-art OOD detection methods in the (more realistic) scenario where the labels used to train the underlying classifier are unreliable (e.g. crowd-sourced or web-scraped labels). Extensive experiments across different datasets, noise types & levels, architectures and checkpointing strategies provide insights into the effect of class label noise on OOD detection, and show that poor separation between incorrectly classified ID samples vs. OOD samples is an overlooked yet important limitation of existing methods. Code: https://github.com/glhr/ood-labelnoise
4/3/2024

Gradient-Regularized Out-of-Distribution Detection
Sina Sharifi, Taha Entesari, Bardia Safaei, Vishal M. Patel, Mahyar Fazlyab
0
0
One of the challenges for neural networks in real-life applications is the overconfident errors these models make when the data is not from the original training distribution. Addressing this issue is known as Out-of-Distribution (OOD) detection. Many state-of-the-art OOD methods employ an auxiliary dataset as a surrogate for OOD data during training to achieve improved performance. However, these methods fail to fully exploit the local information embedded in the auxiliary dataset. In this work, we propose the idea of leveraging the information embedded in the gradient of the loss function during training to enable the network to not only learn a desired OOD score for each sample but also to exhibit similar behavior in a local neighborhood around each sample. We also develop a novel energy-based sampling method to allow the network to be exposed to more informative OOD samples during the training phase. This is especially important when the auxiliary dataset is large. We demonstrate the effectiveness of our method through extensive experiments on several OOD benchmarks, improving the existing state-of-the-art FPR95 by 4% on our ImageNet experiment. We further provide a theoretical analysis through the lens of certified robustness and Lipschitz analysis to showcase the theoretical foundation of our work. We will publicly release our code after the review process.
4/24/2024