Robust image representations with counterfactual contrastive learning

0
Sign in to get full access
Overview
- Researchers propose a novel contrastive learning approach called Counterfactual Contrastive Learning (CCL) to train robust image representations.
- CCL leverages counterfactual images, which are generated by modifying the original images in specific ways, to improve the model's understanding and generalization.
- The key insight is that learning to predict the original image from its counterfactual version forces the model to capture the essential visual features that are invariant to the applied transformations.
Plain English Explanation
The paper introduces a technique called Counterfactual Contrastive Learning (CCL) that can help neural networks learn more robust and generalizable representations of images.
The basic idea is to generate "counterfactual" versions of the original images by applying various transformations, such as adding noise, changing the background, or occluding parts of the image. The neural network is then trained to predict the original image from its counterfactual version.
This forces the network to focus on the essential visual features that are invariant to the applied transformations, rather than relying on superficial or context-dependent cues. As a result, the learned representations become more generalizable and less susceptible to common image corruptions or perturbations.
The researchers show that this counterfactual contrastive learning approach outperforms standard supervised and self-supervised learning methods on various image classification benchmarks, demonstrating its effectiveness in building robust and transferable image representations.
Technical Explanation
The paper introduces a novel contrastive learning approach called Counterfactual Contrastive Learning (CCL) to train more robust and generalizable image representations.
The key idea is to leverage counterfactual images, which are generated by applying various transformations to the original images, such as adding noise, changing the background, or occluding parts of the image. The neural network is then trained to predict the original image from its counterfactual version using a contrastive loss function.
This counterfactual contrastive learning objective forces the model to focus on the essential visual features that are invariant to the applied transformations, rather than relying on superficial or context-dependent cues. As a result, the learned representations become more generalizable and robust to common image corruptions or perturbations.
The researchers evaluate the CCL approach on various image classification benchmarks and show that it outperforms standard supervised and self-supervised learning methods. This demonstrates the effectiveness of counterfactual contrastive learning in building robust and transferable image representations.
Critical Analysis
The Counterfactual Contrastive Learning (CCL) approach proposed in the paper is a promising technique for improving the robustness and generalization of image representations. By leveraging counterfactual images and a contrastive learning objective, the method encourages the model to focus on the essential visual features that are invariant to common image transformations.
However, the paper does not explore the limitations or potential issues of the CCL approach in depth. For example, it would be interesting to understand how the performance of CCL scales with the complexity and diversity of the applied transformations, and whether there are any practical challenges in generating high-quality counterfactual images for real-world applications.
Additionally, the paper could have provided more insight into the specific visual features that the CCL-trained models are learning to capture, and how these representations differ from those learned by standard supervised or self-supervised approaches. Further analysis and ablation studies in this direction could shed light on the underlying mechanisms that make the CCL approach effective.
Overall, the Counterfactual Contrastive Learning (CCL) method represents an interesting and promising direction for improving the robustness and generalization of image representations. However, the limitations and potential areas for further research should be more thoroughly explored in future work.
Conclusion
The paper presents a novel Counterfactual Contrastive Learning (CCL) approach that leverages counterfactual images and a contrastive learning objective to train more robust and generalizable image representations.
The key insight is that learning to predict the original image from its counterfactual version forces the model to capture the essential visual features that are invariant to common image transformations, rather than relying on superficial or context-dependent cues.
The researchers demonstrate the effectiveness of the CCL approach through extensive experiments on various image classification benchmarks, showing that it outperforms standard supervised and self-supervised learning methods.
While the paper does not fully explore the limitations and potential issues of the CCL approach, it represents an important step forward in developing more robust and transferable image representations, with significant implications for a wide range of computer vision applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Robust image representations with counterfactual contrastive learning
M'elanie Roschewitz, Fabio De Sousa Ribeiro, Tian Xia, Galvin Khara, Ben Glocker
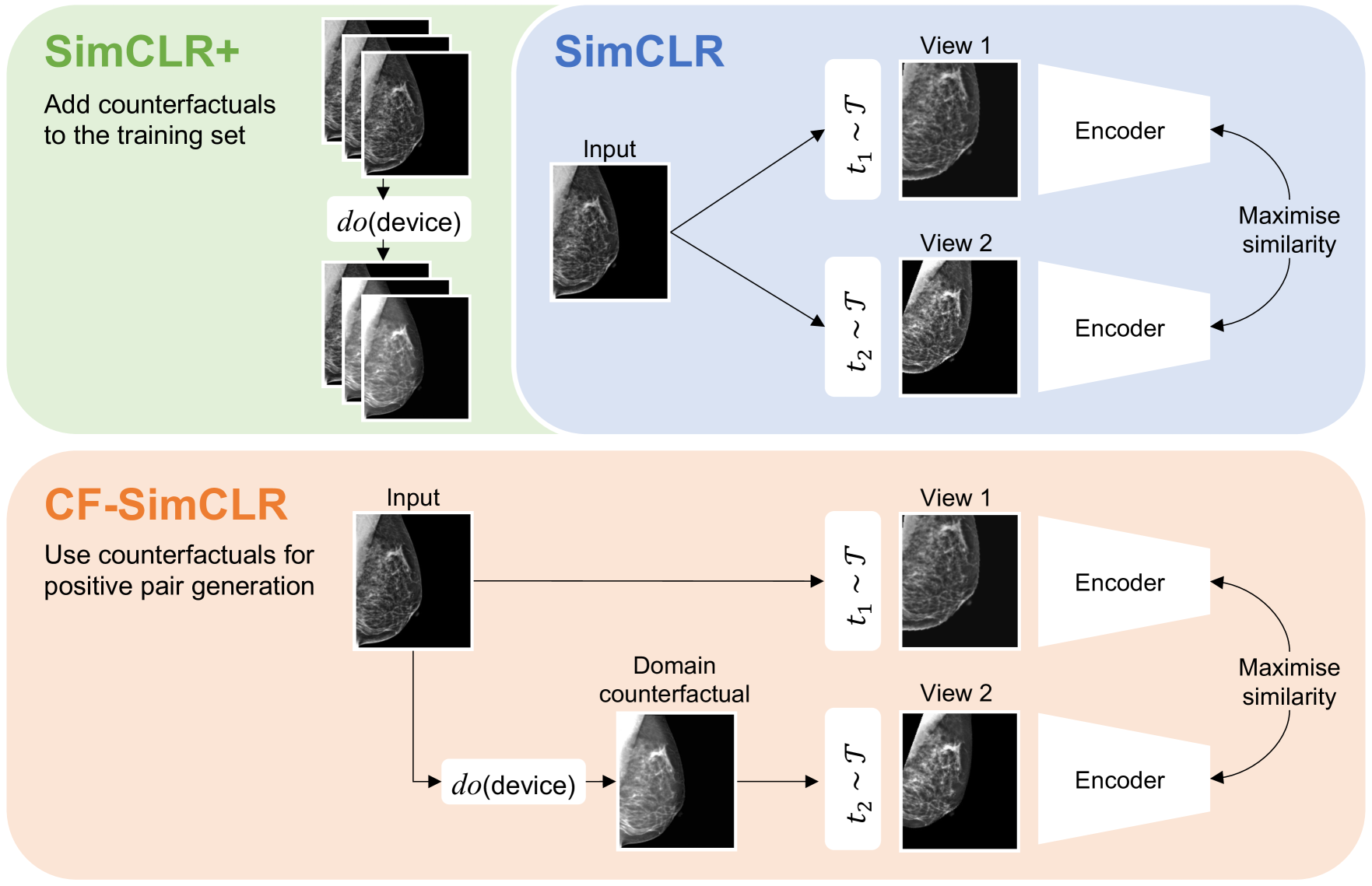
Contrastive pretraining can substantially increase model generalisation and downstream performance. However, the quality of the learned representations is highly dependent on the data augmentation strategy applied to generate positive pairs. Positive contrastive pairs should preserve semantic meaning while discarding unwanted variations related to the data acquisition domain. Traditional contrastive pipelines attempt to simulate domain shifts through pre-defined generic image transformations. However, these do not always mimic realistic and relevant domain variations for medical imaging such as scanner differences. To tackle this issue, we herein introduce counterfactual contrastive learning, a novel framework leveraging recent advances in causal image synthesis to create contrastive positive pairs that faithfully capture relevant domain variations. Our method, evaluated across five datasets encompassing both chest radiography and mammography data, for two established contrastive objectives (SimCLR and DINO-v2), outperforms standard contrastive learning in terms of robustness to acquisition shift. Notably, counterfactual contrastive learning achieves superior downstream performance on both in-distribution and on external datasets, especially for images acquired with scanners under-represented in the training set. Further experiments show that the proposed framework extends beyond acquisition shifts, with models trained with counterfactual contrastive learning substantially improving subgroup performance across biological sex.
Read more9/17/2024
0
New!Counterfactual contrastive learning: robust representations via causal image synthesis
Melanie Roschewitz, Fabio De Sousa Ribeiro, Tian Xia, Galvin Khara, Ben Glocker
Contrastive pretraining is well-known to improve downstream task performance and model generalisation, especially in limited label settings. However, it is sensitive to the choice of augmentation pipeline. Positive pairs should preserve semantic information while destroying domain-specific information. Standard augmentation pipelines emulate domain-specific changes with pre-defined photometric transformations, but what if we could simulate realistic domain changes instead? In this work, we show how to utilise recent progress in counterfactual image generation to this effect. We propose CF-SimCLR, a counterfactual contrastive learning approach which leverages approximate counterfactual inference for positive pair creation. Comprehensive evaluation across five datasets, on chest radiography and mammography, demonstrates that CF-SimCLR substantially improves robustness to acquisition shift with higher downstream performance on both in- and out-of-distribution data, particularly for domains which are under-represented during training.
Read more9/18/2024
0
Reinforcing Pre-trained Models Using Counterfactual Images
Xiang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
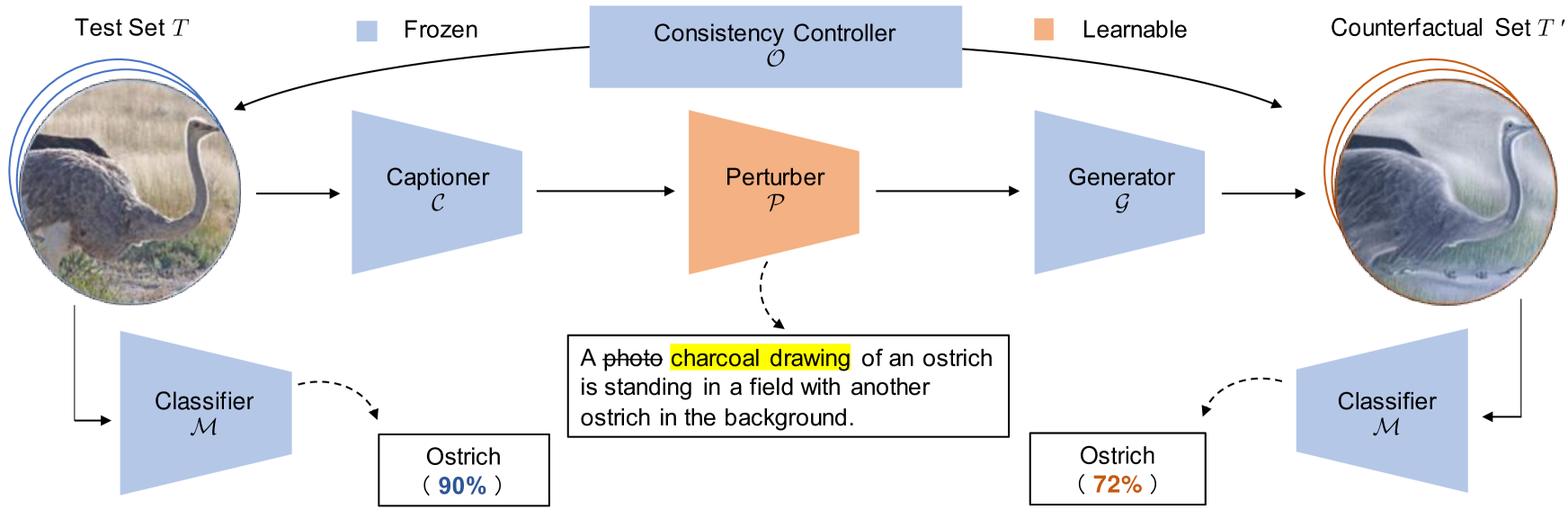
This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.
Read more6/21/2024

0
PairCFR: Enhancing Model Training on Paired Counterfactually Augmented Data through Contrastive Learning
Xiaoqi Qiu, Yongjie Wang, Xu Guo, Zhiwei Zeng, Yue Yu, Yuhong Feng, Chunyan Miao
Counterfactually Augmented Data (CAD) involves creating new data samples by applying minimal yet sufficient modifications to flip the label of existing data samples to other classes. Training with CAD enhances model robustness against spurious features that happen to correlate with labels by spreading the casual relationships across different classes. Yet, recent research reveals that training with CAD may lead models to overly focus on modified features while ignoring other important contextual information, inadvertently introducing biases that may impair performance on out-ofdistribution (OOD) datasets. To mitigate this issue, we employ contrastive learning to promote global feature alignment in addition to learning counterfactual clues. We theoretically prove that contrastive loss can encourage models to leverage a broader range of features beyond those modified ones. Comprehensive experiments on two human-edited CAD datasets demonstrate that our proposed method outperforms the state-of-the-art on OOD datasets.
Read more6/12/2024