Robust Preference Optimization with Provable Noise Tolerance for LLMs
2404.04102
0
0
Abstract
The preference alignment aims to enable large language models (LLMs) to generate responses that conform to human values, which is essential for developing general AI systems. Ranking-based methods -- a promising class of alignment approaches -- learn human preferences from datasets containing response pairs by optimizing the log-likelihood margins between preferred and dis-preferred responses. However, due to the inherent differences in annotators' preferences, ranking labels of comparisons for response pairs are unavoidably noisy. This seriously hurts the reliability of existing ranking-based methods. To address this problem, we propose a provably noise-tolerant preference alignment method, namely RObust Preference Optimization (ROPO). To the best of our knowledge, ROPO is the first preference alignment method with noise-tolerance guarantees. The key idea of ROPO is to dynamically assign conservative gradient weights to response pairs with high label uncertainty, based on the log-likelihood margins between the responses. By effectively suppressing the gradients of noisy samples, our weighting strategy ensures that the expected risk has the same gradient direction independent of the presence and proportion of noise. Experiments on three open-ended text generation tasks with four base models ranging in size from 2.8B to 13B demonstrate that ROPO significantly outperforms existing ranking-based methods.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel approach for optimizing preferences in large language models (LLMs) with provable noise tolerance.
- The method, called Robust Preference Optimization (RPO), aims to learn stable and reliable preferences from noisy human feedback, making LLMs more robust and trustworthy.
- RPO leverages techniques from online convex optimization and game theory to learn preferences that are resilient to noise and inconsistent feedback.
Plain English Explanation
The paper discusses a new way to train large language models (LLMs) to learn preferences and make decisions in a more robust and reliable way. LLMs are powerful AI systems that can generate human-like text, but they can sometimes be influenced by biased or inconsistent feedback from humans during the training process.
The researchers developed a method called Robust Preference Optimization (RPO) that helps LLMs learn stable and trustworthy preferences, even when the human feedback they receive is noisy or inconsistent. RPO uses techniques from online convex optimization and game theory to find preferences that are resilient to these types of issues.
This is important because it can help make LLMs more reliable and aligned with human values, which is crucial as these models become more powerful and influential. By training LLMs to learn preferences in a more robust way, the researchers aim to create AI systems that are less prone to biases or erratic behavior, and more likely to make decisions that are consistent with what humans actually want.
Technical Explanation
The paper introduces a novel approach called Robust Preference Optimization (RPO) for learning preferences in large language models (LLMs) that are resilient to noisy and inconsistent human feedback. RPO leverages techniques from online convex optimization and game theory to find preferences that are stable and reliable, even in the face of noisy or contradictory inputs.
The key idea behind RPO is to formulate the preference learning problem as a two-player game, where the LLM is trying to optimize its preferences, and an adversary is trying to perturb the feedback to make the LLM's preferences unstable. The LLM then learns preferences that are optimal against the worst-case perturbations from the adversary, resulting in preferences that are provably robust to noise.
The paper provides theoretical guarantees on the performance of RPO, showing that it can learn near-optimal preferences even when a constant fraction of the human feedback is corrupted. The researchers also demonstrate the effectiveness of RPO through extensive experiments on realistic preference learning tasks, where RPO outperforms alternative methods in terms of both preference quality and noise tolerance.
Critical Analysis
The paper presents a compelling approach for making large language models more robust and reliable in their preference learning. The key theoretical contributions, such as the game-theoretic formulation and the provable noise tolerance guarantees, are significant and could have a meaningful impact on the field of AI safety and alignment.
However, the paper also acknowledges some limitations and avenues for further research. For example, the current implementation of RPO assumes that the noise in the human feedback is adversarial, which may not always be the case in real-world settings. Extending the approach to handle other types of noise, such as random or structured noise, could further improve its practical applicability.
Additionally, the paper focuses on preference learning in isolation, but in many real-world scenarios, LLMs need to balance multiple objectives, such as task performance, safety, and alignment with human values. Integrating RPO into a broader framework for multi-objective optimization in LLMs could be an interesting direction for future work.
Overall, the paper presents a solid contribution to the field of AI safety and alignment, and the Robust Preference Optimization method is a promising step towards building more trustworthy and reliable large language models.
Conclusion
This paper introduces a novel approach called Robust Preference Optimization (RPO) that aims to make large language models (LLMs) more robust and reliable in their preference learning. By formulating the problem as a two-player game and leveraging techniques from online convex optimization and game theory, RPO can learn preferences that are provably resilient to noisy and inconsistent human feedback.
The theoretical guarantees and experimental results presented in the paper demonstrate the effectiveness of RPO, suggesting that it could be a valuable tool for building more trustworthy and aligned LLMs. As these models become increasingly influential, developing methods like RPO to ensure their preferences and decision-making are stable and reliable is crucial for their safe and responsible deployment.
While the paper identifies some limitations and areas for future research, the Robust Preference Optimization approach represents an important step forward in the field of AI safety and alignment, with the potential to significantly improve the robustness and trustworthiness of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Provably Robust DPO: Aligning Language Models with Noisy Feedback
Sayak Ray Chowdhury, Anush Kini, Nagarajan Natarajan
0
0
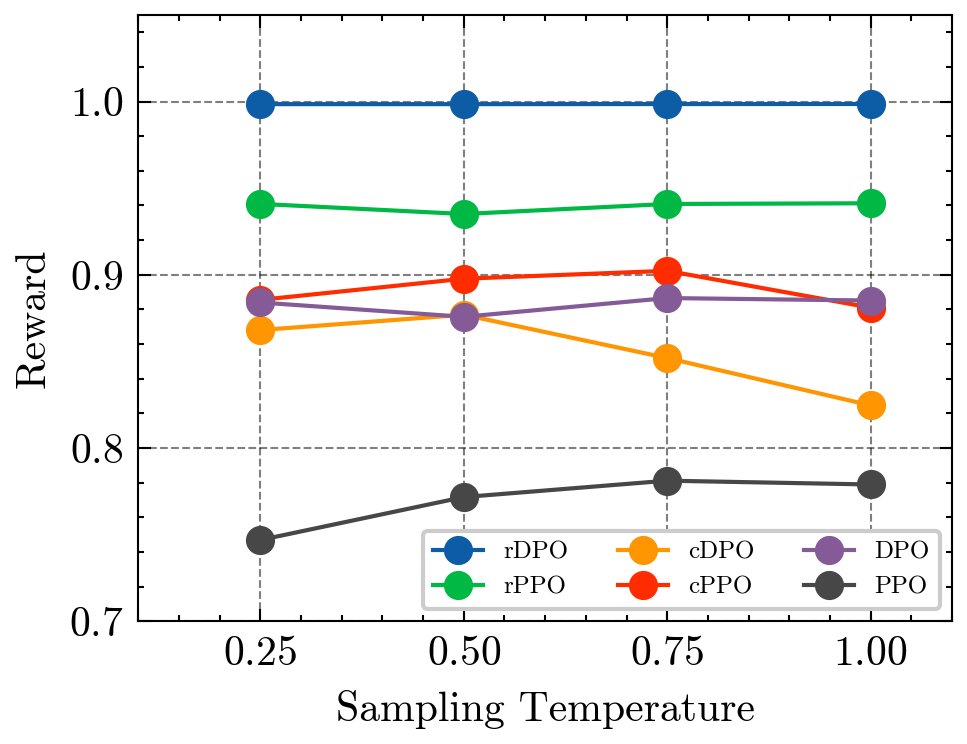
Learning from preference-based feedback has recently gained traction as a promising approach to align language models with human interests. While these aligned generative models have demonstrated impressive capabilities across various tasks, their dependence on high-quality human preference data poses a bottleneck in practical applications. Specifically, noisy (incorrect and ambiguous) preference pairs in the dataset might restrict the language models from capturing human intent accurately. While practitioners have recently proposed heuristics to mitigate the effect of noisy preferences, a complete theoretical understanding of their workings remain elusive. In this work, we aim to bridge this gap by by introducing a general framework for policy optimization in the presence of random preference flips. We focus on the direct preference optimization (DPO) algorithm in particular since it assumes that preferences adhere to the Bradley-Terry-Luce (BTL) model, raising concerns about the impact of noisy data on the learned policy. We design a novel loss function, which de-bias the effect of noise on average, making a policy trained by minimizing that loss robust to the noise. Under log-linear parameterization of the policy class and assuming good feature coverage of the SFT policy, we prove that the sub-optimality gap of the proposed robust DPO (rDPO) policy compared to the optimal policy is of the order $O(frac{1}{1-2epsilon}sqrt{frac{d}{n}})$, where $epsilon < 1/2$ is flip rate of labels, $d$ is policy parameter dimension and $n$ is size of dataset. Our experiments on IMDb sentiment generation and Anthropic's helpful-harmless dataset show that rDPO is robust to noise in preference labels compared to vanilla DPO and other heuristics proposed by practitioners.
4/15/2024
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
0
0
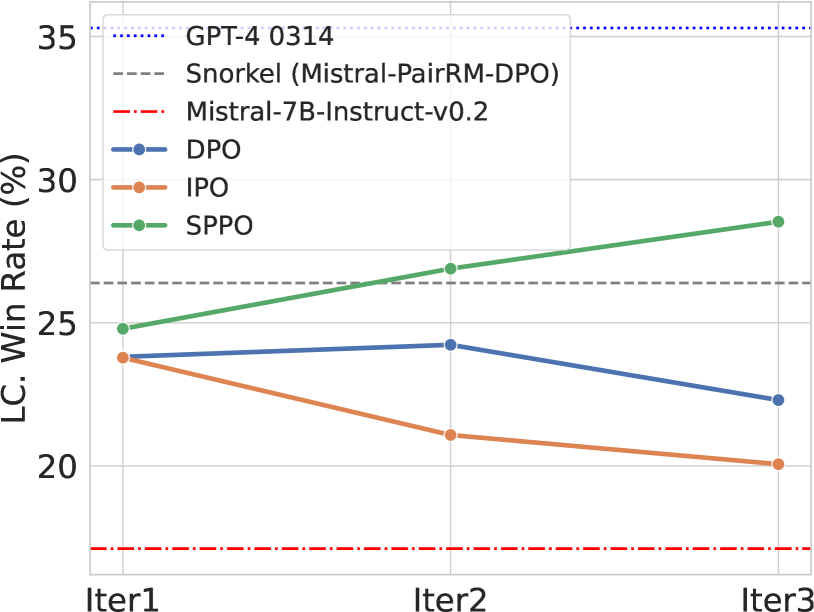
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed textit{Self-Play Preference Optimization} (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models.
5/2/2024
Impact of Preference Noise on the Alignment Performance of Generative Language Models
Yang Gao, Dana Alon, Donald Metzler
0
0
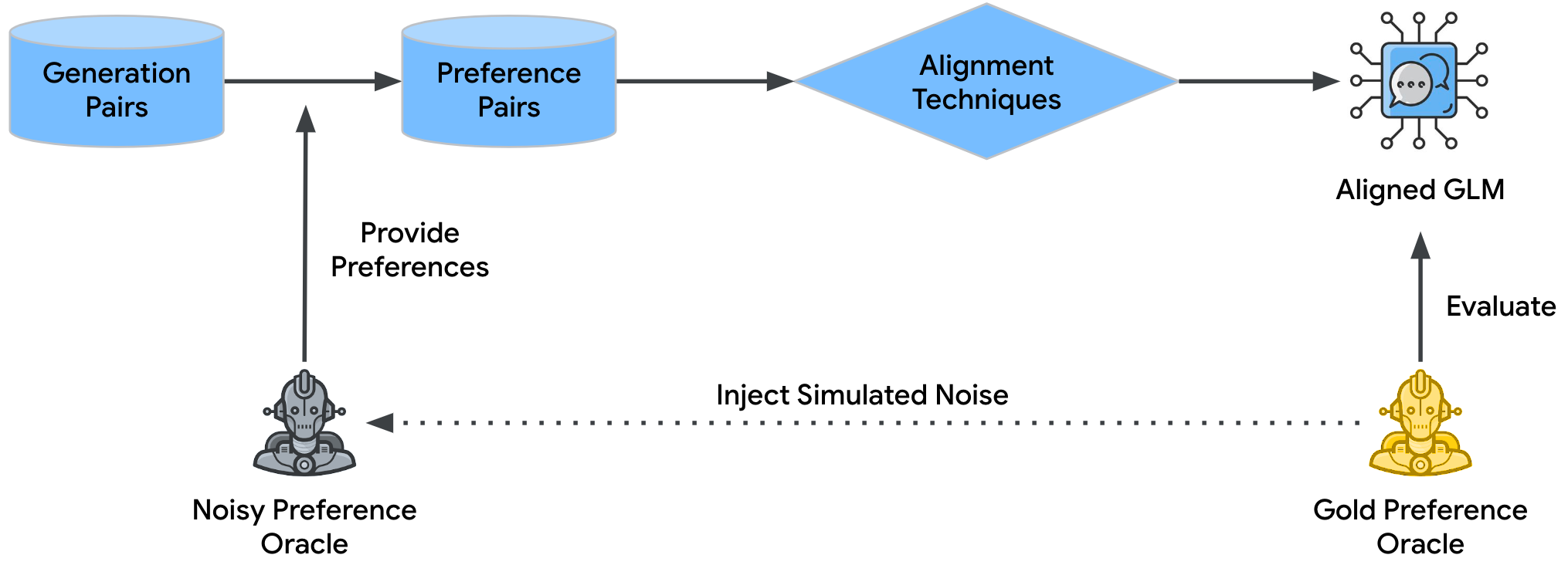
A key requirement in developing Generative Language Models (GLMs) is to have their values aligned with human values. Preference-based alignment is a widely used paradigm for this purpose, in which preferences over generation pairs are first elicited from human annotators or AI systems, and then fed into some alignment techniques, e.g., Direct Preference Optimization. However, a substantial percent (20 - 40%) of the preference pairs used in GLM alignment are noisy, and it remains unclear how the noise affects the alignment performance and how to mitigate its negative impact. In this paper, we propose a framework to inject desirable amounts and types of noise to the preferences, and systematically study the impact of preference noise on the alignment performance in two tasks (summarization and dialogue generation). We find that the alignment performance can be highly sensitive to the noise rates in the preference data: e.g., a 10 percentage points (pp) increase of the noise rate can lead to 30 pp drop in the alignment performance (in win rate). To mitigate the impact of noise, confidence-based data filtering shows significant benefit when certain types of noise are present. We hope our work can help the community better understand and mitigate the impact of preference noise in GLM alignment.
4/16/2024
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, Yi Wu
0
0
Reinforcement Learning from Human Feedback (RLHF) is currently the most widely used method to align large language models (LLMs) with human preferences. Existing RLHF methods can be roughly categorized as either reward-based or reward-free. Novel applications such as ChatGPT and Claude leverage reward-based methods that first learn a reward model and apply actor-critic algorithms, such as Proximal Policy Optimization (PPO). However, in academic benchmarks, state-of-the-art results are often achieved via reward-free methods, such as Direct Preference Optimization (DPO). Is DPO truly superior to PPO? Why does PPO perform poorly on these benchmarks? In this paper, we first conduct both theoretical and empirical studies on the algorithmic properties of DPO and show that DPO may have fundamental limitations. Moreover, we also comprehensively examine PPO and reveal the key factors for the best performances of PPO in fine-tuning LLMs. Finally, we benchmark DPO and PPO across a collection of RLHF testbeds, ranging from dialogue to code generation. Experiment results demonstrate that PPO is able to surpass other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions.
4/23/2024