Self-Play Preference Optimization for Language Model Alignment
2405.00675
0
0
Abstract
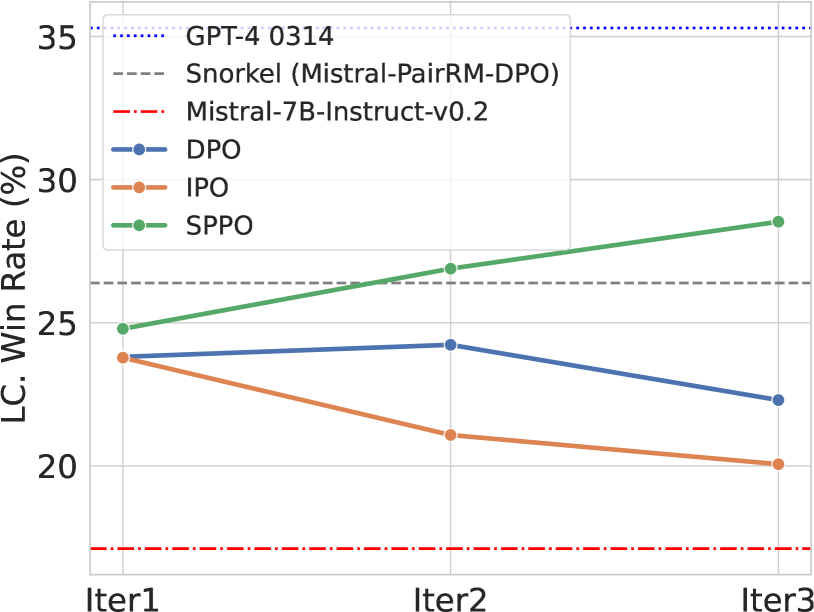
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed Self-Play Preference Optimization (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys a theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Starting from a stronger base model Llama-3-8B-Instruct, we are able to achieve a length-controlled win rate of 38.77%. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models. Codes are available at https://github.com/uclaml/SPPO.
Create account to get full access
Overview
- This paper presents a novel approach called "Self-Play Preference Optimization" (SPPO) for aligning language models with human preferences.
- The key idea is to train the language model to prefer its own outputs over alternatives, using a self-play technique.
- This aims to create a model that is well-aligned with human values and preferences, without the need for explicit reward functions or demonstrations.
Plain English Explanation
The researchers behind this paper wanted to create language models that are well-aligned with human preferences and values. Typically, this kind of alignment is achieved by training the model on a large dataset of human-written text, or by providing the model with explicit reward functions or demonstrations of desired behavior.
However, the researchers argue that these approaches have limitations. The text data may not fully capture all relevant human preferences, and designing good reward functions or demonstrations can be challenging.
Instead, the researchers propose a new technique called "Self-Play Preference Optimization" (SPPO). The key idea is to train the language model to prefer its own outputs over alternatives, using a self-play technique. In other words, the model is encouraged to generate outputs that it prefers, relative to other possible outputs.
By doing this, the researchers hope to create a language model that is well-aligned with human values and preferences, without the need for explicit reward functions or demonstrations. The model essentially learns to "think like a human" by optimizing for its own preferences.
This approach builds on related work in self-play and preference learning, and aims to improve upon existing techniques for aligning language models with human values.
Technical Explanation
The core idea of the SPPO approach is to train the language model to prefer its own outputs over alternatives, using a self-play technique. Specifically, the model is presented with a prompt and generates a candidate output. It then evaluates the relative preference between its own output and one or more alternative outputs, and is trained to increase the preference for its own output.
This preference optimization is done at the token level, where the model compares the likelihood of its own token-by-token generation versus alternative tokens. This builds on prior work in direct preference optimization (DPO) for language model alignment.
The researchers experiment with different preference modeling techniques, including relative preference and absolute preference. They also explore ways to make the preference optimization more robust, such as by introducing noise into the alternative outputs.
Through extensive experimentation, the researchers demonstrate that the SPPO approach can effectively align language models with human preferences, outperforming various baseline techniques. They analyze the properties of the aligned models and discuss potential applications and limitations of the approach.
Critical Analysis
The SPPO approach presented in this paper is a novel and promising technique for aligning language models with human preferences. By training the model to prefer its own outputs, it aims to capture a more holistic representation of human values, rather than relying on explicit reward functions or demonstrations.
However, the paper acknowledges several caveats and limitations of the approach. For example, the preference optimization is still ultimately based on the training data, which may not fully reflect all relevant human preferences. Additionally, the preference modeling techniques used in the experiments may not be fully robust to potential issues like distributional shift or adversarial attacks.
Further research is needed to address these limitations and explore ways to make the SPPO approach more reliable and scalable. Potential areas for future work include investigating more sophisticated preference modeling techniques, exploring ways to incorporate external knowledge or feedback into the preference learning process, and studying the long-term stability and generalization of the aligned models.
Overall, this paper presents an interesting and potentially impactful contribution to the field of language model alignment. While the approach has some limitations, it represents an important step towards developing more human-aligned AI systems.
Conclusion
The "Self-Play Preference Optimization" (SPPO) approach proposed in this paper offers a novel way to align language models with human preferences and values. By training the model to prefer its own outputs over alternatives, the researchers aim to capture a more holistic representation of human preferences, without the need for explicit reward functions or demonstrations.
The technical details of the SPPO approach, including the various preference modeling techniques explored, demonstrate the researchers' rigorous and thoughtful approach to the problem. While the paper acknowledges some limitations and caveats, the experimental results suggest that the SPPO approach can be an effective tool for aligning language models with human preferences.
As the field of AI continues to grapple with the challenge of developing systems that are well-aligned with human values, this paper represents an important contribution that could have significant implications for the future of language models and their application in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Investigating Regularization of Self-Play Language Models
Reda Alami, Abdalgader Abubaker, Mastane Achab, Mohamed El Amine Seddik, Salem Lahlou
0
0
This paper explores the effects of various forms of regularization in the context of language model alignment via self-play. While both reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) require to collect costly human-annotated pairwise preferences, the self-play fine-tuning (SPIN) approach replaces the rejected answers by data generated from the previous iterate. However, the SPIN method presents a performance instability issue in the learning phase, which can be mitigated by playing against a mixture of the two previous iterates. In the same vein, we propose in this work to address this issue from two perspectives: first, by incorporating an additional Kullback-Leibler (KL) regularization to stay at the proximity of the reference policy; second, by using the idea of fictitious play which smoothens the opponent policy across all previous iterations. In particular, we show that the KL-based regularizer boils down to replacing the previous policy by its geometric mixture with the base policy inside of the SPIN loss function. We finally discuss empirical results on MT-Bench as well as on the Hugging Face Open LLM Leaderboard.
4/9/2024
💬
Self-Play with Adversarial Critic: Provable and Scalable Offline Alignment for Language Models
Xiang Ji, Sanjeev Kulkarni, Mengdi Wang, Tengyang Xie
0
0
This work studies the challenge of aligning large language models (LLMs) with offline preference data. We focus on alignment by Reinforcement Learning from Human Feedback (RLHF) in particular. While popular preference optimization methods exhibit good empirical performance in practice, they are not theoretically guaranteed to converge to the optimal policy and can provably fail when the data coverage is sparse by classical offline reinforcement learning (RL) results. On the other hand, a recent line of work has focused on theoretically motivated preference optimization methods with provable guarantees, but these are not computationally efficient for large-scale applications like LLM alignment. To bridge this gap, we propose SPAC, a new offline preference optimization method with self-play, inspired by the on-average pessimism technique from the offline RL literature, to be the first provable and scalable approach to LLM alignment. We both provide theoretical analysis for its convergence under single-policy concentrability for the general function approximation setting and demonstrate its competitive empirical performance for LLM alignment on a 7B Mistral model with Open LLM Leaderboard evaluations.
6/7/2024
Self-Augmented Preference Optimization: Off-Policy Paradigms for Language Model Alignment
Yueqin Yin, Zhendong Wang, Yujia Xie, Weizhu Chen, Mingyuan Zhou
0
0
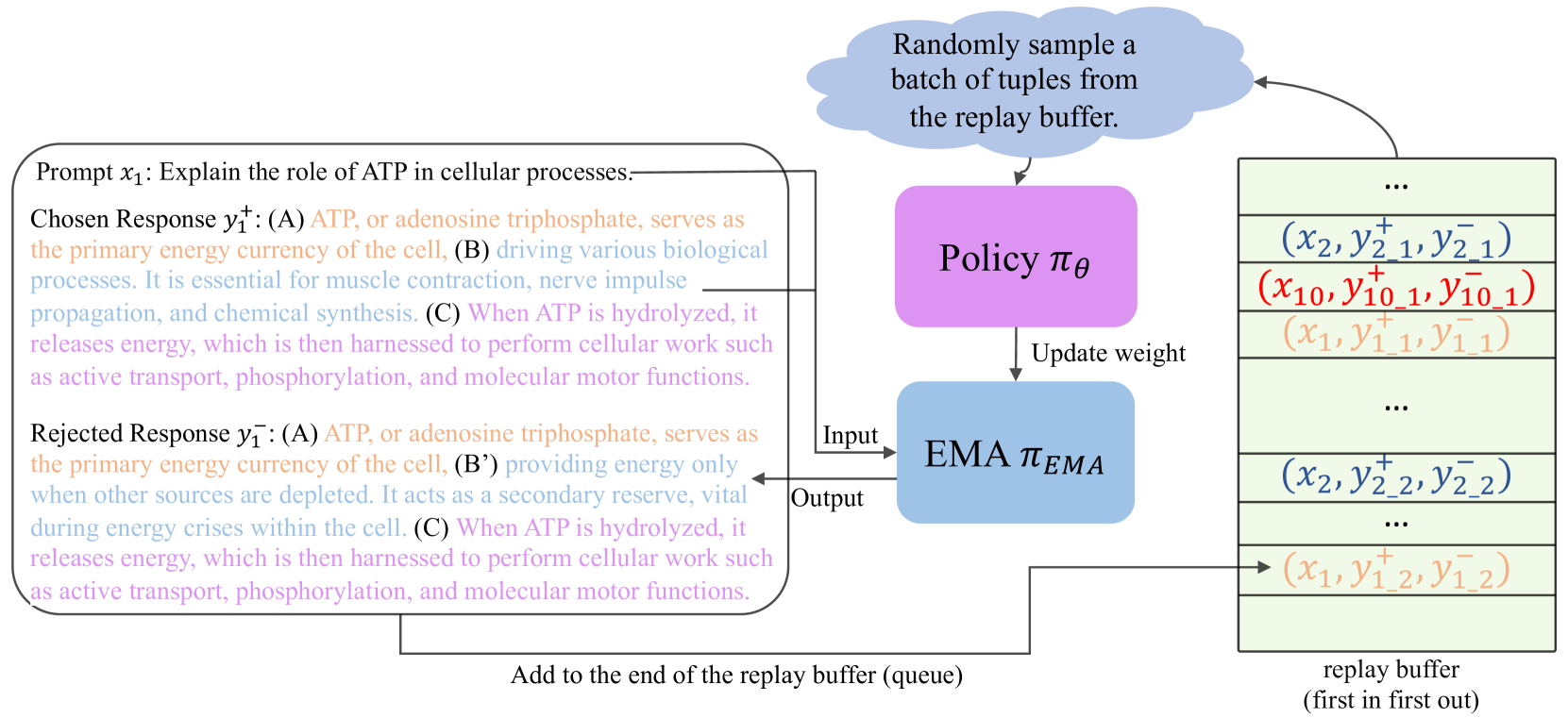
Traditional language model alignment methods, such as Direct Preference Optimization (DPO), are limited by their dependence on static, pre-collected paired preference data, which hampers their adaptability and practical applicability. To overcome this limitation, we introduce Self-Augmented Preference Optimization (SAPO), an effective and scalable training paradigm that does not require existing paired data. Building on the self-play concept, which autonomously generates negative responses, we further incorporate an off-policy learning pipeline to enhance data exploration and exploitation. Specifically, we employ an Exponential Moving Average (EMA) model in conjunction with a replay buffer to enable dynamic updates of response segments, effectively integrating real-time feedback with insights from historical data. Our comprehensive evaluations of the LLaMA3-8B and Mistral-7B models across benchmarks, including the Open LLM Leaderboard, IFEval, AlpacaEval 2.0, and MT-Bench, demonstrate that SAPO matches or surpasses established offline contrastive baselines, such as DPO and Odds Ratio Preference Optimization, and outperforms offline self-play methods like SPIN. Our code is available at https://github.com/yinyueqin/SAPO
6/3/2024
Soft Preference Optimization: Aligning Language Models to Expert Distributions
Arsalan Sharifnassab, Sina Ghiassian, Saber Salehkaleybar, Surya Kanoria, Dale Schuurmans
0
0
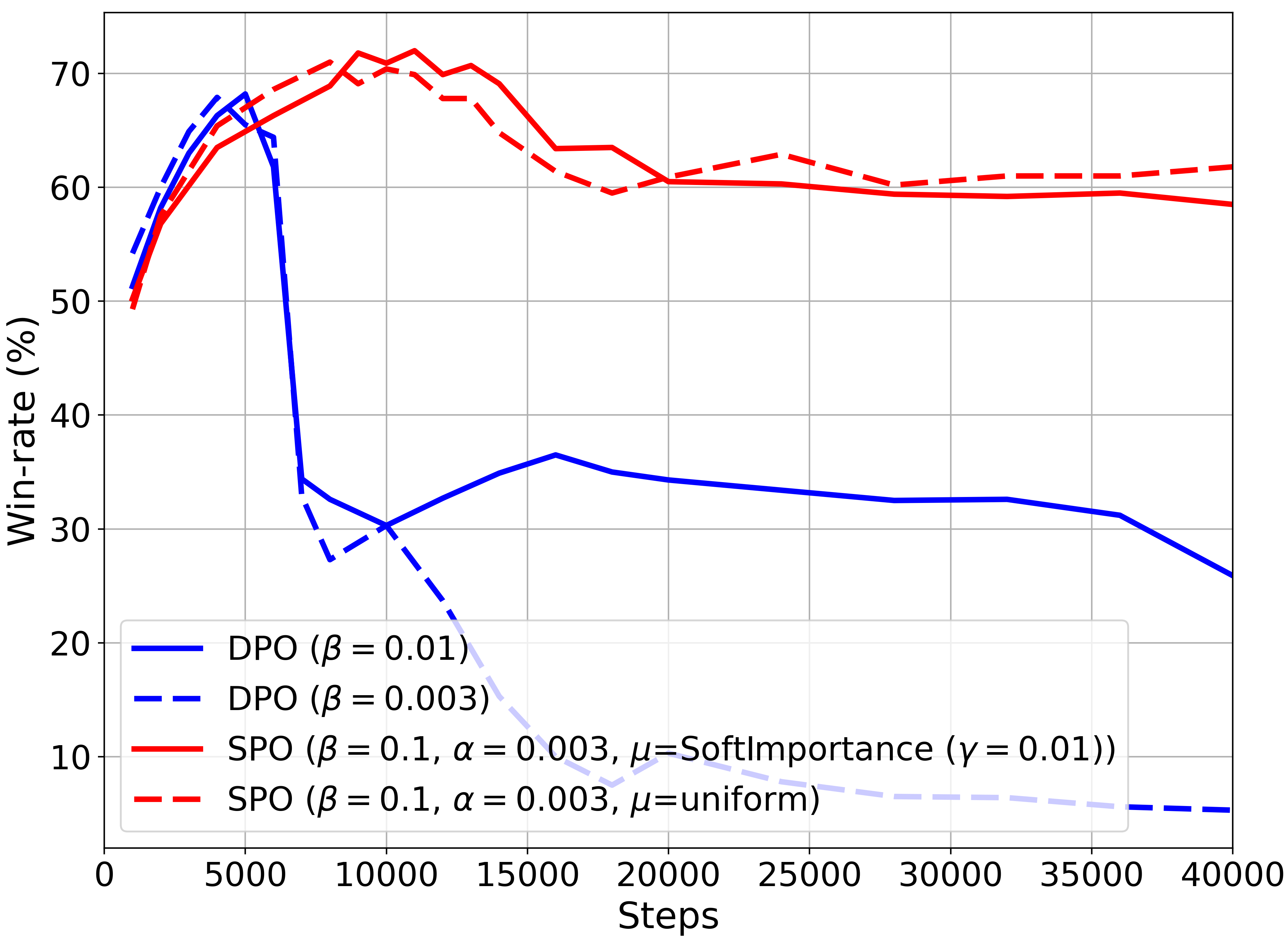
We propose Soft Preference Optimization (SPO), a method for aligning generative models, such as Large Language Models (LLMs), with human preferences, without the need for a reward model. SPO optimizes model outputs directly over a preference dataset through a natural loss function that integrates preference loss with a regularization term across the model's entire output distribution rather than limiting it to the preference dataset. Although SPO does not require the assumption of an existing underlying reward model, we demonstrate that, under the Bradley-Terry (BT) model assumption, it converges to a softmax of scaled rewards, with the distribution's softness adjustable via the softmax exponent, an algorithm parameter. We showcase SPO's methodology, its theoretical foundation, and its comparative advantages in simplicity, computational efficiency, and alignment precision.
5/29/2024