Robust Training of Neural Networks at Arbitrary Precision and Sparsity

0

Sign in to get full access
Overview
- Explores techniques for training neural networks with arbitrary precision and sparsity
- Aims to improve the robustness and efficiency of neural networks
- Presents a novel training approach that can produce models with customizable bit-widths and sparsity levels
Plain English Explanation
This research paper explores new ways to train neural networks that can be configured with different levels of precision and sparsity. The goal is to create neural network models that are more robust and efficient than traditional approaches.
The researchers present a novel training method that allows them to produce neural network models with customizable bit-widths (the number of bits used to represent each number) and sparsity levels (how many of the model's parameters are set to zero). This provides a lot of flexibility in how the final model is structured, which can lead to improvements in performance, efficiency, and robustness.
Technical Explanation
The paper introduces a training approach called Robust Training of Neural Networks at Arbitrary Precision and Sparsity (RTAPS). RTAPS enables the training of neural networks with customizable bit-widths and sparsity levels.
The key innovations include:
- Adaptive Precision Training: Dynamically adjusts the bit-widths of neural network parameters during training to find the optimal precision for each layer.
- Sparse Gradient Clipping: Applies selective gradient clipping to encourage sparsity in the trained model.
- Regularization Techniques: Uses a combination of L1 and L2 regularization to control the sparsity and bit-widths of the final model.
Through extensive experiments, the authors demonstrate that RTAPS can produce neural network models with high accuracy, low memory footprint, and improved robustness compared to standard training approaches.
Critical Analysis
The paper provides a thorough exploration of techniques for training neural networks with customizable precision and sparsity. The proposed RTAPS method shows promising results, but the authors acknowledge some limitations:
- The training process is more computationally intensive than standard approaches, which could be a barrier for certain applications.
- The optimal trade-offs between accuracy, sparsity, and precision may vary depending on the specific use case, so further research is needed to fully understand the practical implications.
- The authors only evaluated RTAPS on image classification tasks, so its effectiveness on other problem domains remains to be seen.
Overall, the research represents an interesting step forward in the ongoing effort to make neural networks more efficient, robust, and adaptable to diverse hardware and deployment constraints.
Conclusion
This paper presents a novel training approach, RTAPS, that enables the creation of neural network models with customizable precision and sparsity levels. By providing this level of configurability, the researchers aim to improve the robustness and efficiency of neural networks, which could have significant implications for a wide range of AI applications.
The techniques demonstrated in this work contribute to the ongoing advancements in neural network architecture design and training, helping to make these powerful models more versatile and practical for real-world use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Robust Training of Neural Networks at Arbitrary Precision and Sparsity
Chengxi Ye, Grace Chu, Yanfeng Liu, Yichi Zhang, Lukasz Lew, Andrew Howard
The discontinuous operations inherent in quantization and sparsification introduce obstacles to backpropagation. This is particularly challenging when training deep neural networks in ultra-low precision and sparse regimes. We propose a novel, robust, and universal solution: a denoising affine transform that stabilizes training under these challenging conditions. By formulating quantization and sparsification as perturbations during training, we derive a perturbation-resilient approach based on ridge regression. Our solution employs a piecewise constant backbone model to ensure a performance lower bound and features an inherent noise reduction mechanism to mitigate perturbation-induced corruption. This formulation allows existing models to be trained at arbitrarily low precision and sparsity levels with off-the-shelf recipes. Furthermore, our method provides a novel perspective on training temporal binary neural networks, contributing to ongoing efforts to narrow the gap between artificial and biological neural networks.
Read more9/17/2024

0
Enhancing Adversarial Robustness in SNNs with Sparse Gradients
Yujia Liu, Tong Bu, Jianhao Ding, Zecheng Hao, Tiejun Huang, Zhaofei Yu
Spiking Neural Networks (SNNs) have attracted great attention for their energy-efficient operations and biologically inspired structures, offering potential advantages over Artificial Neural Networks (ANNs) in terms of energy efficiency and interpretability. Nonetheless, similar to ANNs, the robustness of SNNs remains a challenge, especially when facing adversarial attacks. Existing techniques, whether adapted from ANNs or specifically designed for SNNs, exhibit limitations in training SNNs or defending against strong attacks. In this paper, we propose a novel approach to enhance the robustness of SNNs through gradient sparsity regularization. We observe that SNNs exhibit greater resilience to random perturbations compared to adversarial perturbations, even at larger scales. Motivated by this, we aim to narrow the gap between SNNs under adversarial and random perturbations, thereby improving their overall robustness. To achieve this, we theoretically prove that this performance gap is upper bounded by the gradient sparsity of the probability associated with the true label concerning the input image, laying the groundwork for a practical strategy to train robust SNNs by regularizing the gradient sparsity. We validate the effectiveness of our approach through extensive experiments on both image-based and event-based datasets. The results demonstrate notable improvements in the robustness of SNNs. Our work highlights the importance of gradient sparsity in SNNs and its role in enhancing robustness.
Read more6/3/2024

0
Joint Pruning and Channel-wise Mixed-Precision Quantization for Efficient Deep Neural Networks
Beatrice Alessandra Motetti, Matteo Risso, Alessio Burrello, Enrico Macii, Massimo Poncino, Daniele Jahier Pagliari
The resource requirements of deep neural networks (DNNs) pose significant challenges to their deployment on edge devices. Common approaches to address this issue are pruning and mixed-precision quantization, which lead to latency and memory occupation improvements. These optimization techniques are usually applied independently. We propose a novel methodology to apply them jointly via a lightweight gradient-based search, and in a hardware-aware manner, greatly reducing the time required to generate Pareto-optimal DNNs in terms of accuracy versus cost (i.e., latency or memory). We test our approach on three edge-relevant benchmarks, namely CIFAR-10, Google Speech Commands, and Tiny ImageNet. When targeting the optimization of the memory footprint, we are able to achieve a size reduction of 47.50% and 69.54% at iso-accuracy with the baseline networks with all weights quantized at 8 and 2-bit, respectively. Our method surpasses a previous state-of-the-art approach with up to 56.17% size reduction at iso-accuracy. With respect to the sequential application of state-of-the-art pruning and mixed-precision optimizations, we obtain comparable or superior results, but with a significantly lowered training time. In addition, we show how well-tailored cost models can improve the cost versus accuracy trade-offs when targeting specific hardware for deployment.
Read more7/2/2024
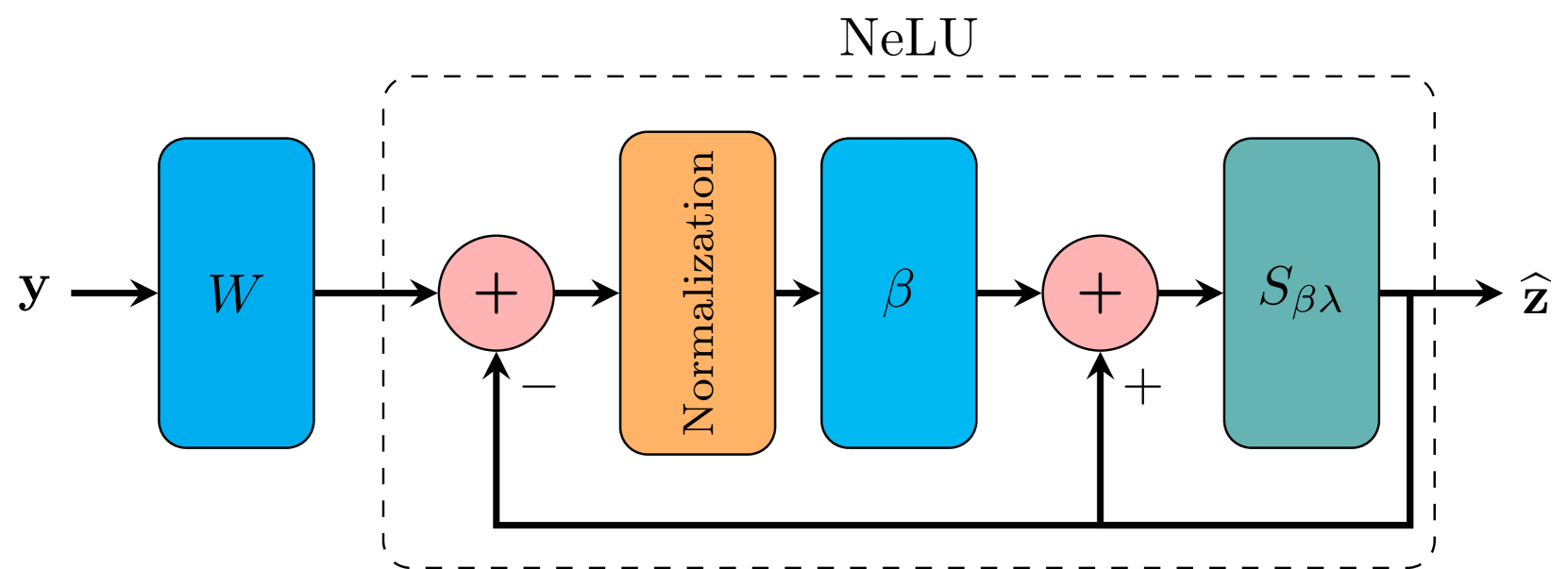
0
Pivotal Auto-Encoder via Self-Normalizing ReLU
Nelson Goldenstein, Jeremias Sulam, Yaniv Romano
Sparse auto-encoders are useful for extracting low-dimensional representations from high-dimensional data. However, their performance degrades sharply when the input noise at test time differs from the noise employed during training. This limitation hinders the applicability of auto-encoders in real-world scenarios where the level of noise in the input is unpredictable. In this paper, we formalize single hidden layer sparse auto-encoders as a transform learning problem. Leveraging the transform modeling interpretation, we propose an optimization problem that leads to a predictive model invariant to the noise level at test time. In other words, the same pre-trained model is able to generalize to different noise levels. The proposed optimization algorithm, derived from the square root lasso, is translated into a new, computationally efficient auto-encoding architecture. After proving that our new method is invariant to the noise level, we evaluate our approach by training networks using the proposed architecture for denoising tasks. Our experimental results demonstrate that the trained models yield a significant improvement in stability against varying types of noise compared to commonly used architectures.
Read more6/26/2024