Robustness to Subpopulation Shift with Domain Label Noise via Regularized Annotation of Domains
2402.11039
0
0

Abstract
Existing methods for last layer retraining that aim to optimize worst-group accuracy (WGA) rely heavily on well-annotated groups in the training data. We show, both in theory and practice, that annotation-based data augmentations using either downsampling or upweighting for WGA are susceptible to domain annotation noise, and in high-noise regimes approach the WGA of a model trained with vanilla empirical risk minimization. We introduce Regularized Annotation of Domains (RAD) in order to train robust last layer classifiers without the need for explicit domain annotations. Our results show that RAD is competitive with other recently proposed domain annotation-free techniques. Most importantly, RAD outperforms state-of-the-art annotation-reliant methods even with only 5% noise in the training data for several publicly available datasets.
Create account to get full access
Overview
- This paper proposes a method to improve the robustness of machine learning models to subpopulation shift and domain label noise.
- The key idea is to leverage regularized annotation of domains to improve model performance in the presence of these challenges.
- The authors demonstrate the effectiveness of their approach on various benchmark datasets.
Plain English Explanation
Machine learning models are often trained on datasets that do not fully represent the real-world distribution of data they will encounter when deployed. This can lead to poor performance when the model is exposed to "subpopulation shift" - situations where the data distribution differs from the training data.
Additionally, the labels used to train these models may themselves contain errors or noise, further complicating the learning process. This "domain label noise" can also negatively impact model performance.
To address these challenges, the researchers in this paper have developed a new technique that involves annotating the "domain" - or underlying data distribution - of the training samples. By regularizing this domain annotation, the model is encouraged to learn features that are robust to subpopulation shift and domain label noise.
The authors show that this approach leads to significant performance improvements on a variety of benchmark datasets, outperforming other methods designed to address similar challenges.
Technical Explanation
The key technical contributions of this paper are:
-
A novel regularization method that encourages the model to learn domain-invariant features. This is accomplished by adding a regularization term to the loss function that penalizes the model for not accurately predicting the domain of each training sample.
-
A training procedure that iterates between updating the model parameters and annotating the domain labels of the training data. This allows the model and domain annotations to co-evolve, leading to improved robustness.
-
Extensive experiments on benchmark datasets demonstrating the effectiveness of the proposed approach in improving performance under subpopulation shift and domain label noise, compared to baseline methods.
The authors also provide interesting insights into the mechanisms by which their approach improves robustness, including the ability to learn more generalizable features and better calibrate predictions.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear technical contribution and strong empirical results. However, a few potential limitations and areas for future research are worth noting:
-
The approach relies on having access to domain annotations for the training data, which may not always be available in practice. Further research is needed to explore unsupervised or weakly supervised methods for inferring domain information.
-
The experiments are conducted on relatively controlled benchmark datasets, and it's unclear how the method would scale or perform on larger, more complex real-world datasets with noisier data and a wider range of subpopulation shifts.
-
The paper does not address potential fairness or ethical concerns that may arise from the proposed approach, such as the risk of exacerbating biases or discriminating against certain subpopulations. Further investigation in this direction would be valuable.
Overall, this paper makes an important contribution to the field of robust and domain-agnostic machine learning, and the proposed techniques could have significant practical applications. However, as with any research, there are opportunities for continued improvement and exploration.
Conclusion
This paper presents a novel approach to improving the robustness of machine learning models to subpopulation shift and domain label noise. By leveraging regularized annotation of domains, the authors demonstrate significant performance gains on benchmark datasets, outperforming existing methods.
The technical insights and empirical findings in this work could have broad implications for the development of more reliable and fair AI systems that can better generalize to diverse real-world scenarios. While the current approach has some limitations, the overall contribution represents an important step forward in the field of robust and domain-agnostic machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
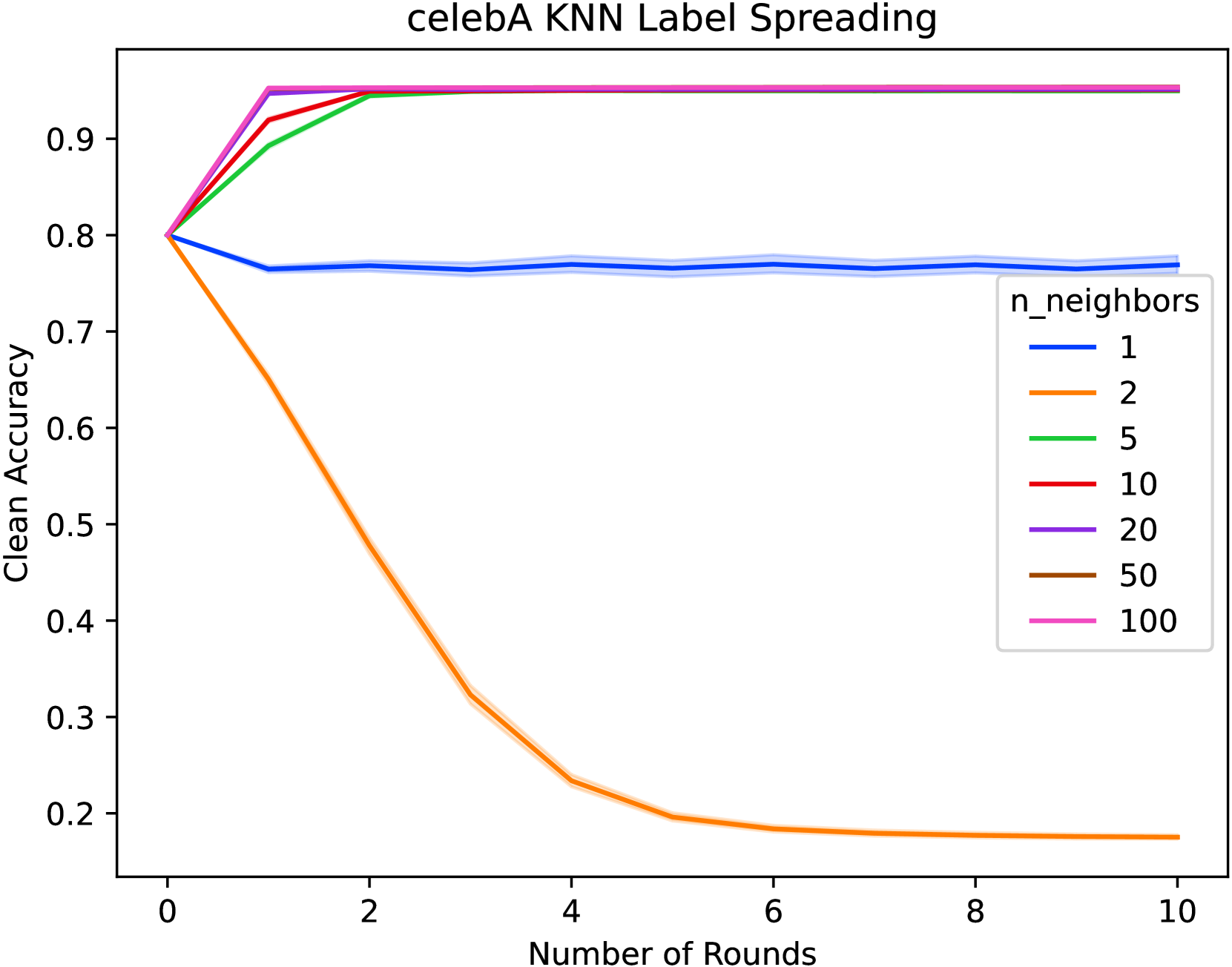
Label Noise Robustness for Domain-Agnostic Fair Corrections via Nearest Neighbors Label Spreading
Nathan Stromberg, Rohan Ayyagari, Sanmi Koyejo, Richard Nock, Lalitha Sankar
0
0
Last-layer retraining methods have emerged as an efficient framework for correcting existing base models. Within this framework, several methods have been proposed to deal with correcting models for subgroup fairness with and without group membership information. Importantly, prior work has demonstrated that many methods are susceptible to noisy labels. To this end, we propose a drop-in correction for label noise in last-layer retraining, and demonstrate that it achieves state-of-the-art worst-group accuracy for a broad range of symmetric label noise and across a wide variety of datasets exhibiting spurious correlations. Our proposed approach uses label spreading on a latent nearest neighbors graph and has minimal computational overhead compared to existing methods.
6/17/2024
📈
Label Alignment Regularization for Distribution Shift
Ehsan Imani, Guojun Zhang, Runjia Li, Jun Luo, Pascal Poupart, Philip H. S. Torr, Yangchen Pan
0
0
Recent work has highlighted the label alignment property (LAP) in supervised learning, where the vector of all labels in the dataset is mostly in the span of the top few singular vectors of the data matrix. Drawing inspiration from this observation, we propose a regularization method for unsupervised domain adaptation that encourages alignment between the predictions in the target domain and its top singular vectors. Unlike conventional domain adaptation approaches that focus on regularizing representations, we instead regularize the classifier to align with the unsupervised target data, guided by the LAP in both the source and target domains. Theoretical analysis demonstrates that, under certain assumptions, our solution resides within the span of the top right singular vectors of the target domain data and aligns with the optimal solution. By removing the reliance on the commonly used optimal joint risk assumption found in classic domain adaptation theory, we showcase the effectiveness of our method on addressing problems where traditional domain adaptation methods often fall short due to high joint error. Additionally, we report improved performance over domain adaptation baselines in well-known tasks such as MNIST-USPS domain adaptation and cross-lingual sentiment analysis.
6/12/2024
🛸
Towards Robust Domain Generation Algorithm Classification
Arthur Drichel, Marc Meyer, Ulrike Meyer
0
0
In this work, we conduct a comprehensive study on the robustness of domain generation algorithm (DGA) classifiers. We implement 32 white-box attacks, 19 of which are very effective and induce a false-negative rate (FNR) of $approx$ 100% on unhardened classifiers. To defend the classifiers, we evaluate different hardening approaches and propose a novel training scheme that leverages adversarial latent space vectors and discretized adversarial domains to significantly improve robustness. In our study, we highlight a pitfall to avoid when hardening classifiers and uncover training biases that can be easily exploited by attackers to bypass detection, but which can be mitigated by adversarial training (AT). In our study, we do not observe any trade-off between robustness and performance, on the contrary, hardening improves a classifier's detection performance for known and unknown DGAs. We implement all attacks and defenses discussed in this paper as a standalone library, which we make publicly available to facilitate hardening of DGA classifiers: https://gitlab.com/rwth-itsec/robust-dga-detection
4/10/2024
📈
Learning from SAM: Harnessing a Foundation Model for Sim2Real Adaptation by Regularization
Mayara E. Bonani, Max Schwarz, Sven Behnke
0
0
Domain adaptation is especially important for robotics applications, where target domain training data is usually scarce and annotations are costly to obtain. We present a method for self-supervised domain adaptation for the scenario where annotated source domain data (e.g. from synthetic generation) is available, but the target domain data is completely unannotated. Our method targets the semantic segmentation task and leverages a segmentation foundation model (Segment Anything Model) to obtain segment information on unannotated data. We take inspiration from recent advances in unsupervised local feature learning and propose an invariance-variance loss over the detected segments for regularizing feature representations in the target domain. Crucially, this loss structure and network architecture can handle overlapping segments and oversegmentation as produced by Segment Anything. We demonstrate the advantage of our method on the challenging YCB-Video and HomebrewedDB datasets and show that it outperforms prior work and, on YCB-Video, even a network trained with real annotations. Additionally, we provide insight through model ablations and show applicability to a custom robotic application.
5/13/2024