Label Noise Robustness for Domain-Agnostic Fair Corrections via Nearest Neighbors Label Spreading
2406.09561
0
0
Abstract
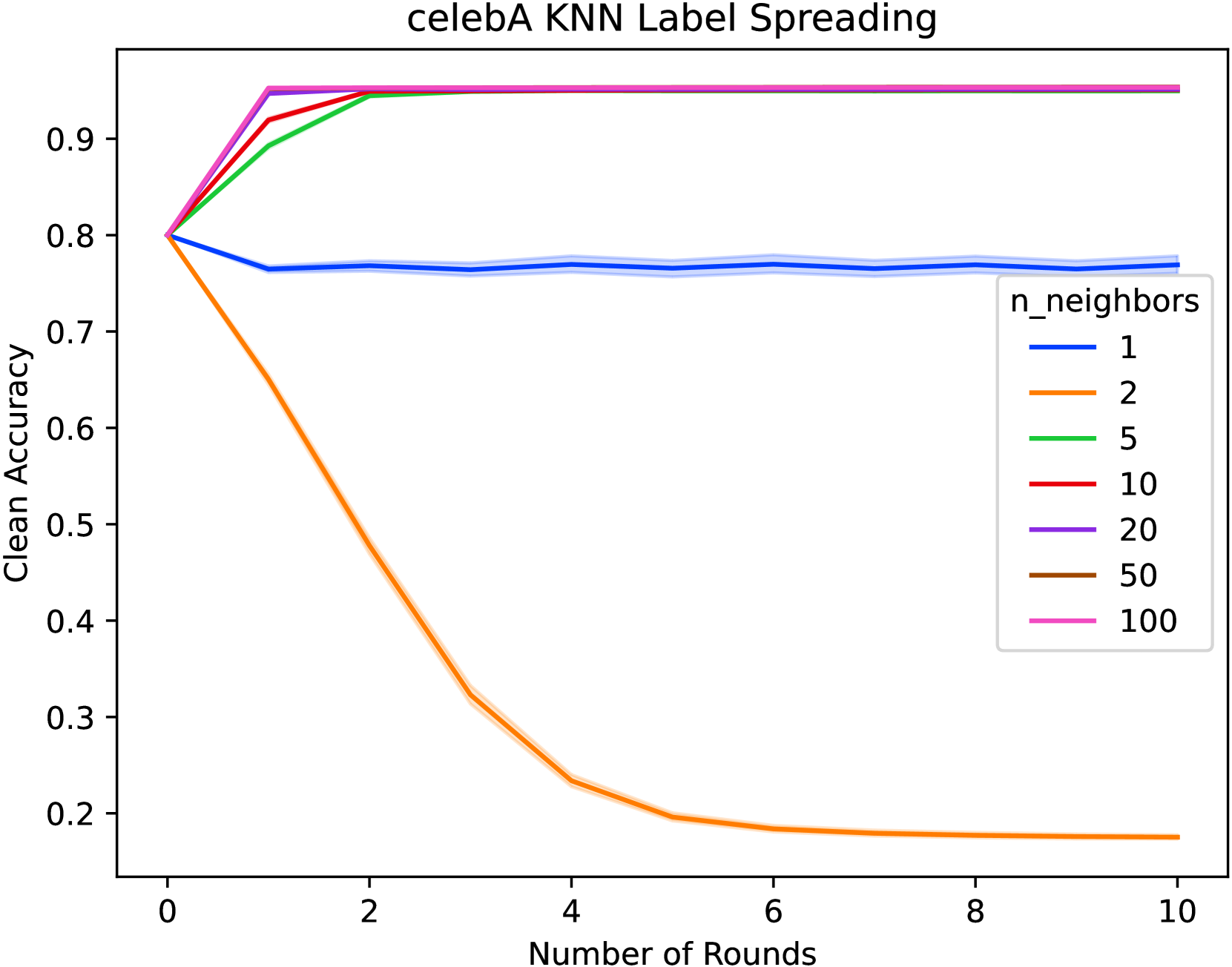
Last-layer retraining methods have emerged as an efficient framework for correcting existing base models. Within this framework, several methods have been proposed to deal with correcting models for subgroup fairness with and without group membership information. Importantly, prior work has demonstrated that many methods are susceptible to noisy labels. To this end, we propose a drop-in correction for label noise in last-layer retraining, and demonstrate that it achieves state-of-the-art worst-group accuracy for a broad range of symmetric label noise and across a wide variety of datasets exhibiting spurious correlations. Our proposed approach uses label spreading on a latent nearest neighbors graph and has minimal computational overhead compared to existing methods.
Create account to get full access
Overview
- Proposes a method for making machine learning models more robust to noisy or inaccurate labels in training data
- Focuses on ensuring fair and unbiased predictions, even when the training data contains biases or errors
- Uses a nearest neighbors approach to "spread" label information and correct noisy labels
Plain English Explanation
This paper introduces a new technique for training machine learning models to be more robust to label noise. The key idea is to use the nearest neighbors of each data point to "spread" the label information and correct any noisy or inaccurate labels in the training data.
The motivation is that real-world datasets often contain biases or errors in the way the data is labeled. This can lead to machine learning models learning these biases and making unfair or inaccurate predictions. By correcting the noisy labels, the model can learn a more robust and unbiased representation of the data.
The authors demonstrate that their approach can outperform previous methods for robust classification with noisy labels, while also ensuring the fairness and unbiasedness of the resulting predictions.
Technical Explanation
The key technical innovation in this paper is a nearest neighbors label spreading approach for correcting noisy labels. The method works by first identifying the nearest neighbors of each data point in the feature space. It then "spreads" the label information from these neighbors to the target data point, effectively correcting any noisy or inaccurate labels.
The authors show that this approach can outperform previous methods for robust training with noisy labels, such as data augmentation and label propagation. They also demonstrate that their method can preserve the fairness and unbiasedness of the resulting model, even in the presence of biases or errors in the training data.
Critical Analysis
The authors acknowledge several limitations of their approach. First, the method relies on accurate nearest neighbor identification, which can be challenging in high-dimensional feature spaces. Additionally, the label spreading step may amplify existing biases or introduce new ones if the nearest neighbors themselves are biased.
Another potential concern is the computational complexity of the nearest neighbors search, which could limit the scalability of the approach to very large datasets. The authors mention that they used approximate nearest neighbor methods to address this, but the impact on performance is not fully explored.
Overall, the paper presents a promising new technique for training robust and fair machine learning models, but further research may be needed to address these practical challenges and ensure the method's broader applicability.
Conclusion
This paper introduces a novel approach for making machine learning models more robust to noisy or biased training labels, with a focus on preserving the fairness and unbiasedness of the resulting predictions. By leveraging nearest neighbor information to correct noisy labels, the authors demonstrate improvements over previous methods for robust classification.
The proposed technique has the potential to enable more reliable and equitable machine learning in a wide range of real-world applications, where training data may be imperfect or biased. However, further research is needed to address the practical challenges and limitations identified in the critical analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
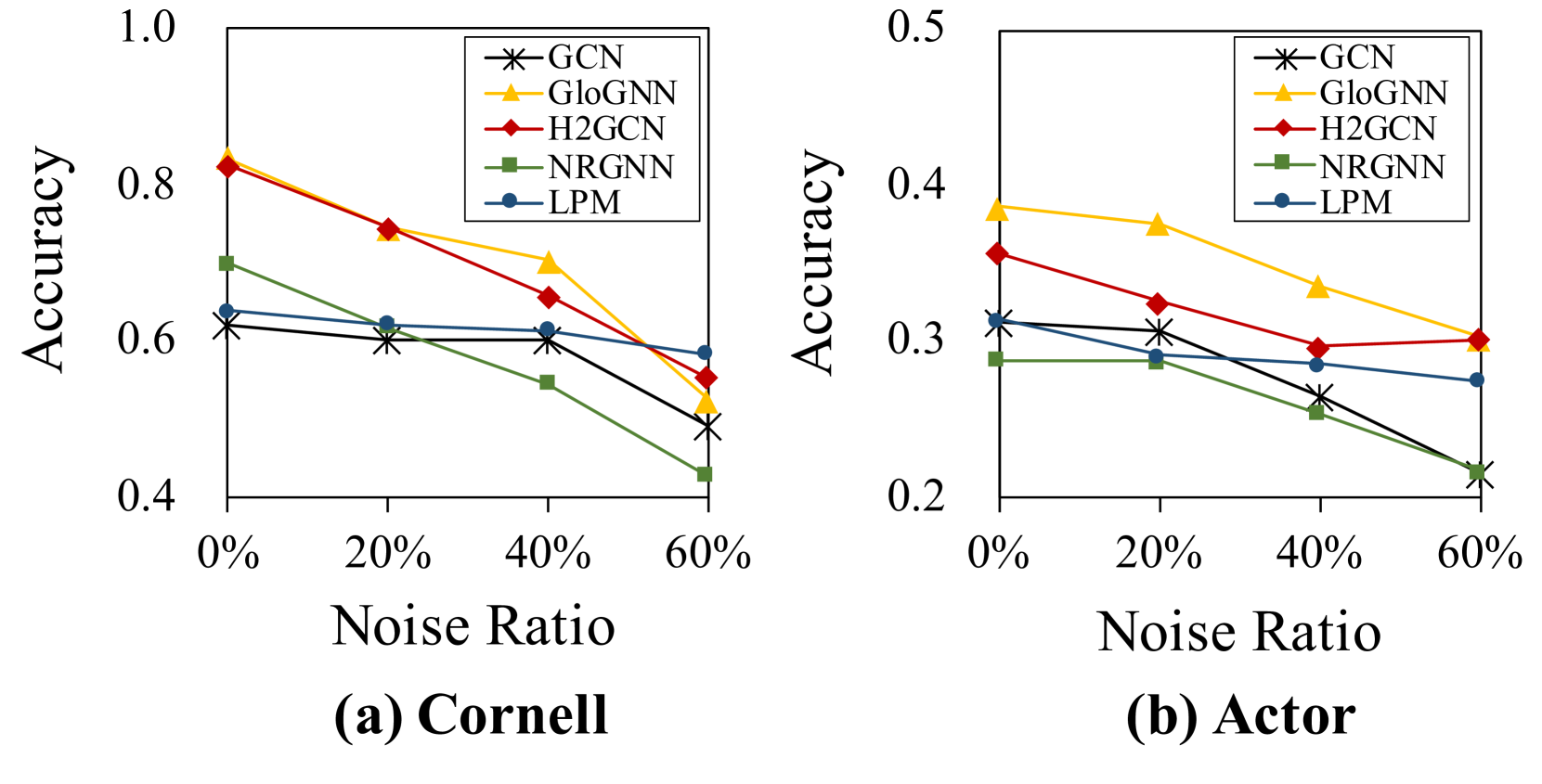
Resurrecting Label Propagation for Graphs with Heterophily and Label Noise
Yao Cheng, Caihua Shan, Yifei Shen, Xiang Li, Siqiang Luo, Dongsheng Li
0
0
Label noise is a common challenge in large datasets, as it can significantly degrade the generalization ability of deep neural networks. Most existing studies focus on noisy labels in computer vision; however, graph models encompass both node features and graph topology as input, and become more susceptible to label noise through message-passing mechanisms. Recently, only a few works have been proposed to tackle the label noise on graphs. One significant limitation is that they operate under the assumption that the graph exhibits homophily and that the labels are distributed smoothly. However, real-world graphs can exhibit varying degrees of heterophily, or even be dominated by heterophily, which results in the inadequacy of the current methods. In this paper, we study graph label noise in the context of arbitrary heterophily, with the aim of rectifying noisy labels and assigning labels to previously unlabeled nodes. We begin by conducting two empirical analyses to explore the impact of graph homophily on graph label noise. Following observations, we propose a efficient algorithm, denoted as $R^{2}LP$. Specifically, $R^{2}LP$ is an iterative algorithm with three steps: (1) reconstruct the graph to recover the homophily property, (2) utilize label propagation to rectify the noisy labels, (3) select high-confidence labels to retain for the next iteration. By iterating these steps, we obtain a set of correct labels, ultimately achieving high accuracy in the node classification task. The theoretical analysis is also provided to demonstrate its remarkable denoising effect. Finally, we perform experiments on ten benchmark datasets with different levels of graph heterophily and various types of noise. In these experiments, we compare the performance of $R^{2}LP$ against ten typical baseline methods. Our results illustrate the superior performance of the proposed $R^{2}LP$.
6/13/2024
🌀
Noise Correction on Subjective Datasets
Uthman Jinadu, Yi Ding
0
0
Incorporating every annotator's perspective is crucial for unbiased data modeling. Annotator fatigue and changing opinions over time can distort dataset annotations. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, this method provides a controllable way to encourage or discourage disagreement. We demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
6/5/2024

Robustness to Subpopulation Shift with Domain Label Noise via Regularized Annotation of Domains
Nathan Stromberg, Rohan Ayyagari, Monica Welfert, Sanmi Koyejo, Richard Nock, Lalitha Sankar
0
0
Existing methods for last layer retraining that aim to optimize worst-group accuracy (WGA) rely heavily on well-annotated groups in the training data. We show, both in theory and practice, that annotation-based data augmentations using either downsampling or upweighting for WGA are susceptible to domain annotation noise, and in high-noise regimes approach the WGA of a model trained with vanilla empirical risk minimization. We introduce Regularized Annotation of Domains (RAD) in order to train robust last layer classifiers without the need for explicit domain annotations. Our results show that RAD is competitive with other recently proposed domain annotation-free techniques. Most importantly, RAD outperforms state-of-the-art annotation-reliant methods even with only 5% noise in the training data for several publicly available datasets.
6/27/2024

Robust Classification by Coupling Data Mollification with Label Smoothing
Markus Heinonen, Ba-Hien Tran, Michael Kampffmeyer, Maurizio Filippone
0
0
Introducing training-time augmentations is a key technique to enhance generalization and prepare deep neural networks against test-time corruptions. Inspired by the success of generative diffusion models, we propose a novel approach coupling data augmentation, in the form of image noising and blurring, with label smoothing to align predicted label confidences with image degradation. The method is simple to implement, introduces negligible overheads, and can be combined with existing augmentations. We demonstrate improved robustness and uncertainty quantification on the corrupted image benchmarks of the CIFAR and TinyImageNet datasets.
6/4/2024