RoCap: A Robotic Data Collection Pipeline for the Pose Estimation of Appearance-Changing Objects

0

Sign in to get full access
Overview
- This paper presents RoCap, a robotic data collection pipeline for capturing the pose of objects that change in appearance over time.
- The system uses a robotic arm to automatically capture 3D scans of objects from multiple viewpoints, enabling the creation of large-scale datasets for training pose estimation models.
- The key contributions include a workflow for automating the data collection process and techniques for handling appearance changes like deformations and occlusions.
Plain English Explanation
The RoCap system is designed to help researchers collect large datasets of 3D object pose information. Pose estimation - determining the position and orientation of an object in 3D space - is an important task in fields like robotics, augmented reality, and computer vision. However, it can be challenging when objects change in appearance over time, for example, if an object is deformed or partially obscured.
RoCap uses a robotic arm to automatically scan objects from many different angles. This allows it to capture a diverse range of poses and appearances, which can then be used to train machine learning models for pose estimation. The key advantages of this approach are that it automates a tedious data collection process and enables the creation of large, high-quality datasets that cover a wide variety of object behaviors.
By making it easier to gather the training data needed for pose estimation, RoCap could help advance research in areas like [link to Ho-Cap capture system paper], [link to You Only Scan Once paper], and [link to Free-Moving Object Reconstruction paper]. It may also support applications that require robust pose estimation, such as [link to TAX-Pose paper] and [link to Multimodal Pose Estimation paper].
Technical Explanation
The RoCap pipeline consists of several key components. First, a robotic arm is used to automatically manipulate the object and capture 3D scans from multiple viewpoints. This is done by moving the arm through a predefined sequence of poses while a depth sensor mounted on the end effector collects range data.
To handle appearance changes, the system employs several techniques. For deformable objects, it uses a non-rigid registration algorithm to align the scans and extract consistent pose information. For occlusions, it leverages a combination of multiple viewpoints and segmentation to identify and remove occluded regions.
The collected data is then processed to extract 6D pose annotations (3D position and 3D orientation) for each scan. These ground truth labels are used to train deep learning models for estimating object pose from RGB-D sensor data.
The authors evaluate RoCap on a dataset of daily objects that exhibit a variety of appearance changes. They demonstrate that the automatically generated training data enables pose estimation models to achieve state-of-the-art performance, outperforming versions trained on manually curated datasets.
Critical Analysis
The RoCap pipeline represents an important advance in the field of pose estimation. By automating the data collection process, it enables the creation of large-scale datasets that capture a rich diversity of object behaviors. This is a significant contribution, as the availability of high-quality training data has been a key bottleneck in developing robust pose estimation systems.
That said, the paper does not delve deeply into some of the technical challenges involved in the pipeline. For example, the non-rigid registration algorithm used for deformable objects is not described in detail, and its performance limitations are not thoroughly analyzed. Additionally, the authors do not provide much insight into the sensitivity of the system to factors like sensor noise, lighting conditions, or object material properties.
It would also be valuable to see the RoCap pipeline evaluated on a wider range of object categories, beyond the daily objects used in the current experiments. Extending the system to handle a broader set of appearance changes, such as those encountered in industrial or natural environments, could further demonstrate its versatility and real-world applicability.
Conclusion
The RoCap system represents an important step forward in automated data collection for pose estimation research. By leveraging a robotic arm to capture 3D scans of objects from multiple viewpoints, the system can generate large, diverse datasets that enable the training of highly accurate pose estimation models. This advances the state of the art in areas like [link to Ho-Cap capture system paper], [link to You Only Scan Once paper], and [link to Free-Moving Object Reconstruction paper], and supports applications that require robust pose estimation, such as [link to TAX-Pose paper] and [link to Multimodal Pose Estimation paper].
While the paper leaves some technical details unexplored, the overall RoCap pipeline is a significant contribution that has the potential to accelerate progress in 3D object pose estimation and its many real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RoCap: A Robotic Data Collection Pipeline for the Pose Estimation of Appearance-Changing Objects
Jiahao Nick Li, Toby Chong, Zhongyi Zhou, Hironori Yoshida, Koji Yatani, Xiang 'Anthony' Chen, Takeo Igarashi
Object pose estimation plays a vital role in mixed-reality interactions when users manipulate tangible objects as controllers. Traditional vision-based object pose estimation methods leverage 3D reconstruction to synthesize training data. However, these methods are designed for static objects with diffuse colors and do not work well for objects that change their appearance during manipulation, such as deformable objects like plush toys, transparent objects like chemical flasks, reflective objects like metal pitchers, and articulated objects like scissors. To address this limitation, we propose Rocap, a robotic pipeline that emulates human manipulation of target objects while generating data labeled with ground truth pose information. The user first gives the target object to a robotic arm, and the system captures many pictures of the object in various 6D configurations. The system trains a model by using captured images and their ground truth pose information automatically calculated from the joint angles of the robotic arm. We showcase pose estimation for appearance-changing objects by training simple deep-learning models using the collected data and comparing the results with a model trained with synthetic data based on 3D reconstruction via quantitative and qualitative evaluation. The findings underscore the promising capabilities of Rocap.
Read more7/12/2024

0
HO-Cap: A Capture System and Dataset for 3D Reconstruction and Pose Tracking of Hand-Object Interaction
Jikai Wang, Qifan Zhang, Yu-Wei Chao, Bowen Wen, Xiaohu Guo, Yu Xiang
We introduce a data capture system and a new dataset named HO-Cap that can be used to study 3D reconstruction and pose tracking of hands and objects in videos. The capture system uses multiple RGB-D cameras and a HoloLens headset for data collection, avoiding the use of expensive 3D scanners or mocap systems. We propose a semi-automatic method to obtain annotations of shape and pose of hands and objects in the collected videos, which significantly reduces the required annotation time compared to manual labeling. With this system, we captured a video dataset of humans using objects to perform different tasks, as well as simple pick-and-place and handover of an object from one hand to the other, which can be used as human demonstrations for embodied AI and robot manipulation research. Our data capture setup and annotation framework can be used by the community to reconstruct 3D shapes of objects and human hands and track their poses in videos.
Read more6/18/2024
0
RoCo:Robust Collaborative Perception By Iterative Object Matching and Pose Adjustment
Zhe Huang, Shuo Wang, Yongcai Wang, Wanting Li, Deying Li, Lei Wang
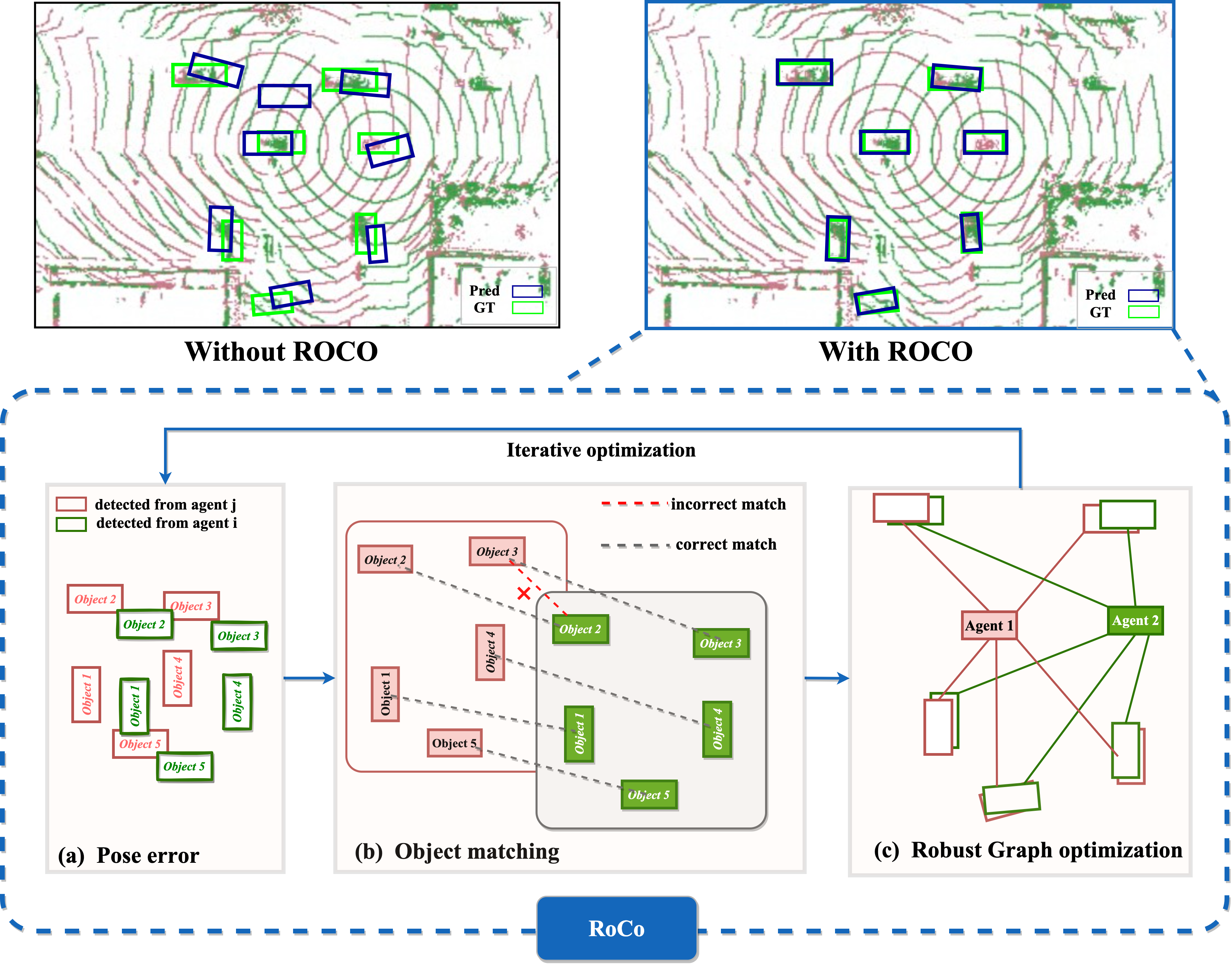
Collaborative autonomous driving with multiple vehicles usually requires the data fusion from multiple modalities. To ensure effective fusion, the data from each individual modality shall maintain a reasonably high quality. However, in collaborative perception, the quality of object detection based on a modality is highly sensitive to the relative pose errors among the agents. It leads to feature misalignment and significantly reduces collaborative performance. To address this issue, we propose RoCo, a novel unsupervised framework to conduct iterative object matching and agent pose adjustment. To the best of our knowledge, our work is the first to model the pose correction problem in collaborative perception as an object matching task, which reliably associates common objects detected by different agents. On top of this, we propose a graph optimization process to adjust the agent poses by minimizing the alignment errors of the associated objects, and the object matching is re-done based on the adjusted agent poses. This process is carried out iteratively until convergence. Experimental study on both simulated and real-world datasets demonstrates that the proposed framework RoCo consistently outperforms existing relevant methods in terms of the collaborative object detection performance, and exhibits highly desired robustness when the pose information of agents is with high-level noise. Ablation studies are also provided to show the impact of its key parameters and components. The code is released at https://github.com/HuangZhe885/RoCo.
Read more8/2/2024

0
RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation
Boshi An, Yiran Geng, Kai Chen, Xiaoqi Li, Qi Dou, Hao Dong
Robotic manipulation requires accurate perception of the environment, which poses a significant challenge due to its inherent complexity and constantly changing nature. In this context, RGB image and point-cloud observations are two commonly used modalities in visual-based robotic manipulation, but each of these modalities have their own limitations. Commercial point-cloud observations often suffer from issues like sparse sampling and noisy output due to the limits of the emission-reception imaging principle. On the other hand, RGB images, while rich in texture information, lack essential depth and 3D information crucial for robotic manipulation. To mitigate these challenges, we propose an image-only robotic manipulation framework that leverages an eye-on-hand monocular camera installed on the robot's parallel gripper. By moving with the robot gripper, this camera gains the ability to actively perceive object from multiple perspectives during the manipulation process. This enables the estimation of 6D object poses, which can be utilized for manipulation. While, obtaining images from more and diverse viewpoints typically improves pose estimation, it also increases the manipulation time. To address this trade-off, we employ a reinforcement learning policy to synchronize the manipulation strategy with active perception, achieving a balance between 6D pose accuracy and manipulation efficiency. Our experimental results in both simulated and real-world environments showcase the state-of-the-art effectiveness of our approach. %, which, to the best of our knowledge, is the first to achieve robust real-world robotic manipulation through active pose estimation. We believe that our method will inspire further research on real-world-oriented robotic manipulation.
Read more9/10/2024