On the Role of Information Structure in Reinforcement Learning for Partially-Observable Sequential Teams and Games

0
🏅
Sign in to get full access
Overview
- This paper proposes a novel reinforcement learning model that explicitly represents the information structure of sequential decision-making problems.
- The authors use this model to analyze the statistical hardness of general sequential decision-making problems, deriving an upper bound on the sample complexity of learning these problems.
- This work provides a new perspective on reinforcement learning, identifying tractable classes of problems and offering a systematic approach to understanding the complexity of sequential decision-making.
Plain English Explanation
In sequential decision-making problems, the way events at different points in time affect each other is known as the "information structure." Classical reinforcement learning models, such as Markov Decision Processes (MDPs) and Partially Observable Markov Decision Processes (POMDPs), assume a simple and regular information structure. However, real-world problems often involve a complex and changing interdependence of system variables, which requires a more flexible representation of information structure.
This paper introduces a new reinforcement learning model that explicitly models the information structure of a problem. The authors then use this model to analyze the difficulty of learning general sequential decision-making problems. They show that the complexity of a problem can be characterized by a graph-theoretic quantity, which allows them to derive an upper bound on the sample complexity (the amount of data required to learn the problem).
This work provides a novel perspective on reinforcement learning, rethinking the way information structures are modeled and offering a systematic way to identify new classes of tractable problems. By explicitly representing the information structure, the researchers aim to better understand the challenges and opportunities in sequential decision-making.
Technical Explanation
The authors propose a novel reinforcement learning model that explicitly represents the information structure of a sequential decision-making problem. This model is more general than classical frameworks like MDPs and POMDPs, which assume a simple and regular information structure.
The key components of the authors' model are:
- Temporal Dependency Graph: A directed acyclic graph (DAG) that represents the dependencies between system variables at different time steps.
- Information State: A summary of the relevant information available to the decision-maker at a given time step, based on the temporal dependency graph.
Using this model, the authors carry out an information-structural analysis of the statistical hardness of general sequential decision-making problems. They prove an upper bound on the sample complexity of learning a problem in terms of the structure of its temporal dependency graph.
The authors' analysis recovers known tractability results for certain problem classes, such as MDPs and POMDPs, and provides a novel perspective on the complexity of reinforcement learning in general sequential decision-making problems. By characterizing the hardness of a problem based on its information structure, the researchers offer a systematic way to identify new tractable classes of problems.
Critical Analysis
The paper presents a well-principled and theoretically grounded approach to modeling the information structure of sequential decision-making problems. The authors' explicit representation of the information structure is a valuable contribution, as it allows for a more nuanced understanding of problem complexity compared to classical reinforcement learning frameworks.
However, the paper does not address the practical challenges of applying this model in real-world scenarios. The authors acknowledge that the temporal dependency graph may be difficult to learn in practice, especially for complex problems. Additionally, the proposed algorithm for learning the optimal policy, while theoretically sound, may not scale well to larger problem instances.
Further research is needed to explore techniques for effectively learning the information structure and leveraging it for efficient policy learning. Incorporating ideas from other areas of reinforcement learning research, such as deep reinforcement learning and transfer learning, could help address these challenges and make the proposed model more applicable to real-world problems.
Conclusion
This paper presents a novel reinforcement learning model that explicitly represents the information structure of sequential decision-making problems. By characterizing the complexity of a problem based on its information structure, the authors provide a systematic approach to identifying tractable classes of problems and understanding the inherent challenges in general sequential decision-making.
While the theoretical insights are valuable, the practical application of this model remains an open challenge. Addressing the limitations in terms of learning the information structure and scaling the proposed algorithm will be important next steps to make this framework more accessible and impactful for real-world reinforcement learning problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
On the Role of Information Structure in Reinforcement Learning for Partially-Observable Sequential Teams and Games
Awni Altabaa, Zhuoran Yang
In a sequential decision-making problem, the information structure is the description of how events in the system occurring at different points in time affect each other. Classical models of reinforcement learning (e.g., MDPs, POMDPs) assume a simple and highly regular information structure, while more general models like predictive state representations do not explicitly model the information structure. By contrast, real-world sequential decision-making problems typically involve a complex and time-varying interdependence of system variables, requiring a rich and flexible representation of information structure. In this paper, we formalize a novel reinforcement learning model which explicitly represents the information structure. We then use this model to carry out an information-structural analysis of the statistical hardness of general sequential decision-making problems, obtaining a characterization via a graph-theoretic quantity of the DAG representation of the information structure. We prove an upper bound on the sample complexity of learning a general sequential decision-making problem in terms of its information structure by exhibiting an algorithm achieving the upper bound. This recovers known tractability results and gives a novel perspective on reinforcement learning in general sequential decision-making problems, providing a systematic way of identifying new tractable classes of problems.
Read more5/29/2024
0
Effective Reinforcement Learning Based on Structural Information Principles
Xianghua Zeng, Hao Peng, Dingli Su, Angsheng Li
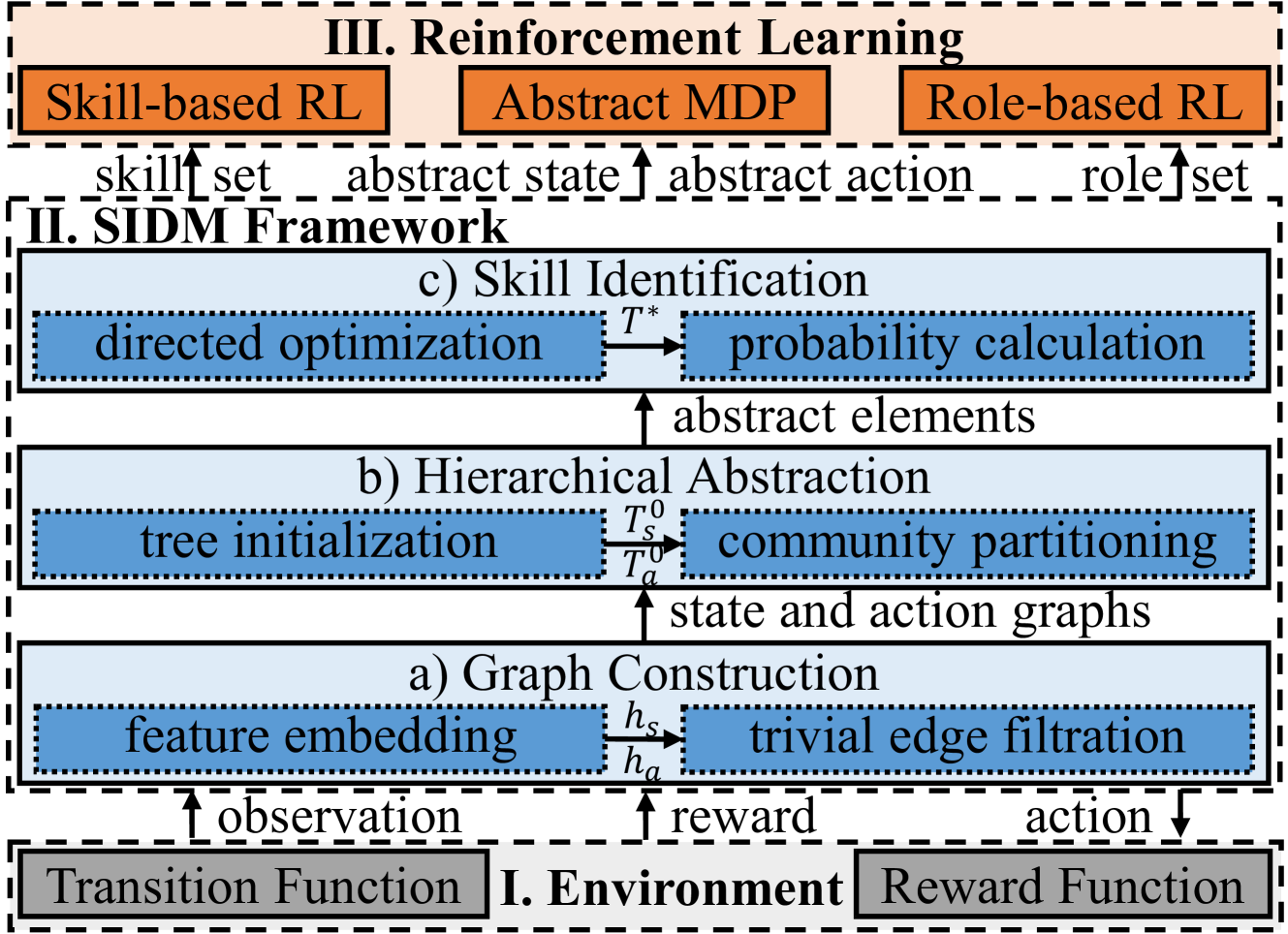
Although Reinforcement Learning (RL) algorithms acquire sequential behavioral patterns through interactions with the environment, their effectiveness in noisy and high-dimensional scenarios typically relies on specific structural priors. In this paper, we propose a novel and general Structural Information principles-based framework for effective Decision-Making, namely SIDM, approached from an information-theoretic perspective. This paper presents a specific unsupervised partitioning method that forms vertex communities in the state and action spaces based on their feature similarities. An aggregation function, which utilizes structural entropy as the vertex weight, is devised within each community to obtain its embedding, thereby facilitating hierarchical state and action abstractions. By extracting abstract elements from historical trajectories, a directed, weighted, homogeneous transition graph is constructed. The minimization of this graph's high-dimensional entropy leads to the generation of an optimal encoding tree. An innovative two-layer skill-based learning mechanism is introduced to compute the common path entropy of each state transition as its identified probability, thereby obviating the requirement for expert knowledge. Moreover, SIDM can be flexibly incorporated into various single-agent and multi-agent RL algorithms, enhancing their performance. Finally, extensive evaluations on challenging benchmarks demonstrate that, compared with SOTA baselines, our framework significantly and consistently improves the policy's quality, stability, and efficiency up to 32.70%, 88.26%, and 64.86%, respectively.
Read more4/16/2024

0
Structure in Deep Reinforcement Learning: A Survey and Open Problems
Aditya Mohan, Amy Zhang, Marius Lindauer
Reinforcement Learning (RL), bolstered by the expressive capabilities of Deep Neural Networks (DNNs) for function approximation, has demonstrated considerable success in numerous applications. However, its practicality in addressing various real-world scenarios, characterized by diverse and unpredictable dynamics, noisy signals, and large state and action spaces, remains limited. This limitation stems from poor data efficiency, limited generalization capabilities, a lack of safety guarantees, and the absence of interpretability, among other factors. To overcome these challenges and improve performance across these crucial metrics, one promising avenue is to incorporate additional structural information about the problem into the RL learning process. Various sub-fields of RL have proposed methods for incorporating such inductive biases. We amalgamate these diverse methodologies under a unified framework, shedding light on the role of structure in the learning problem, and classify these methods into distinct patterns of incorporating structure. By leveraging this comprehensive framework, we provide valuable insights into the challenges of structured RL and lay the groundwork for a design pattern perspective on RL research. This novel perspective paves the way for future advancements and aids in developing more effective and efficient RL algorithms that can potentially handle real-world scenarios better.
Read more4/26/2024
🏅
0
Partially Observable Multi-Agent Reinforcement Learning with Information Sharing
Xiangyu Liu, Kaiqing Zhang
We study provable multi-agent reinforcement learning (RL) in the general framework of partially observable stochastic games (POSGs). To circumvent the known hardness results and the use of computationally intractable oracles, we advocate leveraging the potential emph{information-sharing} among agents, a common practice in empirical multi-agent RL, and a standard model for multi-agent control systems with communications. We first establish several computational complexity results to justify the necessity of information-sharing, as well as the observability assumption that has enabled quasi-efficient single-agent RL with partial observations, for efficiently solving POSGs. {Inspired by the inefficiency of planning in the ground-truth model,} we then propose to further emph{approximate} the shared common information to construct an {approximate model} of the POSG, in which planning an approximate emph{equilibrium} (in terms of solving the original POSG) can be quasi-efficient, i.e., of quasi-polynomial-time, under the aforementioned assumptions. Furthermore, we develop a partially observable multi-agent RL algorithm that is emph{both} statistically and computationally quasi-efficient. {Finally, beyond equilibrium learning, we extend our algorithmic framework to finding the emph{team-optimal solution} in cooperative POSGs, i.e., decentralized partially observable Markov decision processes, a much more challenging goal. We establish concrete computational and sample complexities under several common structural assumptions of the model.} We hope our study could open up the possibilities of leveraging and even designing different emph{information structures}, a well-studied notion in control theory, for developing both sample- and computation-efficient partially observable multi-agent RL.
Read more9/5/2024