Rotated Multi-Scale Interaction Network for Referring Remote Sensing Image Segmentation

0

Sign in to get full access
Overview
- The paper proposes a "Rotated Multi-Scale Interaction Network for Referring Remote Sensing Image Segmentation" (RRSIS-D), a deep learning model for accurately segmenting objects in remote sensing images based on natural language descriptions.
- The model uses a multi-scale feature extraction approach and an interaction module to effectively combine visual and textual information for precise segmentation.
- The RRSIS-D model outperforms state-of-the-art methods on several remote sensing image segmentation benchmarks.
Plain English Explanation
The paper introduces a new deep learning system that can analyze remote sensing images and segment, or outline, specific objects based on natural language descriptions. For example, if you provide the system with an aerial image of a city and describe the target as "the large red building with a blue roof," the system will be able to accurately outline that specific building.
This is a challenging task because remote sensing images can be very complex, with many different objects and features. The key innovation of this model is that it uses a multi-scale approach, which means it examines the image at different levels of detail to understand both the overall context and the fine-grained details needed for accurate segmentation. The model also has a special "interaction module" that combines the visual information from the image with the textual description in an effective way to make the final segmentation decision.
The researchers tested their model on several standard remote sensing image datasets and found that it outperformed other state-of-the-art methods. This suggests the RRSIS-D model is a promising approach for applications like urban planning, disaster response, and environmental monitoring, where being able to accurately identify specific objects in aerial or satellite imagery is very important.
Technical Explanation
The RRSIS-D model consists of two main components: a visual encoder and a language encoder. The visual encoder uses a convolutional neural network to extract multi-scale features from the input remote sensing image. It does this by passing the image through a series of convolutional and pooling layers at different scales, capturing both coarse-grained contextual information and fine-grained object details.
The language encoder uses a transformer-based network to encode the input natural language description into a compact feature representation. An "interaction module" then fuses the visual and language features, allowing the model to effectively combine the image context and the textual description to make the final segmentation prediction.
The model is trained end-to-end on remote sensing image-description pairs, optimizing a combination of segmentation and language-based losses. The researchers evaluated the RRSIS-D model on three public remote sensing image segmentation datasets, demonstrating significant performance improvements over previous state-of-the-art approaches.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated model for the important task of referring image segmentation in the remote sensing domain. The multi-scale visual feature extraction and the language-vision interaction module are clever innovations that appear to be the key factors behind the model's strong performance.
That said, the paper does not deeply address potential limitations or real-world deployment challenges. For example, the model was only evaluated on pre-existing benchmark datasets, which may not fully capture the diversity and complexity of real-world remote sensing imagery and language descriptions. Additionally, the computational and memory efficiency of the model is not discussed, which could be an important consideration for practical applications.
Further research could explore the model's robustness to noisy, incomplete, or ambiguous language inputs, as well as its generalization capabilities to new domains beyond the tested benchmarks. Incorporating active learning or few-shot learning strategies could also enhance the model's practical applicability in settings with limited training data.
Overall, the RRSIS-D model represents a promising advance in remote sensing image understanding, but additional work is needed to fully understand its strengths, limitations, and potential real-world impact.
Conclusion
The Rotated Multi-Scale Interaction Network (RRSIS-D) proposed in this paper is a novel deep learning model that can effectively segment objects in remote sensing images based on natural language descriptions. By leveraging a multi-scale visual feature extraction approach and a language-vision interaction module, the RRSIS-D model outperforms previous state-of-the-art methods on several benchmark datasets.
This research represents an important step forward in bridging the gap between human-centric language and the complex visual data collected by remote sensing platforms. The ability to accurately identify and delineate specific objects of interest in aerial or satellite imagery has many potential applications, from urban planning and disaster response to environmental monitoring and agricultural management.
While further research is needed to fully understand the model's limitations and real-world deployment challenges, the RRSIS-D architecture and its strong empirical performance suggest it is a promising direction for advancing the field of referring image segmentation in the remote sensing domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rotated Multi-Scale Interaction Network for Referring Remote Sensing Image Segmentation
Sihan Liu, Yiwei Ma, Xiaoqing Zhang, Haowei Wang, Jiayi Ji, Xiaoshuai Sun, Rongrong Ji
Referring Remote Sensing Image Segmentation (RRSIS) is a new challenge that combines computer vision and natural language processing, delineating specific regions in aerial images as described by textual queries. Traditional Referring Image Segmentation (RIS) approaches have been impeded by the complex spatial scales and orientations found in aerial imagery, leading to suboptimal segmentation results. To address these challenges, we introduce the Rotated Multi-Scale Interaction Network (RMSIN), an innovative approach designed for the unique demands of RRSIS. RMSIN incorporates an Intra-scale Interaction Module (IIM) to effectively address the fine-grained detail required at multiple scales and a Cross-scale Interaction Module (CIM) for integrating these details coherently across the network. Furthermore, RMSIN employs an Adaptive Rotated Convolution (ARC) to account for the diverse orientations of objects, a novel contribution that significantly enhances segmentation accuracy. To assess the efficacy of RMSIN, we have curated an expansive dataset comprising 17,402 image-caption-mask triplets, which is unparalleled in terms of scale and variety. This dataset not only presents the model with a wide range of spatial and rotational scenarios but also establishes a stringent benchmark for the RRSIS task, ensuring a rigorous evaluation of performance. Our experimental evaluations demonstrate the exceptional performance of RMSIN, surpassing existing state-of-the-art models by a significant margin. All datasets and code are made available at https://github.com/Lsan2401/RMSIN.
Read more4/3/2024
0
Spatial Semantic Recurrent Mining for Referring Image Segmentation
Jiaxing Yang, Lihe Zhang, Jiayu Sun, Huchuan Lu
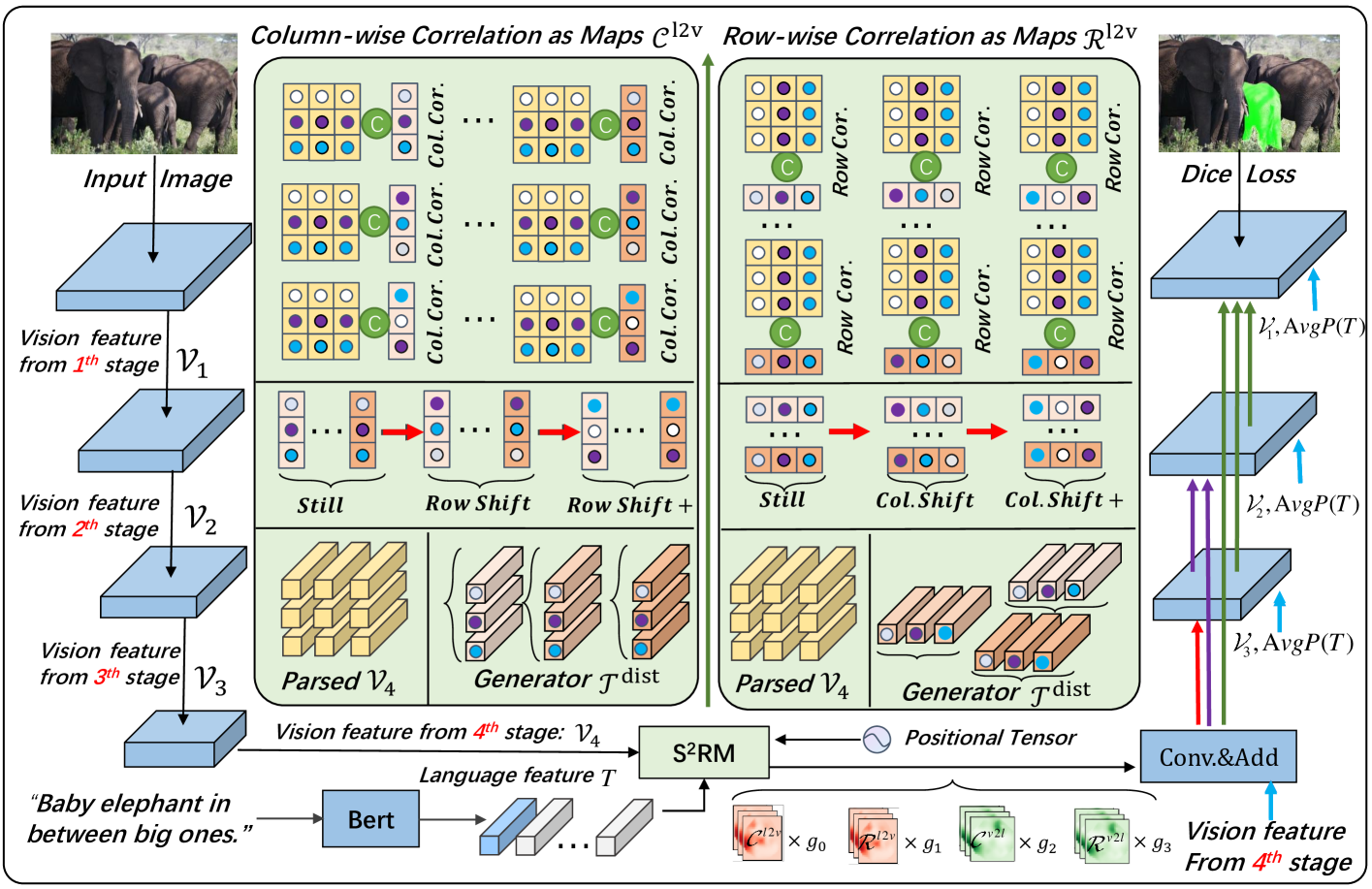
Referring Image Segmentation (RIS) consistently requires language and appearance semantics to more understand each other. The need becomes acute especially under hard situations. To achieve, existing works tend to resort to various trans-representing mechanisms to directly feed forward language semantic along main RGB branch, which however will result in referent distribution weakly-mined in space and non-referent semantic contaminated along channel. In this paper, we propose Spatial Semantic Recurrent Mining (Stextsuperscript{2}RM) to achieve high-quality cross-modality fusion. It follows a working strategy of trilogy: distributing language feature, spatial semantic recurrent coparsing, and parsed-semantic balancing. During fusion, Stextsuperscript{2}RM will first generate a constraint-weak yet distribution-aware language feature, then bundle features of each row and column from rotated features of one modality context to recurrently correlate relevant semantic contained in feature from other modality context, and finally resort to self-distilled weights to weigh on the contributions of different parsed semantics. Via coparsing, Stextsuperscript{2}RM transports information from the near and remote slice layers of generator context to the current slice layer of parsed context, capable of better modeling global relationship bidirectional and structured. Besides, we also propose a Cross-scale Abstract Semantic Guided Decoder (CASG) to emphasize the foreground of the referent, finally integrating different grained features at a comparatively low cost. Extensive experimental results on four current challenging datasets show that our proposed method performs favorably against other state-of-the-art algorithms.
Read more5/16/2024

0
Transcending Fusion: A Multi-Scale Alignment Method for Remote Sensing Image-Text Retrieval
Rui Yang, Shuang Wang, Yingping Han, Yuanheng Li, Dong Zhao, Dou Quan, Yanhe Guo, Licheng Jiao
Remote Sensing Image-Text Retrieval (RSITR) is pivotal for knowledge services and data mining in the remote sensing (RS) domain. Considering the multi-scale representations in image content and text vocabulary can enable the models to learn richer representations and enhance retrieval. Current multi-scale RSITR approaches typically align multi-scale fused image features with text features, but overlook aligning image-text pairs at distinct scales separately. This oversight restricts their ability to learn joint representations suitable for effective retrieval. We introduce a novel Multi-Scale Alignment (MSA) method to overcome this limitation. Our method comprises three key innovations: (1) Multi-scale Cross-Modal Alignment Transformer (MSCMAT), which computes cross-attention between single-scale image features and localized text features, integrating global textual context to derive a matching score matrix within a mini-batch, (2) a multi-scale cross-modal semantic alignment loss that enforces semantic alignment across scales, and (3) a cross-scale multi-modal semantic consistency loss that uses the matching matrix from the largest scale to guide alignment at smaller scales. We evaluated our method across multiple datasets, demonstrating its efficacy with various visual backbones and establishing its superiority over existing state-of-the-art methods. The GitHub URL for our project is: https://github.com/yr666666/MSA
Read more5/30/2024

0
RSTeller: Scaling Up Visual Language Modeling in Remote Sensing with Rich Linguistic Semantics from Openly Available Data and Large Language Models
Junyao Ge, Yang Zheng, Kaitai Guo, Jimin Liang
Abundant, well-annotated multimodal data in remote sensing are pivotal for aligning complex visual remote sensing (RS) scenes with human language, enabling the development of specialized vision language models across diverse RS interpretation tasks. However, annotating RS images with rich linguistic semantics at scale demands expertise in RS and substantial human labor, making it costly and often impractical. In this study, we propose a workflow that leverages large language models (LLMs) to generate multimodal datasets with semantically rich captions at scale from plain OpenStreetMap (OSM) data for images sourced from the Google Earth Engine (GEE) platform. This approach facilitates the generation of paired remote sensing data and can be readily scaled up using openly available data. Within this framework, we present RSTeller, a multimodal dataset comprising over 1 million RS images, each accompanied by multiple descriptive captions. Extensive experiments demonstrate that RSTeller enhances the performance of multiple existing vision language models for RS scene understanding through continual pre-training. Our methodology significantly reduces the manual effort and expertise needed for annotating remote sensing imagery while democratizing access to high-quality annotated data. This advancement fosters progress in visual language modeling and encourages broader participation in remote sensing research and applications. The RSTeller dataset is available at https://github.com/SlytherinGe/RSTeller.
Read more8/28/2024