Spatial Semantic Recurrent Mining for Referring Image Segmentation

0
Sign in to get full access
Overview
- Referring Image Segmentation (RIS): A task that involves segmenting a specific object in an image based on a natural language description or query.
- Spatial Semantic Recurrent Mining: A novel approach that models the global relationship between the language query and the image to improve RIS performance.
- Cross-scale Abstract Semantic Guided Decoder (CASG): A key component of the proposed method that leverages cross-scale visual and semantic information to guide the segmentation process.
Plain English Explanation
The paper focuses on the problem of Referring Image Segmentation (RIS). This task involves identifying a specific object in an image based on a natural language description or query, such as "the red car in the middle of the image." This is a challenging problem because the algorithm needs to understand the language query and then use that information to accurately segment the correct object in the image.
The authors propose a new approach called Spatial Semantic Recurrent Mining that aims to improve RIS performance by better modeling the global relationship between the language query and the image. This is done by using a Cross-scale Abstract Semantic Guided Decoder (CASG) that leverages visual and semantic information at multiple scales to guide the segmentation process.
The key idea is to capture the spatial and semantic connections between the language query and the visual elements in the image, rather than just considering them independently. This allows the model to better understand the context and relationships involved, leading to more accurate segmentation of the target object.
Technical Explanation
The authors propose a Spatial Semantic Recurrent Mining approach for Referring Image Segmentation (RIS). The core of their method is a Cross-scale Abstract Semantic Guided Decoder (CASG), which leverages visual and semantic information at multiple scales to guide the segmentation process.
The CASG module takes the language query and the visual features of the image as input, and then generates a semantic-guided spatial relation map. This map captures the global relationship between the language query and the visual elements in the image, allowing the model to better understand the context and focus on the relevant regions for segmentation.
The authors use a recurrent structure to iteratively refine the segmentation mask, integrating the language query and spatial-semantic information at each step. This iterative process helps the model gradually converge to the target object boundary.
The authors evaluate their proposed method on several RIS benchmarks and show that it outperforms previous state-of-the-art approaches, demonstrating the effectiveness of their Spatial Semantic Recurrent Mining approach.
Critical Analysis
The paper presents a novel and compelling approach to Referring Image Segmentation, addressing the challenge of effectively integrating language and visual information to improve segmentation accuracy. The Spatial Semantic Recurrent Mining method and the Cross-scale Abstract Semantic Guided Decoder (CASG) are well-designed and show promising results.
However, the paper does not extensively discuss the limitations or potential issues with the proposed approach. For example, it would be interesting to understand how the method performs on more complex or ambiguous language queries, or how it handles cases where the target object is occluded or has significant variations in appearance.
Additionally, the paper could benefit from a more in-depth discussion of the computational complexity and runtime performance of the model, as these factors can be important considerations for real-world applications.
Overall, the research presented in the paper is a valuable contribution to the field of Referring Image Segmentation, and the authors' innovative approach provides a strong foundation for further exploration and refinement.
Conclusion
This paper introduces a novel Spatial Semantic Recurrent Mining approach for Referring Image Segmentation, which effectively models the global relationship between the language query and the visual elements in the image. The key component, the Cross-scale Abstract Semantic Guided Decoder (CASG), leverages multi-scale visual and semantic information to guide the segmentation process, leading to improved performance on several RIS benchmarks.
The proposed method represents an important advancement in the field of language-guided image understanding, with potential applications in areas such as image editing, robotic navigation, and human-computer interaction. While the paper could benefit from a more detailed discussion of limitations and future research directions, the authors' innovative approach and strong empirical results make this a valuable contribution to the literature.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spatial Semantic Recurrent Mining for Referring Image Segmentation
Jiaxing Yang, Lihe Zhang, Jiayu Sun, Huchuan Lu
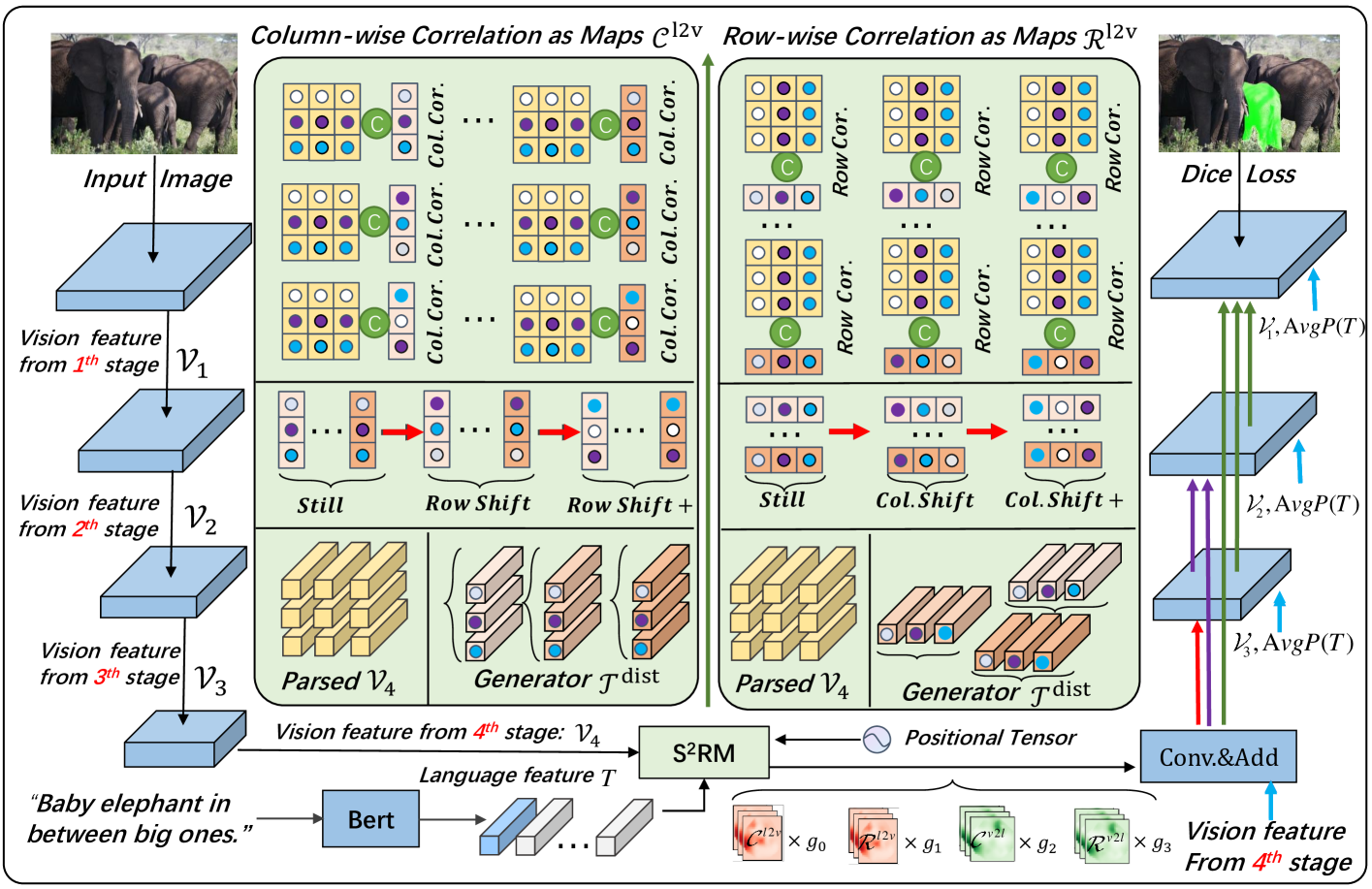
Referring Image Segmentation (RIS) consistently requires language and appearance semantics to more understand each other. The need becomes acute especially under hard situations. To achieve, existing works tend to resort to various trans-representing mechanisms to directly feed forward language semantic along main RGB branch, which however will result in referent distribution weakly-mined in space and non-referent semantic contaminated along channel. In this paper, we propose Spatial Semantic Recurrent Mining (Stextsuperscript{2}RM) to achieve high-quality cross-modality fusion. It follows a working strategy of trilogy: distributing language feature, spatial semantic recurrent coparsing, and parsed-semantic balancing. During fusion, Stextsuperscript{2}RM will first generate a constraint-weak yet distribution-aware language feature, then bundle features of each row and column from rotated features of one modality context to recurrently correlate relevant semantic contained in feature from other modality context, and finally resort to self-distilled weights to weigh on the contributions of different parsed semantics. Via coparsing, Stextsuperscript{2}RM transports information from the near and remote slice layers of generator context to the current slice layer of parsed context, capable of better modeling global relationship bidirectional and structured. Besides, we also propose a Cross-scale Abstract Semantic Guided Decoder (CASG) to emphasize the foreground of the referent, finally integrating different grained features at a comparatively low cost. Extensive experimental results on four current challenging datasets show that our proposed method performs favorably against other state-of-the-art algorithms.
Read more5/16/2024

0
MARIS: Referring Image Segmentation via Mutual-Aware Attention Features
Mengxi Zhang, Yiming Liu, Xiangjun Yin, Huanjing Yue, Jingyu Yang
Referring image segmentation (RIS) aims to segment a particular region based on a language expression prompt. Existing methods incorporate linguistic features into visual features and obtain multi-modal features for mask decoding. However, these methods may segment the visually salient entity instead of the correct referring region, as the multi-modal features are dominated by the abundant visual context. In this paper, we propose MARIS, a referring image segmentation method that leverages the Segment Anything Model (SAM) and introduces a mutual-aware attention mechanism to enhance the cross-modal fusion via two parallel branches. Specifically, our mutual-aware attention mechanism consists of Vision-Guided Attention and Language-Guided Attention, which bidirectionally model the relationship between visual and linguistic features. Correspondingly, we design a Mask Decoder to enable explicit linguistic guidance for more consistent segmentation with the language expression. To this end, a multi-modal query token is proposed to integrate linguistic information and interact with visual information simultaneously. Extensive experiments on three benchmark datasets show that our method outperforms the state-of-the-art RIS methods. Our code will be publicly available.
Read more5/22/2024
🖼️
0
Superpixel Semantics Representation and Pre-training for Vision-Language Task
Siyu Zhang, Yeming Chen, Yaoru Sun, Fang Wang, Jun Yang, Lizhi Bai, Shangce Gao
The key to integrating visual language tasks is to establish a good alignment strategy. Recently, visual semantic representation has achieved fine-grained visual understanding by dividing grids or image patches. However, the coarse-grained semantic interactions in image space should not be ignored, which hinders the extraction of complex contextual semantic relations at the scene boundaries. This paper proposes superpixels as comprehensive and robust visual primitives, which mine coarse-grained semantic interactions by clustering perceptually similar pixels, speeding up the subsequent processing of primitives. To capture superpixel-level semantic features, we propose a Multiscale Difference Graph Convolutional Network (MDGCN). It allows parsing the entire image as a fine-to-coarse visual hierarchy. To reason actual semantic relations, we reduce potential noise interference by aggregating difference information between adjacent graph nodes. Finally, we propose a multi-level fusion rule in a bottom-up manner to avoid understanding deviation by mining complementary spatial information at different levels. Experiments show that the proposed method can effectively promote the learning of multiple downstream tasks. Encouragingly, our method outperforms previous methods on all metrics. Our code will be released upon publication.
Read more7/23/2024

0
Cross-Modal Conditioned Reconstruction for Language-guided Medical Image Segmentation
Xiaoshuang Huang, Hongxiang Li, Meng Cao, Long Chen, Chenyu You, Dong An
Recent developments underscore the potential of textual information in enhancing learning models for a deeper understanding of medical visual semantics. However, language-guided medical image segmentation still faces a challenging issue. Previous works employ implicit and ambiguous architectures to embed textual information. This leads to segmentation results that are inconsistent with the semantics represented by the language, sometimes even diverging significantly. To this end, we propose a novel cross-modal conditioned Reconstruction for Language-guided Medical Image Segmentation (RecLMIS) to explicitly capture cross-modal interactions, which assumes that well-aligned medical visual features and medical notes can effectively reconstruct each other. We introduce conditioned interaction to adaptively predict patches and words of interest. Subsequently, they are utilized as conditioning factors for mutual reconstruction to align with regions described in the medical notes. Extensive experiments demonstrate the superiority of our RecLMIS, surpassing LViT by 3.74% mIoU on the publicly available MosMedData+ dataset and achieving an average increase of 1.89% mIoU for cross-domain tests on our QATA-CoV19 dataset. Simultaneously, we achieve a relative reduction of 20.2% in parameter count and a 55.5% decrease in computational load. The code will be available at https://github.com/ShashankHuang/RecLMIS.
Read more7/9/2024