RouteLLM: Learning to Route LLMs with Preference Data
2406.18665
0
0

Abstract
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
Create account to get full access
Overview
- The paper proposes a system called RouteLLM that learns to route queries to the most appropriate large language model (LLM) based on user preferences.
- RouteLLM uses machine learning to optimize the selection of LLMs for different tasks, aiming to maximize quality and efficiency.
- The system is designed to handle the growing complexity of the LLM ecosystem and help users navigate the increasing number of available models.
Plain English Explanation
The paper introduces a system called RouteLLM that is designed to make it easier for users to choose the most suitable large language model (LLM) for their needs. As the number of available LLMs continues to grow, it can be challenging for users to determine which model is best for a particular task.
RouteLLM uses machine learning to learn from user preferences and optimize the selection of LLMs. The key idea is that different LLMs may be better suited for different types of tasks, and RouteLLM aims to match the user's query to the most appropriate LLM based on past user feedback and performance data.
For example, if a user often prefers the output of a certain LLM for creative writing tasks, RouteLLM would learn to route those types of queries to that specific model in the future. Similarly, if another LLM is known to be more accurate for factual questions, RouteLLM would direct those queries to that model instead.
By automating the process of selecting the right LLM for each task, RouteLLM aims to help users get higher-quality and more efficient results from the growing ecosystem of language models.
Technical Explanation
The RouteLLM system is designed to optimize the selection of large language models (LLMs) for different user queries. The key components of the system include:
-
Query Encoding: RouteLLM encodes the user's query into a vector representation that can be used to match the query to the most appropriate LLM.
-
Preference Data: The system collects user feedback and preferences, such as which LLM outputs the user found most useful for a particular task. This preference data is used to train the routing model.
-
Routing Model: RouteLLM uses machine learning to train a model that can predict which LLM is likely to provide the best output for a given query, based on the query encoding and the collected preference data.
-
LLM Assignment: When a user submits a new query, RouteLLM uses the trained routing model to select the LLM that is predicted to provide the best output for that query. The user's query is then forwarded to the selected LLM for processing.
The paper describes experiments that demonstrate the effectiveness of RouteLLM in improving the quality and efficiency of LLM usage, compared to a baseline approach of randomly selecting LLMs. The results suggest that RouteLLM can learn to route queries to the most appropriate LLMs, leading to better overall performance.
Critical Analysis
The RouteLLM paper presents a promising approach to addressing the growing complexity of the LLM ecosystem. By automating the selection of the most suitable LLM for each user query, the system has the potential to improve the user experience and the overall effectiveness of language model usage.
However, the paper does not address several potential limitations and areas for further research. For example, the system relies on the availability of sufficient user preference data, which may not always be the case, especially for new users or emerging LLMs. Additionally, the performance of the routing model may be sensitive to the quality and diversity of the training data, and the paper does not explore how the system might handle concept drift or changes in user preferences over time.
Furthermore, the paper does not consider the implications of RouteLLM's decisions on the LLM ecosystem itself. By routing queries to certain LLMs more frequently, the system could potentially create feedback loops or inadvertently influence the development and deployment of language models, which could have broader societal impacts that warrant further investigation.
Despite these caveats, the RouteLLM approach represents an important step forward in managing the complexity of the LLM landscape and optimizing the user experience. As the field of large language models continues to evolve, systems like RouteLLM will likely play an increasingly crucial role in ensuring that users can effectively harness the power of these powerful AI tools.
Conclusion
The RouteLLM paper introduces a novel approach to optimizing the selection of large language models (LLMs) for user queries. By leveraging machine learning to learn from user preferences and route queries to the most appropriate LLMs, the system aims to improve the quality and efficiency of LLM usage.
The key innovation of RouteLLM is its ability to automate the process of LLM selection, which can be particularly valuable as the ecosystem of available language models continues to grow in complexity. By matching user queries to the most suitable LLMs, the system has the potential to enhance the user experience and unlock the full potential of these powerful AI tools.
While the paper identifies several promising results, it also highlights the need for further research to address potential limitations, such as the reliance on user preference data and the system's potential impact on the LLM ecosystem itself. As the field of large language models evolves, systems like RouteLLM will likely play an increasingly important role in helping users navigate the growing landscape of AI-powered language technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V. S. Lakshmanan, Ahmed Hassan Awadallah
0
0
Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
4/24/2024
OptLLM: Optimal Assignment of Queries to Large Language Models
Yueyue Liu, Hongyu Zhang, Yuantian Miao, Van-Hoang Le, Zhiqiang Li
0
0
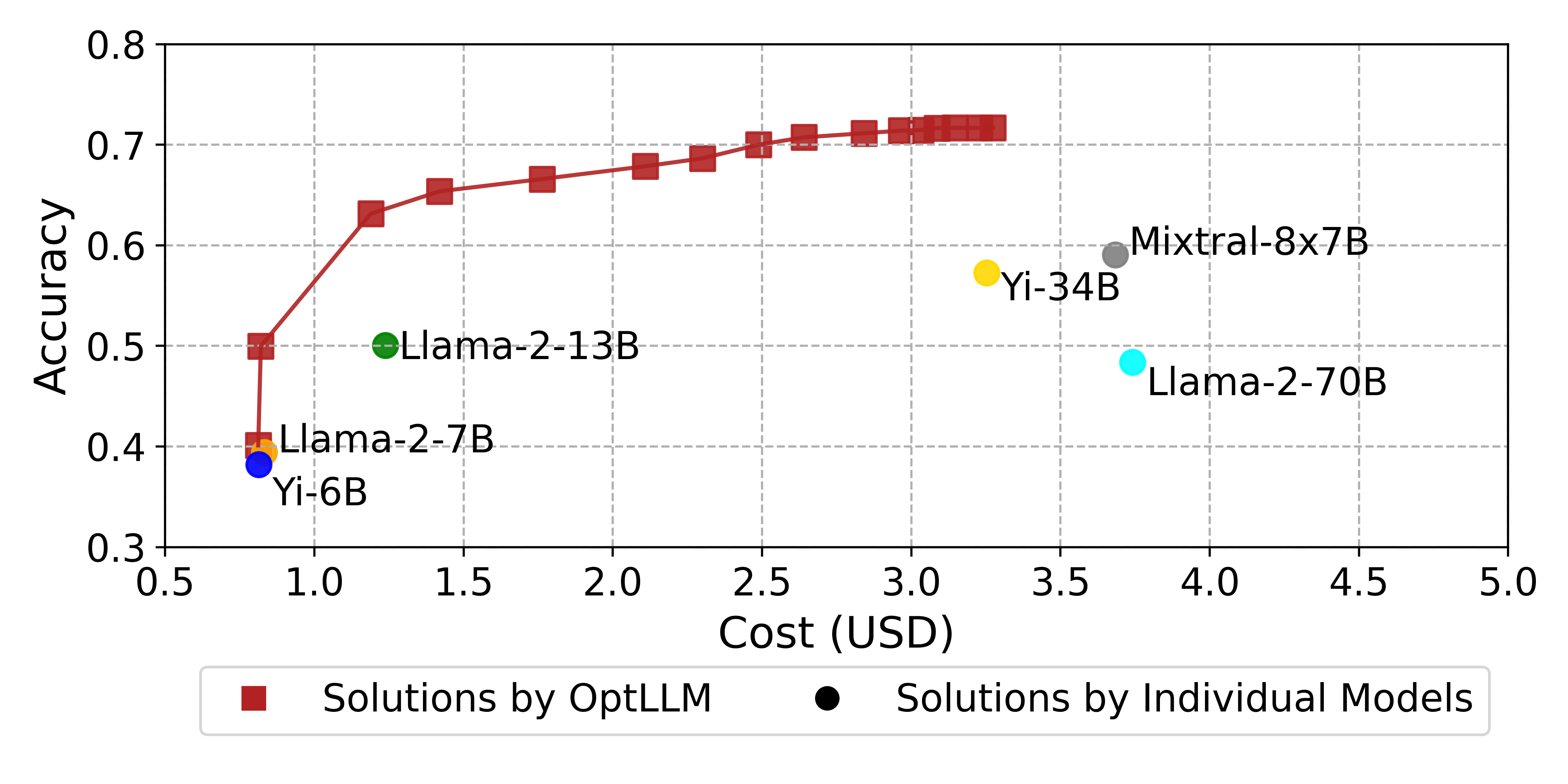
Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
5/27/2024
💬
Optimising Calls to Large Language Models with Uncertainty-Based Two-Tier Selection
Guillem Ram'irez, Alexandra Birch, Ivan Titov
0
0
Researchers and practitioners operating on a limited budget face the cost-performance trade-off dilemma. The challenging decision often centers on whether to use a large LLM with better performance or a smaller one with reduced costs. This has motivated recent research in the optimisation of LLM calls. Either a cascading strategy is used, where a smaller LLM or both are called sequentially, or a routing strategy is used, where only one model is ever called. Both scenarios are dependent on a decision criterion which is typically implemented by an extra neural model. In this work, we propose a simpler solution; we use only the uncertainty of the generations of the small LLM as the decision criterion. We compare our approach with both cascading and routing strategies using three different pairs of pre-trained small and large LLMs, on nine different tasks and against approaches that require an additional neural model. Our experiments reveal this simple solution optimally balances cost and performance, outperforming existing methods on 25 out of 27 experimental setups.
5/6/2024
Towards Modular LLMs by Building and Reusing a Library of LoRAs
Oleksiy Ostapenko, Zhan Su, Edoardo Maria Ponti, Laurent Charlin, Nicolas Le Roux, Matheus Pereira, Lucas Caccia, Alessandro Sordoni
0
0
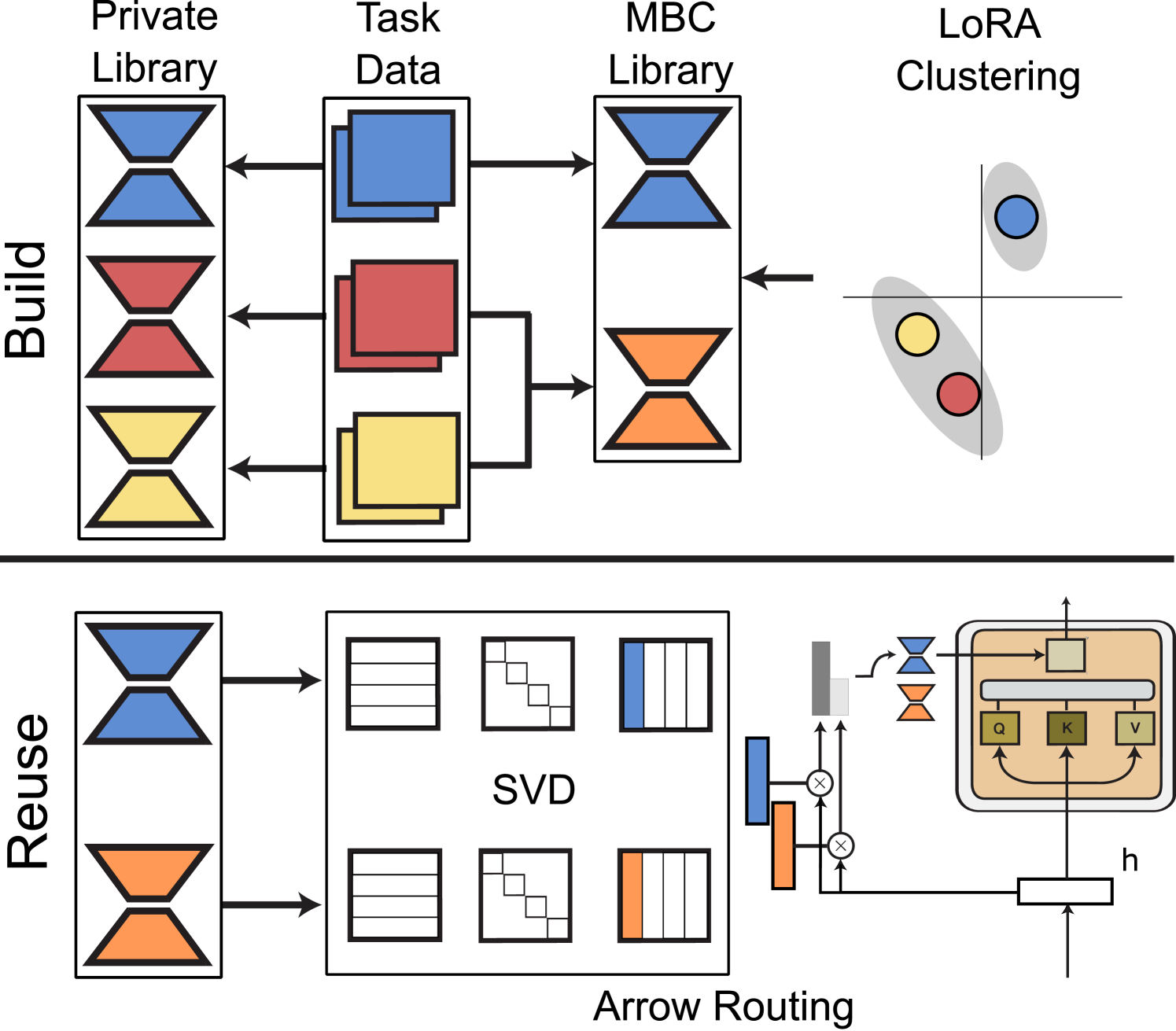
The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.
5/21/2024