Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
2404.14618
0
0
🛸
Abstract
Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
Create account to get full access
Overview
- Large language models (LLMs) excel at most natural language processing (NLP) tasks, but require expensive cloud servers for deployment due to their size
- Smaller models that can run on lower-cost devices tend to have lower response quality compared to LLMs
- This work proposes a hybrid inference approach that combines the strengths of both LLMs and smaller models to save cost while maintaining quality
Plain English Explanation
Large language models are extremely capable at understanding and generating human language, but they are also very large and complex, requiring powerful cloud-based servers to run. On the other hand, smaller language models that can be deployed on more affordable edge devices don't perform as well as the large models.
To address this trade-off, the researchers developed a hybrid approach that uses a "router" to decide whether to send a given language task to the large model or the smaller model. The router evaluates the difficulty of the task and the desired level of quality, and then routes it to the appropriate model. This allows them to use the large, high-quality model only when necessary, while relying on the smaller, more cost-effective model for simpler tasks.
Through experiments, the researchers found that their hybrid approach can reduce the number of calls to the large model by up to 40%, without any drop in the quality of the responses. This could significantly lower the overall cost of deploying these language models in real-world applications.
Technical Explanation
The core of the researchers' approach is a "router" that dynamically assigns language tasks to either a large, high-quality language model or a smaller, more cost-effective model. The router evaluates the predicted difficulty of the task and the desired level of quality, and then routes the task to the appropriate model.
For simple queries, the router will send the task to the smaller model, which can handle it more efficiently and cost-effectively. But for more complex queries, the router will send it to the large language model to ensure high-quality responses.
The researchers tested their hybrid approach on a variety of NLP tasks, and found that it can reduce the number of calls to the large model by up to 40%, without any drop in response quality. This is achieved by intelligently routing tasks to the appropriate model based on the specific requirements of each query.
Critical Analysis
The researchers acknowledge that their approach relies on accurately predicting the difficulty of each language task, which can be challenging. If the router makes incorrect predictions, it could end up sending too many tasks to the large model, negating the potential cost savings.
Additionally, the paper does not provide much detail on the specific mechanisms used by the router to make its routing decisions. More transparency around this process would allow for a more thorough evaluation of the approach.
It's also worth considering the potential for bias or fairness issues that could arise from the router's decision-making. If certain types of queries or users are more likely to be routed to the smaller model, it could lead to disparities in the quality of service received.
Despite these potential limitations, the overall concept of a hybrid approach that combines the strengths of large and small language models is a promising direction for improving the cost-effectiveness of deploying these powerful AI systems in real-world applications.
Conclusion
This research presents a novel hybrid approach to language model inference that aims to leverage the strengths of both large, high-quality models and smaller, more cost-effective models. By using a dynamic router to assign tasks based on predicted difficulty and desired quality, the researchers were able to reduce the number of calls to the large model by up to 40% without sacrificing response quality.
This work could have significant implications for making advanced language AI more accessible and affordable, particularly for applications with tight budgetary constraints. As the field of large language models continues to advance, innovative approaches like this hybrid inference system will be crucial for bridging the gap between research breakthroughs and real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, Ion Stoica
0
0
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
7/2/2024
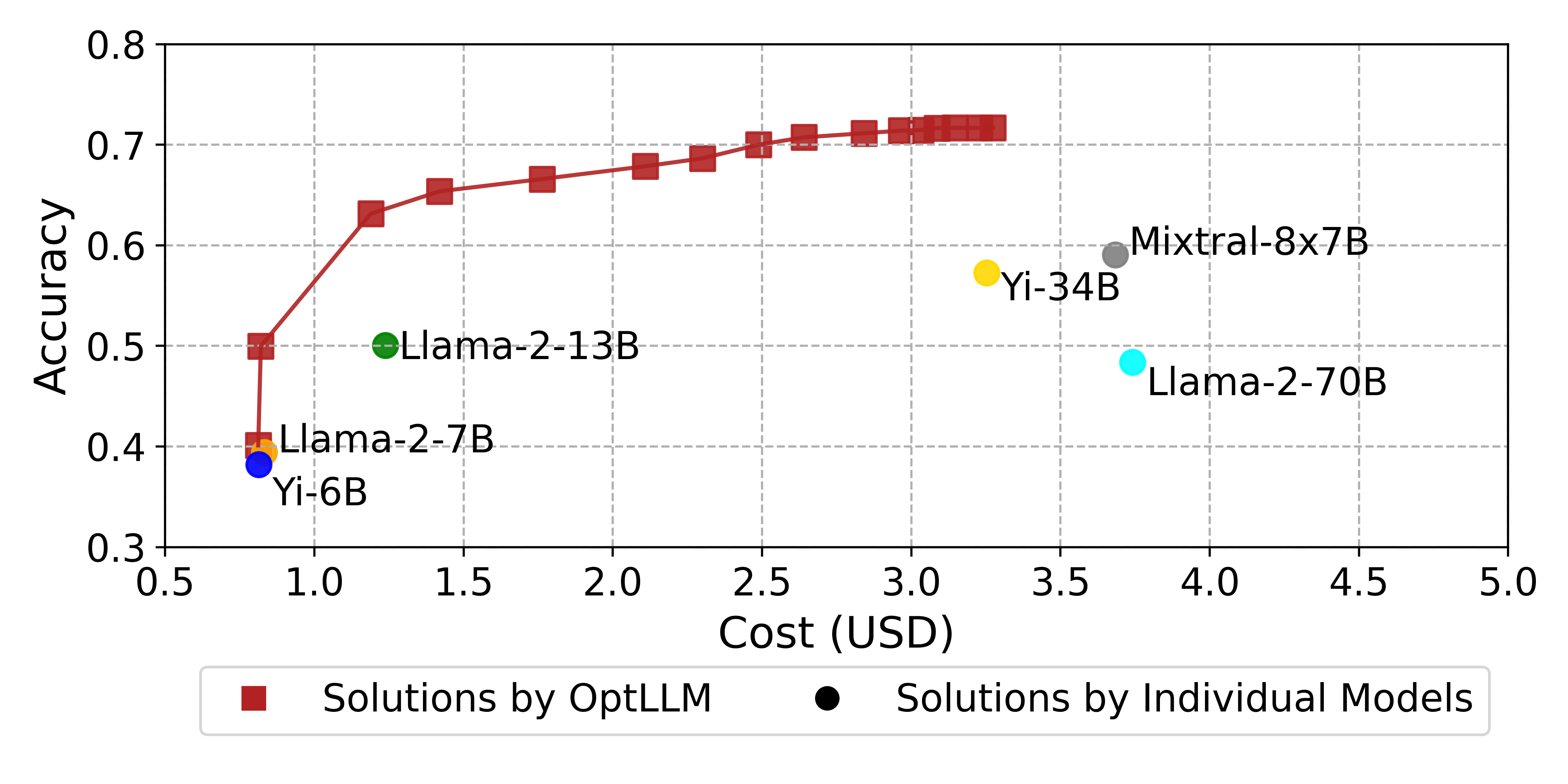
OptLLM: Optimal Assignment of Queries to Large Language Models
Yueyue Liu, Hongyu Zhang, Yuantian Miao, Van-Hoang Le, Zhiqiang Li
0
0
Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
5/27/2024
💬
Optimising Calls to Large Language Models with Uncertainty-Based Two-Tier Selection
Guillem Ram'irez, Alexandra Birch, Ivan Titov
0
0
Researchers and practitioners operating on a limited budget face the cost-performance trade-off dilemma. The challenging decision often centers on whether to use a large LLM with better performance or a smaller one with reduced costs. This has motivated recent research in the optimisation of LLM calls. Either a cascading strategy is used, where a smaller LLM or both are called sequentially, or a routing strategy is used, where only one model is ever called. Both scenarios are dependent on a decision criterion which is typically implemented by an extra neural model. In this work, we propose a simpler solution; we use only the uncertainty of the generations of the small LLM as the decision criterion. We compare our approach with both cascading and routing strategies using three different pairs of pre-trained small and large LLMs, on nine different tasks and against approaches that require an additional neural model. Our experiments reveal this simple solution optimally balances cost and performance, outperforming existing methods on 25 out of 27 experimental setups.
5/6/2024
💬
Expert Router: Orchestrating Efficient Language Model Inference through Prompt Classification
Josef Pichlmeier, Philipp Ross, Andre Luckow
0
0
Large Language Models (LLMs) have experienced widespread adoption across scientific and industrial domains due to their versatility and utility for diverse tasks. Nevertheless, deploying and serving these models at scale with optimal throughput and latency remains a significant challenge, primarily because of the high computational and memory demands associated with LLMs. To tackle this limitation, we introduce Expert Router, a system designed to orchestrate multiple expert models efficiently, thereby enhancing scalability. Expert Router is a parallel inference system with a central routing gateway that distributes incoming requests using a clustering method. This approach effectively partitions incoming requests among available LLMs, maximizing overall throughput. Our extensive evaluations encompassed up to 1,000 concurrent users, providing comprehensive insights into the system's behavior from user and infrastructure perspectives. The results demonstrate Expert Router's effectiveness in handling high-load scenarios and achieving higher throughput rates, particularly under many concurrent users.
4/24/2024