Optimising Calls to Large Language Models with Uncertainty-Based Two-Tier Selection
2405.02134
0
0
💬
Abstract
Researchers and practitioners operating on a limited budget face the cost-performance trade-off dilemma. The challenging decision often centers on whether to use a large LLM with better performance or a smaller one with reduced costs. This has motivated recent research in the optimisation of LLM calls. Either a cascading strategy is used, where a smaller LLM or both are called sequentially, or a routing strategy is used, where only one model is ever called. Both scenarios are dependent on a decision criterion which is typically implemented by an extra neural model. In this work, we propose a simpler solution; we use only the uncertainty of the generations of the small LLM as the decision criterion. We compare our approach with both cascading and routing strategies using three different pairs of pre-trained small and large LLMs, on nine different tasks and against approaches that require an additional neural model. Our experiments reveal this simple solution optimally balances cost and performance, outperforming existing methods on 25 out of 27 experimental setups.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers and practitioners with limited budgets face a trade-off between cost and performance when choosing between large and small language models (LLMs)
- Recent research has explored optimization strategies to balance this trade-off, including cascading and routing approaches that rely on an extra neural model for decision-making
- This paper proposes a simpler solution that uses only the uncertainty of the small LLM's generations as the decision criterion, without requiring an additional neural model
Plain English Explanation
When working with limited resources, researchers and practitioners often need to decide whether to use a large language model (LLM) that delivers better performance or a smaller one that costs less. This is a challenging trade-off to navigate.
Recent studies have explored strategies to help optimize this balance, such as a cascading approach where smaller and larger LLMs are called sequentially, or a routing approach where only one model is ever used. These methods rely on an extra neural network to decide which model to use.
In this paper, the researchers suggest a simpler solution: they use only the uncertainty of the small LLM's outputs as the decision criterion, without any additional neural network. This allows them to balance cost and performance in a more efficient way.
Technical Explanation
The researchers compare their approach to both cascading and routing strategies, using three different pairs of pre-trained small and large LLMs across nine different tasks. They find that their simple solution, which uses only the small LLM's uncertainty as the decision criterion, outperforms the existing methods in 25 out of 27 experimental setups.
This is a significant result, as it shows that a more complex architecture with an additional neural network may not be necessary to optimize the cost-performance trade-off. By relying solely on the uncertainty of the small LLM's generations, the researchers are able to achieve better results in a more straightforward way.
The benchmarking approach used in this study provides a robust evaluation of the different strategies, allowing the researchers to draw clear conclusions about the effectiveness of their proposed method.
Critical Analysis
The paper does not address potential limitations of using only the small LLM's uncertainty as the decision criterion. It's possible that in some cases, the small LLM may not provide a reliable estimate of uncertainty, leading to suboptimal decisions.
Additionally, the paper focuses on pre-trained LLM pairs and does not explore the implications of training the small and large models jointly, which could potentially lead to further improvements in the cost-performance trade-off.
While the researchers demonstrate the effectiveness of their approach across a range of tasks, it would be valuable to see how it performs on a wider variety of benchmarks, especially in the context of low-resource language processing.
Conclusion
This paper presents a simple yet effective solution to the cost-performance trade-off faced by researchers and practitioners working with limited budgets. By using only the uncertainty of the small LLM's generations as the decision criterion, the researchers are able to outperform more complex strategies that rely on additional neural networks.
This approach has the potential to make high-performance language models more accessible to a wider range of users, as it allows for a more efficient allocation of resources. While the paper does not address all possible limitations, it represents an important step forward in optimizing the use of large language models in cost-constrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V. S. Lakshmanan, Ahmed Hassan Awadallah
0
0
Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
4/24/2024
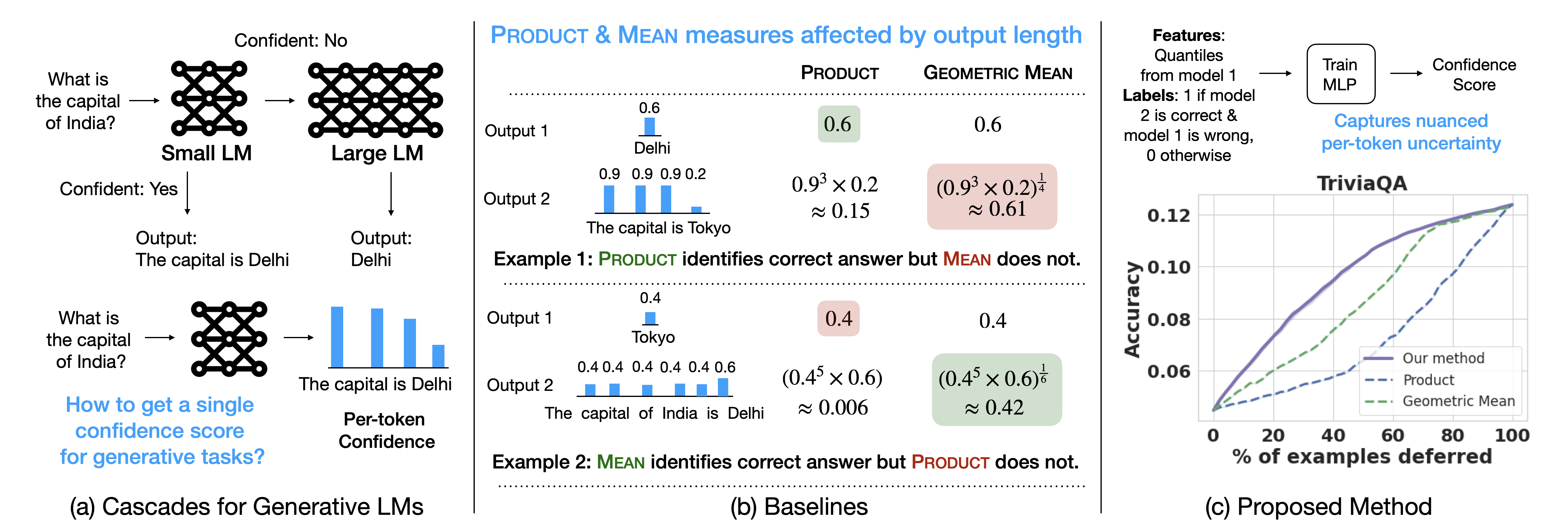
Language Model Cascades: Token-level uncertainty and beyond
Neha Gupta, Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar
0
0
Recent advances in language models (LMs) have led to significant improvements in quality on complex NLP tasks, but at the expense of increased inference costs. Cascading offers a simple strategy to achieve more favorable cost-quality tradeoffs: here, a small model is invoked for most easy instances, while a few hard instances are deferred to the large model. While the principles underpinning cascading are well-studied for classification tasks - with deferral based on predicted class uncertainty favored theoretically and practically - a similar understanding is lacking for generative LM tasks. In this work, we initiate a systematic study of deferral rules for LM cascades. We begin by examining the natural extension of predicted class uncertainty to generative LM tasks, namely, the predicted sequence uncertainty. We show that this measure suffers from the length bias problem, either over- or under-emphasizing outputs based on their lengths. This is because LMs produce a sequence of uncertainty values, one for each output token; and moreover, the number of output tokens is variable across examples. To mitigate this issue, we propose to exploit the richer token-level uncertainty information implicit in generative LMs. We argue that naive predicted sequence uncertainty corresponds to a simple aggregation of these uncertainties. By contrast, we show that incorporating token-level uncertainty through learned post-hoc deferral rules can significantly outperform such simple aggregation strategies, via experiments on a range of natural language benchmarks with FLAN-T5 models. We further show that incorporating embeddings from the smaller model and intermediate layers of the larger model can give an additional boost in the overall cost-quality tradeoff.
4/17/2024
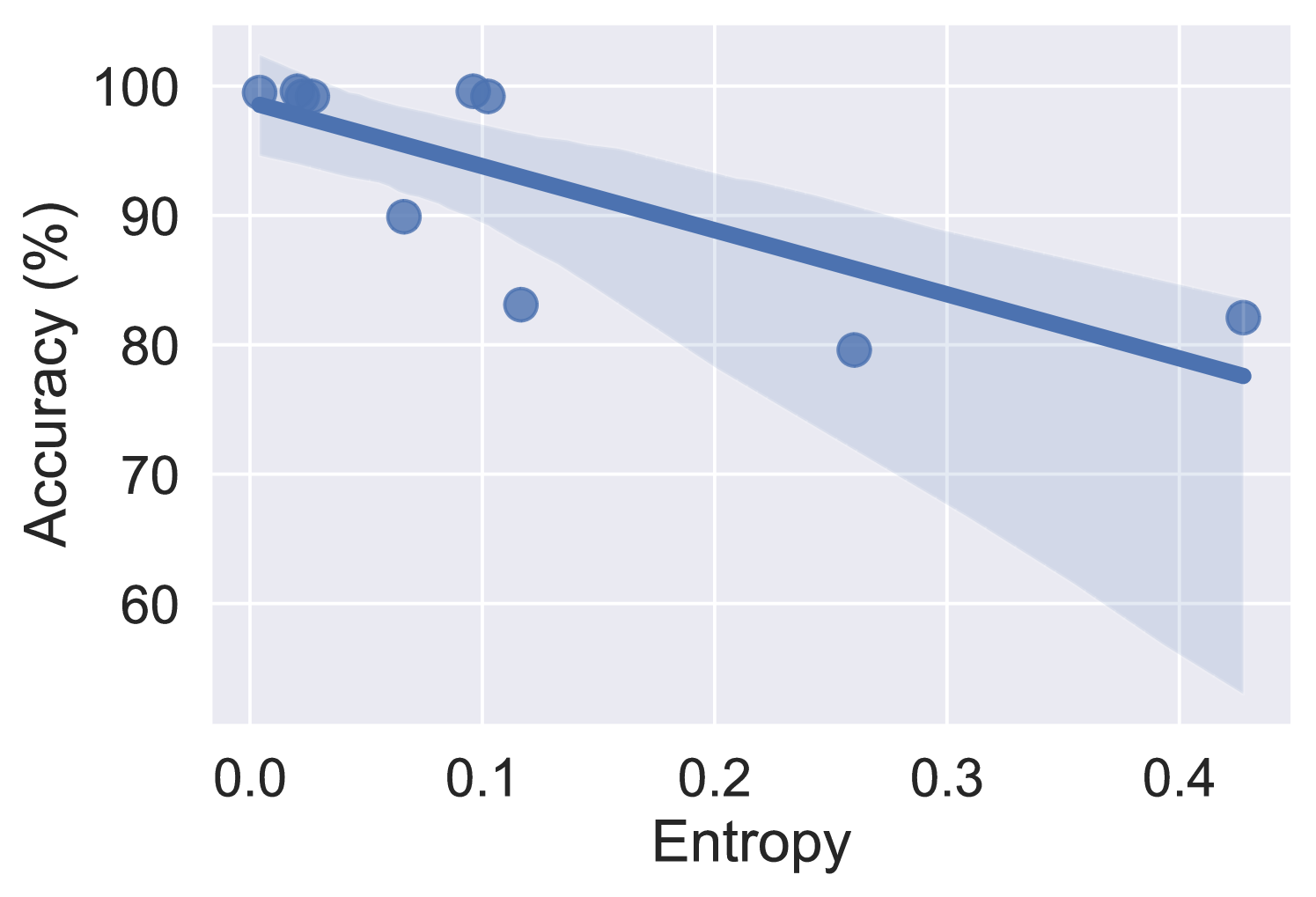
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
0
0
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
4/15/2024
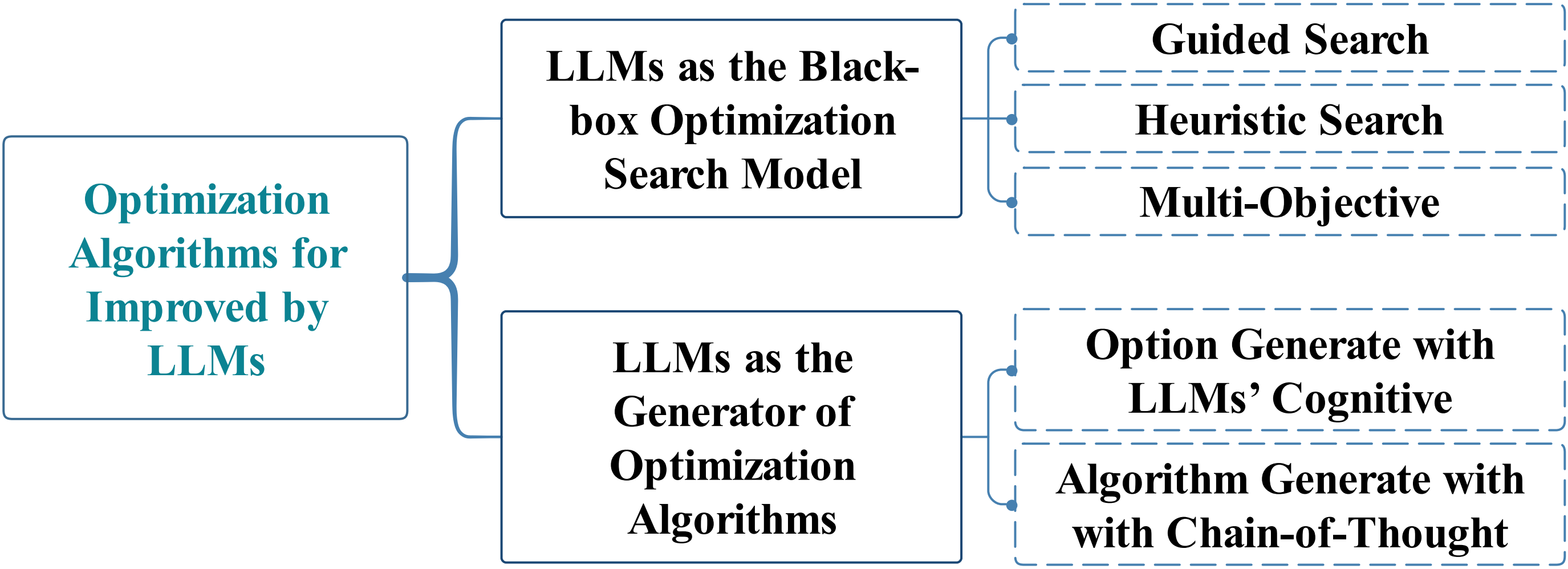
When Large Language Model Meets Optimization
Sen Huang, Kaixiang Yang, Sheng Qi, Rui Wang
0
0
Optimization algorithms and large language models (LLMs) enhance decision-making in dynamic environments by integrating artificial intelligence with traditional techniques. LLMs, with extensive domain knowledge, facilitate intelligent modeling and strategic decision-making in optimization, while optimization algorithms refine LLM architectures and output quality. This synergy offers novel approaches for advancing general AI, addressing both the computational challenges of complex problems and the application of LLMs in practical scenarios. This review outlines the progress and potential of combining LLMs with optimization algorithms, providing insights for future research directions.
5/17/2024