RREH: Reconstruction Relations Embedded Hashing for Semi-Paired Cross-Modal Retrieval

0
Sign in to get full access
Overview
- This paper proposes a novel hashing method called RREH (Reconstruction Relations Embedded Hashing) for semi-paired cross-modal retrieval tasks.
- RREH aims to learn compact and discriminative hash codes by leveraging both cross-modal correlations and data reconstruction relations.
- The method involves joint optimization of three loss functions: cross-modal hashing, data reconstruction, and similarity preservation.
Plain English Explanation
The research paper introduces a new hashing technique called RREH (Reconstruction Relations Embedded Hashing) that is designed for cross-modal retrieval tasks. Cross-modal retrieval involves searching for relevant information across different data types, such as looking for images related to a given text query or vice versa.
The key idea behind RREH is to learn compact and informative hash codes (short digital representations) for the data by considering two important factors:
-
Cross-modal Relationships: RREH attempts to capture the correlations between different data modalities (e.g., images and text) to better link related content across the modalities.
-
Data Reconstruction: In addition to the cross-modal relationships, RREH also tries to ensure that the hash codes can be used to accurately reconstruct the original data. This helps preserve important information in the hash codes.
By optimizing these two aspects jointly, RREH aims to learn hash codes that are both effective for cross-modal retrieval and retain useful details about the original data. This can be particularly helpful in "semi-paired" scenarios, where the data has incomplete cross-modal associations (i.e., not all data items have paired information in other modalities).
Technical Explanation
The key technical components of RREH are:
-
Cross-modal Hashing: RREH learns hash codes that capture the correlations between different data modalities, such as images and text. This is achieved by optimizing a cross-modal hashing loss function that encourages similar hash codes for related data across modalities.
-
Data Reconstruction: In addition to the cross-modal hashing, RREH also incorporates a data reconstruction loss. This loss function aims to ensure that the learned hash codes can be used to accurately reconstruct the original data, helping to preserve important information.
-
Similarity Preservation: RREH also includes a similarity preservation loss, which ensures that the hash codes maintain the similarity relationships present in the original data. This helps to retain the discriminative power of the hash codes.
The paper presents a joint optimization framework that combines these three loss functions to learn the hash codes. The authors demonstrate the effectiveness of RREH on several semi-paired cross-modal retrieval benchmarks, where it outperforms various state-of-the-art hashing methods.
Critical Analysis
The paper presents a well-designed and comprehensive approach to cross-modal hashing for semi-paired data. The key strengths of the RREH method include:
-
Leveraging Cross-modal Relationships: By explicitly modeling the cross-modal correlations, RREH can better link related content across different data types, which is crucial for effective cross-modal retrieval.
-
Preserving Data Reconstruction: The inclusion of a data reconstruction loss helps to ensure that the learned hash codes retain important information from the original data, which can be beneficial for various downstream tasks.
-
Maintaining Similarity Relationships: The similarity preservation loss helps to preserve the discriminative power of the hash codes, which is important for retrieval performance.
However, the paper also acknowledges some limitations and potential areas for future research:
-
Scalability: The optimization process for RREH may become computationally expensive for large-scale datasets, which could limit its practical applicability. Exploring more efficient optimization strategies could be valuable.
-
Generalization: While RREH shows promising results on the evaluated benchmarks, its performance on other cross-modal retrieval tasks or domains may vary. Further investigation into the generalizability of the method would be beneficial.
-
Interpretability: The paper does not provide much insight into the internal workings of RREH or the learned hash codes. Improving the interpretability of the method could make it more transparent and easier to understand.
Overall, the RREH method presents a compelling approach to semi-paired cross-modal retrieval, and the authors have identified relevant areas for future research to further improve the technique.
Conclusion
The RREH method proposed in this paper offers a novel and effective solution for semi-paired cross-modal retrieval tasks. By jointly optimizing cross-modal hashing, data reconstruction, and similarity preservation, RREH can learn compact and discriminative hash codes that capture both cross-modal relationships and preserve important information about the original data.
The demonstrated performance improvements over state-of-the-art hashing methods on various benchmarks suggest that RREH has the potential to significantly advance the field of cross-modal retrieval, particularly in scenarios where the available cross-modal associations are incomplete. Further exploration of the method's scalability, generalizability, and interpretability could lead to even more impactful applications in real-world cross-modal search and retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RREH: Reconstruction Relations Embedded Hashing for Semi-Paired Cross-Modal Retrieval
Jianzong Wang, Haoxiang Shi, Kaiyi Luo, Xulong Zhang, Ning Cheng, Jing Xiao
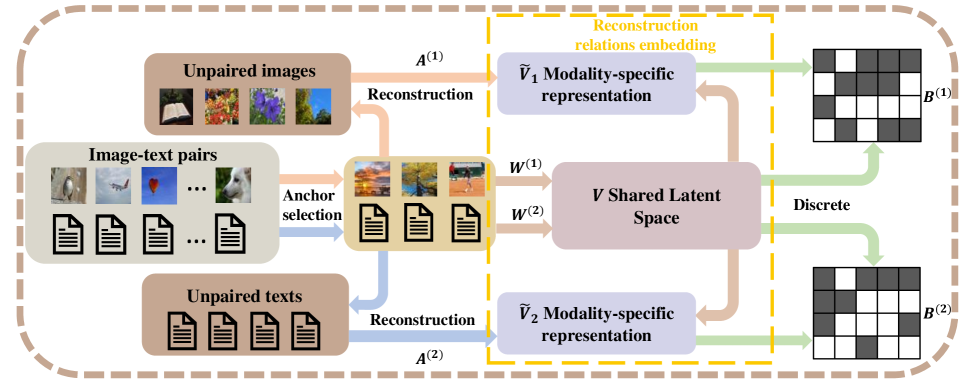
Known for efficient computation and easy storage, hashing has been extensively explored in cross-modal retrieval. The majority of current hashing models are predicated on the premise of a direct one-to-one mapping between data points. However, in real practice, data correspondence across modalities may be partially provided. In this research, we introduce an innovative unsupervised hashing technique designed for semi-paired cross-modal retrieval tasks, named Reconstruction Relations Embedded Hashing (RREH). RREH assumes that multi-modal data share a common subspace. For paired data, RREH explores the latent consistent information of heterogeneous modalities by seeking a shared representation. For unpaired data, to effectively capture the latent discriminative features, the high-order relationships between unpaired data and anchors are embedded into the latent subspace, which are computed by efficient linear reconstruction. The anchors are sampled from paired data, which improves the efficiency of hash learning. The RREH trains the underlying features and the binary encodings in a unified framework with high-order reconstruction relations preserved. With the well devised objective function and discrete optimization algorithm, RREH is designed to be scalable, making it suitable for large-scale datasets and facilitating efficient cross-modal retrieval. In the evaluation process, the proposed is tested with partially paired data to establish its superiority over several existing methods.
Read more5/29/2024

0
Contrastive masked auto-encoders based self-supervised hashing for 2D image and 3D point cloud cross-modal retrieval
Rukai Wei, Heng Cui, Yu Liu, Yufeng Hou, Yanzhao Xie, Ke Zhou
Implementing cross-modal hashing between 2D images and 3D point-cloud data is a growing concern in real-world retrieval systems. Simply applying existing cross-modal approaches to this new task fails to adequately capture latent multi-modal semantics and effectively bridge the modality gap between 2D and 3D. To address these issues without relying on hand-crafted labels, we propose contrastive masked autoencoders based self-supervised hashing (CMAH) for retrieval between images and point-cloud data. We start by contrasting 2D-3D pairs and explicitly constraining them into a joint Hamming space. This contrastive learning process ensures robust discriminability for the generated hash codes and effectively reduces the modality gap. Moreover, we utilize multi-modal auto-encoders to enhance the model's understanding of multi-modal semantics. By completing the masked image/point-cloud data modeling task, the model is encouraged to capture more localized clues. In addition, the proposed multi-modal fusion block facilitates fine-grained interactions among different modalities. Extensive experiments on three public datasets demonstrate that the proposed CMAH significantly outperforms all baseline methods.
Read more8/13/2024
⛏️
0
AutoRE: Document-Level Relation Extraction with Large Language Models
Lilong Xue, Dan Zhang, Yuxiao Dong, Jie Tang
Large Language Models (LLMs) have demonstrated exceptional abilities in comprehending and generating text, motivating numerous researchers to utilize them for Information Extraction (IE) purposes, including Relation Extraction (RE). Nonetheless, most existing methods are predominantly designed for Sentence-level Relation Extraction (SentRE) tasks, which typically encompass a restricted set of relations and triplet facts within a single sentence. Furthermore, certain approaches resort to treating relations as candidate choices integrated into prompt templates, leading to inefficient processing and suboptimal performance when tackling Document-Level Relation Extraction (DocRE) tasks, which entail handling multiple relations and triplet facts distributed across a given document, posing distinct challenges. To overcome these limitations, we introduce AutoRE, an end-to-end DocRE model that adopts a novel RE extraction paradigm named RHF (Relation-Head-Facts). Unlike existing approaches, AutoRE does not rely on the assumption of known relation options, making it more reflective of real-world scenarios. Additionally, we have developed an easily extensible RE framework using a Parameters Efficient Fine Tuning (PEFT) algorithm (QLoRA). Our experiments on the RE-DocRED dataset showcase AutoRE's best performance, achieving state-of-the-art results, surpassing TAG by 10.03% and 9.03% respectively on the dev and test set. The code is available at https://github.com/THUDM/AutoRE and the demonstration video is provided at https://www.youtube.com/watch?v=IhKRsZUAxKk.
Read more7/29/2024

0
Structure-Aware Residual-Center Representation for Self-Supervised Open-Set 3D Cross-Modal Retrieval
Yang Xu, Yifan Feng, Yu Jiang
Existing methods of 3D cross-modal retrieval heavily lean on category distribution priors within the training set, which diminishes their efficacy when tasked with unseen categories under open-set environments. To tackle this problem, we propose the Structure-Aware Residual-Center Representation (SRCR) framework for self-supervised open-set 3D cross-modal retrieval. To address the center deviation due to category distribution differences, we utilize the Residual-Center Embedding (RCE) for each object by nested auto-encoders, rather than directly mapping them to the modality or category centers. Besides, we perform the Hierarchical Structure Learning (HSL) approach to leverage the high-order correlations among objects for generalization, by constructing a heterogeneous hypergraph structure based on hierarchical inter-modality, intra-object, and implicit-category correlations. Extensive experiments and ablation studies on four benchmarks demonstrate the superiority of our proposed framework compared to state-of-the-art methods.
Read more7/23/2024