RS3Mamba: Visual State Space Model for Remote Sensing Images Semantic Segmentation
2404.02457
0
0
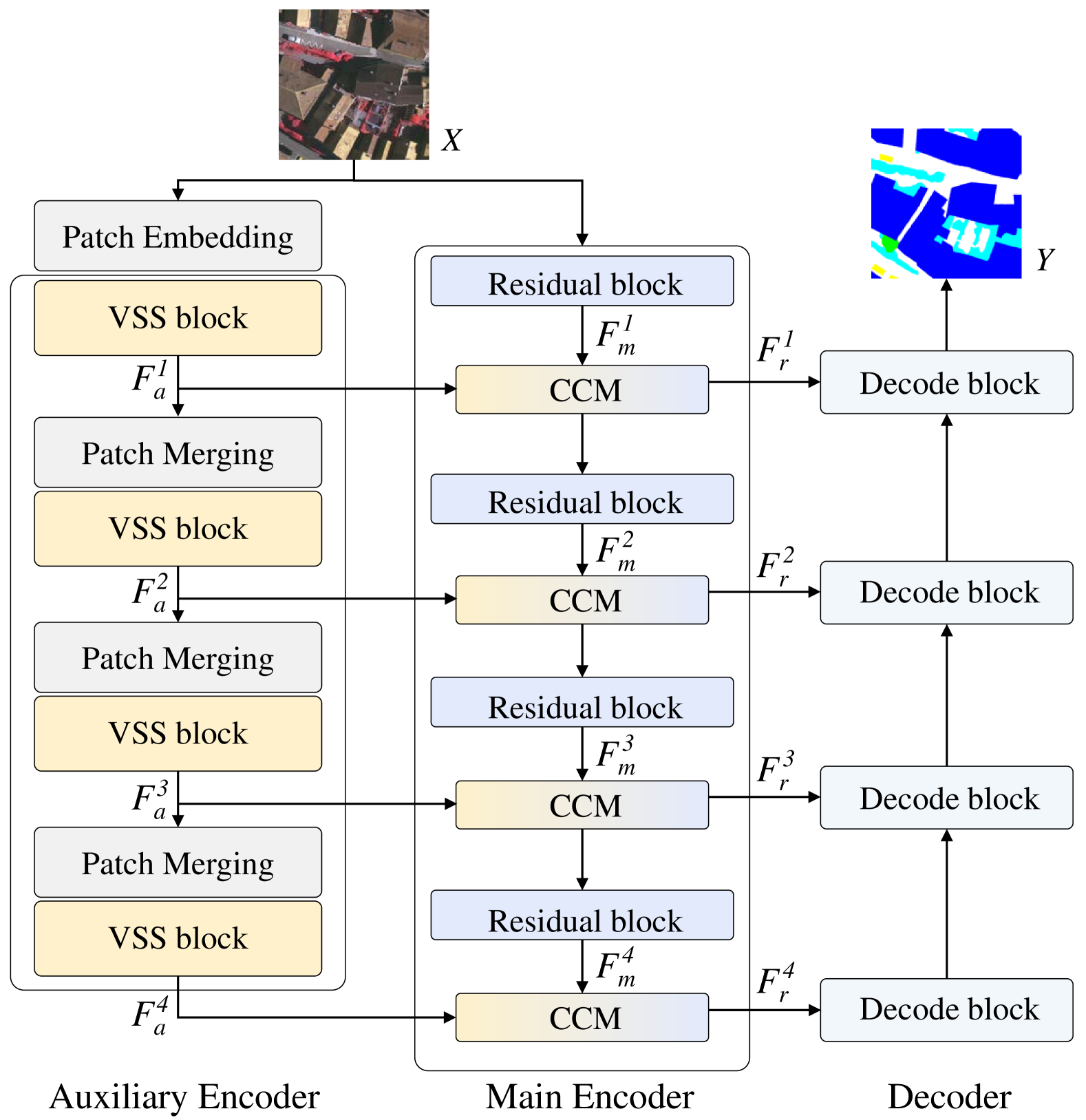
Abstract
Semantic segmentation of remote sensing images is a fundamental task in geoscience research. However, there are some significant shortcomings for the widely used convolutional neural networks (CNNs) and Transformers. The former is limited by its insufficient long-range modeling capabilities, while the latter is hampered by its computational complexity. Recently, a novel visual state space (VSS) model represented by Mamba has emerged, capable of modeling long-range relationships with linear computability. In this work, we propose a novel dual-branch network named remote sensing images semantic segmentation Mamba (RS3Mamba) to incorporate this innovative technology into remote sensing tasks. Specifically, RS3Mamba utilizes VSS blocks to construct an auxiliary branch, providing additional global information to convolution-based main branch. Moreover, considering the distinct characteristics of the two branches, we introduce a collaborative completion module (CCM) to enhance and fuse features from the dual-encoder. Experimental results on two widely used datasets, ISPRS Vaihingen and LoveDA Urban, demonstrate the effectiveness and potential of the proposed RS3Mamba. To the best of our knowledge, this is the first vision Mamba specifically designed for remote sensing images semantic segmentation. The source code will be made available at https://github.com/sstary/SSRS.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces a new visual state space model called RS3Mamba for semantic segmentation of remote sensing images
- Proposes an end-to-end deep learning framework that combines a convolutional neural network and a state space model
- Demonstrates improved performance over existing methods on several remote sensing image datasets
Plain English Explanation
The paper presents a new approach for analyzing and understanding the content of remote sensing images, such as satellite or aerial photographs. Remote sensing images are complex, containing a lot of detailed information about the landscape, buildings, roads, and other features. Accurately identifying and categorizing all the different elements in these images is an important task, with applications in urban planning, environmental monitoring, and more.
The key idea behind this research is to combine two powerful machine learning techniques - convolutional neural networks and state space models - to create a more effective system for semantic segmentation of remote sensing imagery. Convolutional neural networks are great at extracting visual features from images, while state space models can capture the underlying structure and relationships between different elements in the scene.
By integrating these two components, the RS3Mamba model is able to better model the complex spatial and semantic dependencies present in remote sensing data. This allows it to more accurately identify and segment different objects and land cover types, compared to existing methods. The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improvements in performance metrics like pixel-wise accuracy and intersection-over-union.
Overall, this research represents an important advance in the field of remote sensing image analysis, with the potential to enable more sophisticated and accurate monitoring and understanding of our environment from above.
Technical Explanation
The core of the RS3Mamba framework is a deep learning architecture that combines a convolutional neural network (CNN) encoder-decoder with a state space model (SSM). The CNN component extracts multi-scale spatial and semantic features from the input remote sensing image. These features are then passed to the SSM, which models the underlying structure and relationships between different semantic regions in the scene.
Specifically, the SSM uses a latent state variable to represent the hidden state of the scene, which evolves over spatial locations according to a transition function. This allows the model to capture long-range dependencies and contextual information that is important for accurate semantic segmentation. The SSM is trained end-to-end with the CNN, enabling the two components to learn complementary representations.
The authors propose several novel architectural designs and training strategies to improve the performance of the RS3Mamba model. This includes using a nested CNN encoder-decoder to extract features at multiple scales, and incorporating an attention mechanism to selectively focus on the most informative regions of the image. They also introduce a new loss function that combines pixel-wise classification error with a regularization term to encourage smooth and spatially coherent segmentation outputs.
Experiments on benchmark remote sensing datasets like Potsdam, Vaihingen, and DFC2020 show that the RS3Mamba model outperforms state-of-the-art semantic segmentation methods across a range of metrics. The authors attribute this to the model's ability to effectively capture the complex spatial and semantic structure of remote sensing scenes.
Critical Analysis
The authors have conducted a thorough empirical evaluation of the RS3Mamba model, demonstrating its advantages over existing approaches on multiple remote sensing datasets. However, the paper could be strengthened by a more in-depth discussion of the model's limitations and potential failure cases.
For example, the authors do not explore how the performance of RS3Mamba might degrade in the presence of challenging imaging conditions, such as cloud cover, atmospheric distortions, or low image resolution. Additionally, the paper does not address how the model might handle rare or novel object classes that are underrepresented in the training data.
Further research is also needed to better understand the internal workings of the state space model component and how it interacts with the CNN encoder-decoder. Ablation studies or visualization techniques could provide more insights into the specific mechanisms by which the SSM contributes to the overall segmentation performance.
Finally, while the authors highlight the potential applications of their work in domains like urban planning and environmental monitoring, they do not discuss any real-world deployment scenarios or the practical challenges that may arise in transitioning the RS3Mamba model from a research prototype to an operational system.
Conclusion
Overall, the RS3Mamba model represents an innovative and promising approach to semantic segmentation of remote sensing imagery. By combining the complementary strengths of convolutional neural networks and state space models, the authors have developed a powerful deep learning framework that can more effectively capture the complex spatial and semantic structure of remote sensing scenes.
The demonstrated performance improvements over existing methods suggest that RS3Mamba could have significant impact on a wide range of applications relying on accurate and granular understanding of landscape elements from overhead imagery. However, further research is needed to fully characterize the model's capabilities and limitations, as well as to address the practical challenges of deploying such a system in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Samba: Semantic Segmentation of Remotely Sensed Images with State Space Model
Qinfeng Zhu, Yuanzhi Cai, Yuan Fang, Yihan Yang, Cheng Chen, Lei Fan, Anh Nguyen
0
0
High-resolution remotely sensed images pose a challenge for commonly used semantic segmentation methods such as Convolutional Neural Network (CNN) and Vision Transformer (ViT). CNN-based methods struggle with handling such high-resolution images due to their limited receptive field, while ViT faces challenges in handling long sequences. Inspired by Mamba, which adopts a State Space Model (SSM) to efficiently capture global semantic information, we propose a semantic segmentation framework for high-resolution remotely sensed images, named Samba. Samba utilizes an encoder-decoder architecture, with Samba blocks serving as the encoder for efficient multi-level semantic information extraction, and UperNet functioning as the decoder. We evaluate Samba on the LoveDA, ISPRS Vaihingen, and ISPRS Potsdam datasets, comparing its performance against top-performing CNN and ViT methods. The results reveal that Samba achieved unparalleled performance on commonly used remote sensing datasets for semantic segmentation. Our proposed Samba demonstrates for the first time the effectiveness of SSM in semantic segmentation of remotely sensed images, setting a new benchmark in performance for Mamba-based techniques in this specific application. The source code and baseline implementations are available at https://github.com/zhuqinfeng1999/Samba.
4/12/2024
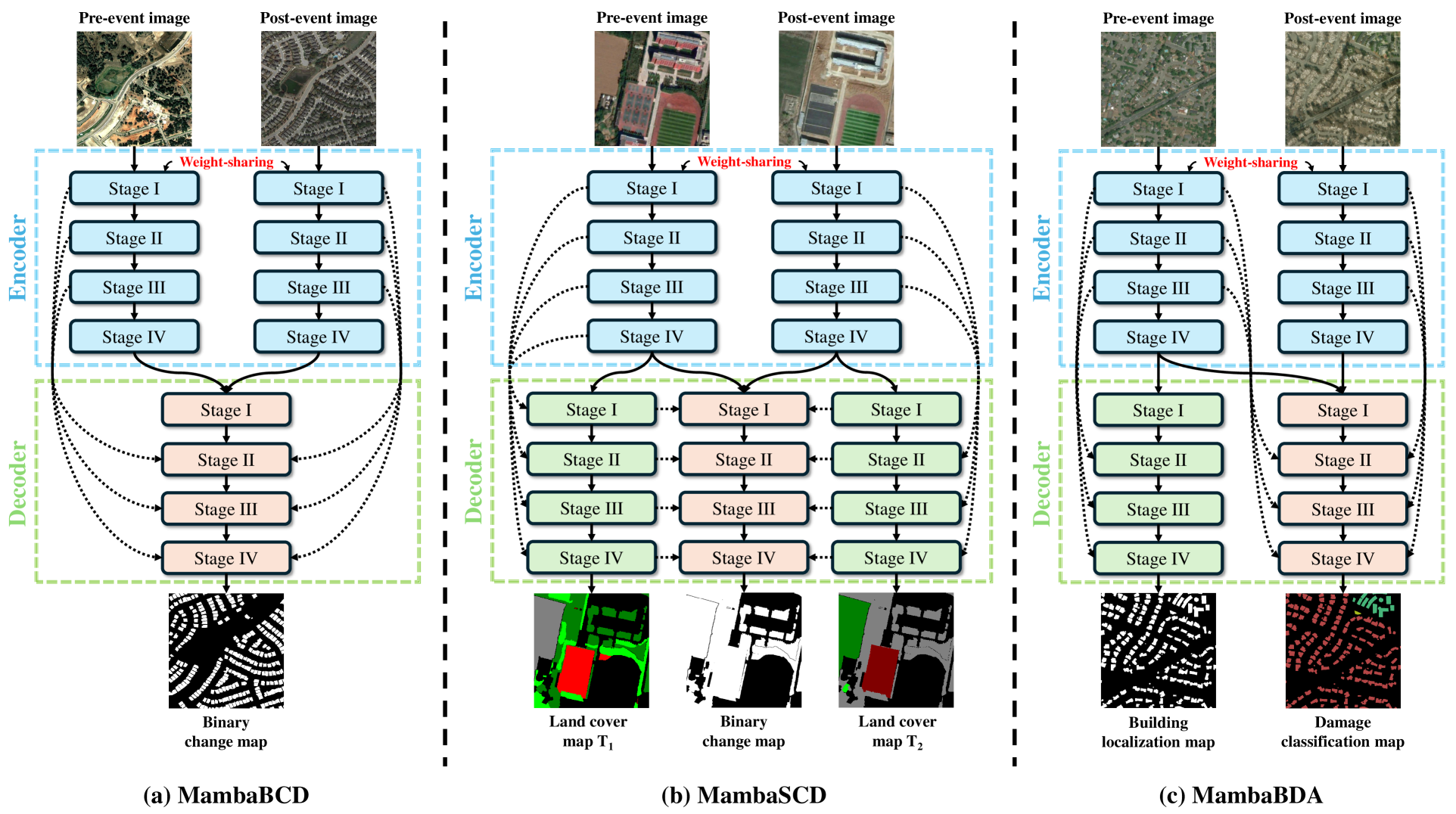
ChangeMamba: Remote Sensing Change Detection with Spatio-Temporal State Space Model
Hongruixuan Chen, Jian Song, Chengxi Han, Junshi Xia, Naoto Yokoya
0
0
Convolutional neural networks (CNN) and Transformers have made impressive progress in the field of remote sensing change detection (CD). However, both architectures have inherent shortcomings. Recently, the Mamba architecture, based on state space models, has shown remarkable performance in a series of natural language processing tasks, which can effectively compensate for the shortcomings of the above two architectures. In this paper, we explore for the first time the potential of the Mamba architecture for remote sensing CD tasks. We tailor the corresponding frameworks, called MambaBCD, MambaSCD, and MambaBDA, for binary change detection (BCD), semantic change detection (SCD), and building damage assessment (BDA), respectively. All three frameworks adopt the cutting-edge Visual Mamba architecture as the encoder, which allows full learning of global spatial contextual information from the input images. For the change decoder, which is available in all three architectures, we propose three spatio-temporal relationship modeling mechanisms, which can be naturally combined with the Mamba architecture and fully utilize its attribute to achieve spatio-temporal interaction of multi-temporal features, thereby obtaining accurate change information. On five benchmark datasets, our proposed frameworks outperform current CNN- and Transformer-based approaches without using any complex training strategies or tricks, fully demonstrating the potential of the Mamba architecture in CD tasks. Specifically, we obtained 83.11%, 88.39% and 94.19% F1 scores on the three BCD datasets SYSU, LEVIR-CD+, and WHU-CD; on the SCD dataset SECOND, we obtained 24.11% SeK; and on the BDA dataset xBD, we obtained 81.41% overall F1 score. Further experiments show that our architecture is quite robust to degraded data. The source code will be available in https://github.com/ChenHongruixuan/MambaCD
4/16/2024
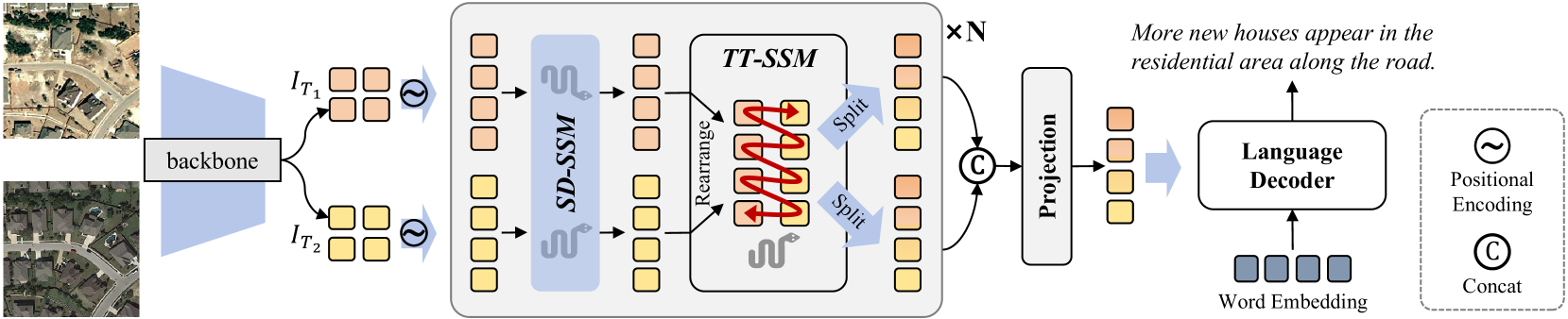
RSCaMa: Remote Sensing Image Change Captioning with State Space Model
Chenyang Liu, Keyan Chen, Bowen Chen, Haotian Zhang, Zhengxia Zou, Zhenwei Shi
0
0
Remote Sensing Image Change Captioning (RSICC) aims to describe surface changes between multi-temporal remote sensing images in language, including the changed object categories, locations, and dynamics of changing objects (e.g., added or disappeared). This poses challenges to spatial and temporal modeling of bi-temporal features. Despite previous methods progressing in the spatial change perception, there are still weaknesses in joint spatial-temporal modeling. To address this, in this paper, we propose a novel RSCaMa model, which achieves efficient joint spatial-temporal modeling through multiple CaMa layers, enabling iterative refinement of bi-temporal features. To achieve efficient spatial modeling, we introduce the recently popular Mamba (a state space model) with a global receptive field and linear complexity into the RSICC task and propose the Spatial Difference-aware SSM (SD-SSM), overcoming limitations of previous CNN- and Transformer-based methods in the receptive field and computational complexity. SD-SSM enhances the model's ability to capture spatial changes sharply. In terms of efficient temporal modeling, considering the potential correlation between the temporal scanning characteristics of Mamba and the temporality of the RSICC, we propose the Temporal-Traversing SSM (TT-SSM), which scans bi-temporal features in a temporal cross-wise manner, enhancing the model's temporal understanding and information interaction. Experiments validate the effectiveness of the efficient joint spatial-temporal modeling and demonstrate the outstanding performance of RSCaMa and the potential of the Mamba in the RSICC task. Additionally, we systematically compare three different language decoders, including Mamba, GPT-style decoder, and Transformer decoder, providing valuable insights for future RSICC research. The code will be available at emph{url{https://github.com/Chen-Yang-Liu/RSCaMa}}
5/3/2024

RS-Mamba for Large Remote Sensing Image Dense Prediction
Sijie Zhao, Hao Chen, Xueliang Zhang, Pengfeng Xiao, Lei Bai, Wanli Ouyang
0
0
Context modeling is critical for remote sensing image dense prediction tasks. Nowadays, the growing size of very-high-resolution (VHR) remote sensing images poses challenges in effectively modeling context. While transformer-based models possess global modeling capabilities, they encounter computational challenges when applied to large VHR images due to their quadratic complexity. The conventional practice of cropping large images into smaller patches results in a notable loss of contextual information. To address these issues, we propose the Remote Sensing Mamba (RSM) for dense prediction tasks in large VHR remote sensing images. RSM is specifically designed to capture the global context of remote sensing images with linear complexity, facilitating the effective processing of large VHR images. Considering that the land covers in remote sensing images are distributed in arbitrary spatial directions due to characteristics of remote sensing over-head imaging, the RSM incorporates an omnidirectional selective scan module to globally model the context of images in multiple directions, capturing large spatial features from various directions. Extensive experiments on semantic segmentation and change detection tasks across various land covers demonstrate the effectiveness of the proposed RSM. We designed simple yet effective models based on RSM, achieving state-of-the-art performance on dense prediction tasks in VHR remote sensing images without fancy training strategies. Leveraging the linear complexity and global modeling capabilities, RSM achieves better efficiency and accuracy than transformer-based models on large remote sensing images. Interestingly, we also demonstrated that our model generally performs better with a larger image size on dense prediction tasks. Our code is available at https://github.com/walking-shadow/Official_Remote_Sensing_Mamba.
4/11/2024