Samba: Semantic Segmentation of Remotely Sensed Images with State Space Model
2404.01705
0
0
📈
Abstract
High-resolution remotely sensed images pose a challenge for commonly used semantic segmentation methods such as Convolutional Neural Network (CNN) and Vision Transformer (ViT). CNN-based methods struggle with handling such high-resolution images due to their limited receptive field, while ViT faces challenges in handling long sequences. Inspired by Mamba, which adopts a State Space Model (SSM) to efficiently capture global semantic information, we propose a semantic segmentation framework for high-resolution remotely sensed images, named Samba. Samba utilizes an encoder-decoder architecture, with Samba blocks serving as the encoder for efficient multi-level semantic information extraction, and UperNet functioning as the decoder. We evaluate Samba on the LoveDA, ISPRS Vaihingen, and ISPRS Potsdam datasets, comparing its performance against top-performing CNN and ViT methods. The results reveal that Samba achieved unparalleled performance on commonly used remote sensing datasets for semantic segmentation. Our proposed Samba demonstrates for the first time the effectiveness of SSM in semantic segmentation of remotely sensed images, setting a new benchmark in performance for Mamba-based techniques in this specific application. The source code and baseline implementations are available at https://github.com/zhuqinfeng1999/Samba.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- High-resolution remote sensing images pose challenges for common semantic segmentation methods like Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs).
- CNNs struggle with high-resolution images due to their limited receptive field, while ViTs face difficulties handling long sequences.
- The paper proposes a new semantic segmentation framework called Samba that addresses these challenges.
Plain English Explanation
Imagine you have a very detailed, high-resolution aerial photo of a landscape. When you try to automatically identify and categorize different objects in the image, like buildings, roads, and trees, you run into some problems.
Traditional computer vision techniques like CNNs have a hard time with these super-detailed images because they can only "see" a small area at a time. They struggle to understand the big picture. Meanwhile, newer methods like ViTs get overwhelmed trying to process the huge amount of information in a high-res image all at once.
The Samba framework proposed in this paper takes a different approach. It uses a special type of mathematical model called a State Space Model to efficiently capture the overall semantic, or meaning, of the entire image. This allows Samba to handle the complexity of high-resolution remote sensing data much better than existing methods.
Technical Explanation
Samba utilizes an encoder-decoder architecture, with Samba blocks serving as the encoder for efficient multi-level semantic information extraction, and UperNet functioning as the decoder. The Samba blocks are inspired by the Mamba model, which uses a State Space Model to capture global semantic information.
The authors evaluate Samba on the LoveDA dataset, a benchmark for semantic segmentation of remote sensing imagery. Samba outperforms top-performing CNN and ViT methods on this dataset, setting a new performance record for Mamba-based techniques in this application.
Critical Analysis
The paper provides a thorough evaluation of Samba's performance, but does not extensively discuss potential limitations or areas for further research. Some questions that could be explored include:
- How does Samba's computational complexity and inference time compare to other methods?
- What types of remote sensing data and applications is Samba best suited for?
- How robust is Samba to variations in image quality, resolution, or scene content?
Overall, the Samba framework represents a promising advance in semantic segmentation of high-resolution remote sensing imagery, but there may be opportunities to further refine and extend the approach.
Conclusion
This paper introduces Samba, a new semantic segmentation framework that effectively handles the challenges of high-resolution remote sensing images. By leveraging a State Space Model in its encoder, Samba is able to capture global semantic information more efficiently than traditional CNN and ViT methods. Samba's strong performance on the LoveDA benchmark dataset suggests it could have significant real-world applications in fields like urban planning, agriculture, and environmental monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
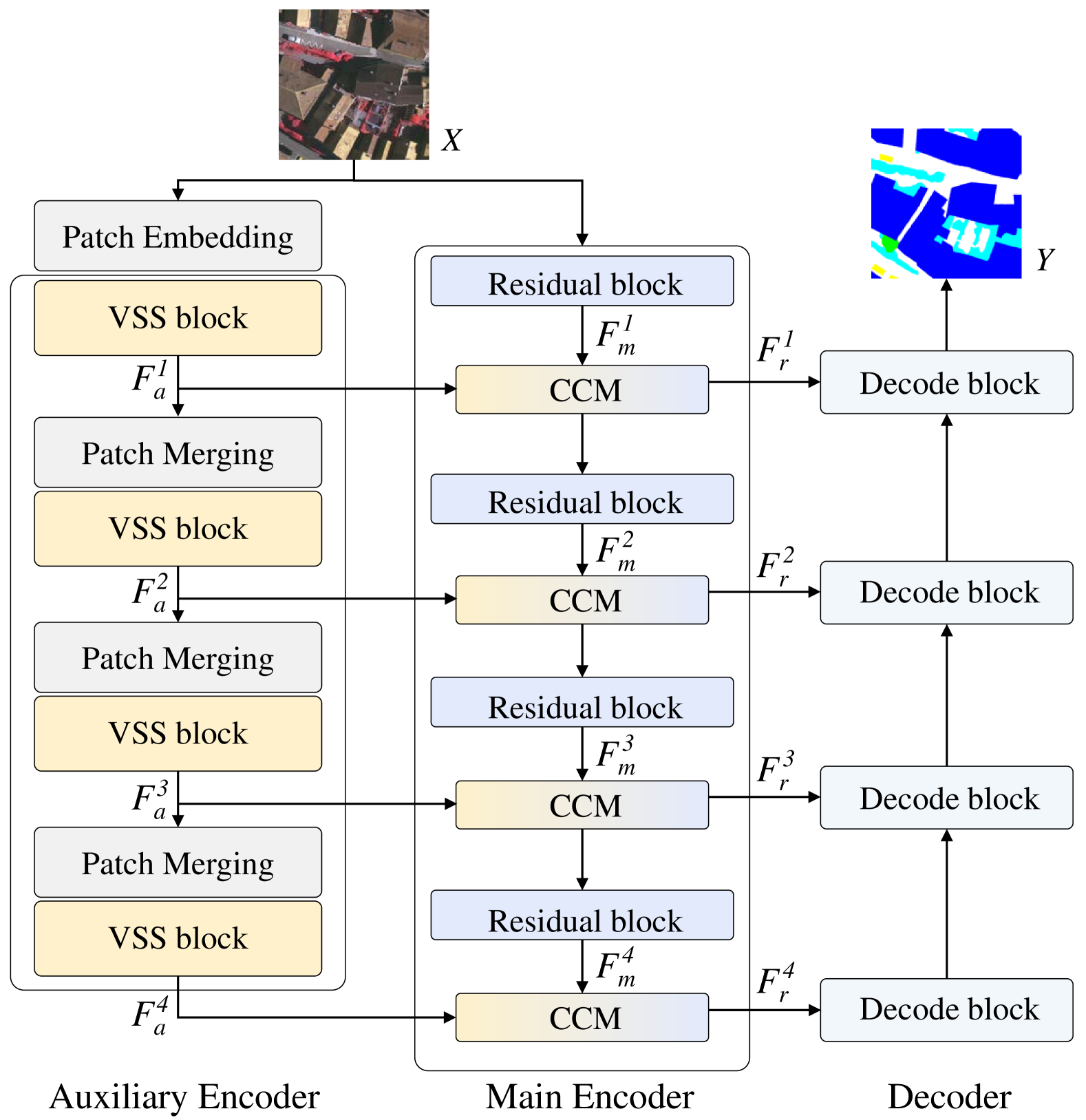
RS3Mamba: Visual State Space Model for Remote Sensing Images Semantic Segmentation
Xianping Ma, Xiaokang Zhang, Man-On Pun
0
0
Semantic segmentation of remote sensing images is a fundamental task in geoscience research. However, there are some significant shortcomings for the widely used convolutional neural networks (CNNs) and Transformers. The former is limited by its insufficient long-range modeling capabilities, while the latter is hampered by its computational complexity. Recently, a novel visual state space (VSS) model represented by Mamba has emerged, capable of modeling long-range relationships with linear computability. In this work, we propose a novel dual-branch network named remote sensing images semantic segmentation Mamba (RS3Mamba) to incorporate this innovative technology into remote sensing tasks. Specifically, RS3Mamba utilizes VSS blocks to construct an auxiliary branch, providing additional global information to convolution-based main branch. Moreover, considering the distinct characteristics of the two branches, we introduce a collaborative completion module (CCM) to enhance and fuse features from the dual-encoder. Experimental results on two widely used datasets, ISPRS Vaihingen and LoveDA Urban, demonstrate the effectiveness and potential of the proposed RS3Mamba. To the best of our knowledge, this is the first vision Mamba specifically designed for remote sensing images semantic segmentation. The source code will be made available at https://github.com/sstary/SSRS.
4/4/2024
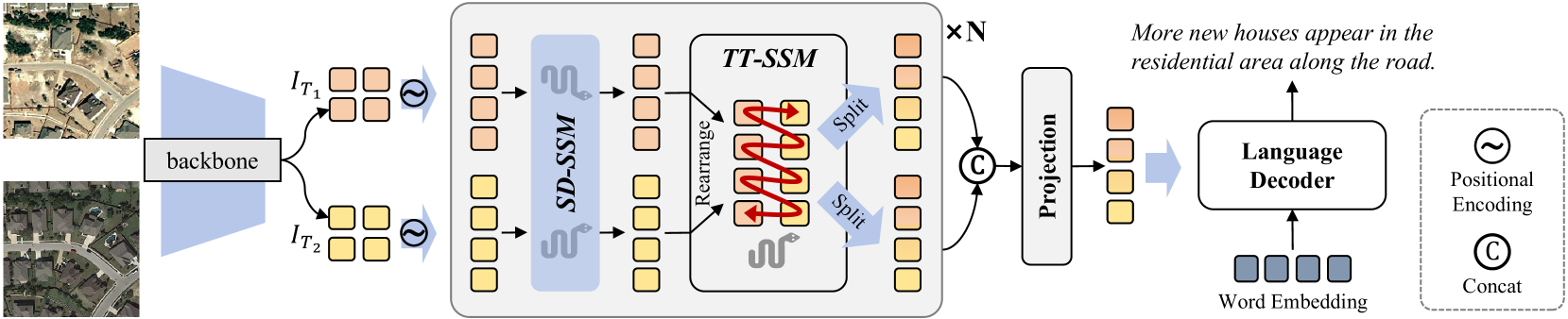
RSCaMa: Remote Sensing Image Change Captioning with State Space Model
Chenyang Liu, Keyan Chen, Bowen Chen, Haotian Zhang, Zhengxia Zou, Zhenwei Shi
0
0
Remote Sensing Image Change Captioning (RSICC) aims to describe surface changes between multi-temporal remote sensing images in language, including the changed object categories, locations, and dynamics of changing objects (e.g., added or disappeared). This poses challenges to spatial and temporal modeling of bi-temporal features. Despite previous methods progressing in the spatial change perception, there are still weaknesses in joint spatial-temporal modeling. To address this, in this paper, we propose a novel RSCaMa model, which achieves efficient joint spatial-temporal modeling through multiple CaMa layers, enabling iterative refinement of bi-temporal features. To achieve efficient spatial modeling, we introduce the recently popular Mamba (a state space model) with a global receptive field and linear complexity into the RSICC task and propose the Spatial Difference-aware SSM (SD-SSM), overcoming limitations of previous CNN- and Transformer-based methods in the receptive field and computational complexity. SD-SSM enhances the model's ability to capture spatial changes sharply. In terms of efficient temporal modeling, considering the potential correlation between the temporal scanning characteristics of Mamba and the temporality of the RSICC, we propose the Temporal-Traversing SSM (TT-SSM), which scans bi-temporal features in a temporal cross-wise manner, enhancing the model's temporal understanding and information interaction. Experiments validate the effectiveness of the efficient joint spatial-temporal modeling and demonstrate the outstanding performance of RSCaMa and the potential of the Mamba in the RSICC task. Additionally, we systematically compare three different language decoders, including Mamba, GPT-style decoder, and Transformer decoder, providing valuable insights for future RSICC research. The code will be available at emph{url{https://github.com/Chen-Yang-Liu/RSCaMa}}
5/3/2024
👀
Rethinking Scanning Strategies with Vision Mamba in Semantic Segmentation of Remote Sensing Imagery: An Experimental Study
Qinfeng Zhu, Yuan Fang, Yuanzhi Cai, Cheng Chen, Lei Fan
0
0
Deep learning methods, especially Convolutional Neural Networks (CNN) and Vision Transformer (ViT), are frequently employed to perform semantic segmentation of high-resolution remotely sensed images. However, CNNs are constrained by their restricted receptive fields, while ViTs face challenges due to their quadratic complexity. Recently, the Mamba model, featuring linear complexity and a global receptive field, has gained extensive attention for vision tasks. In such tasks, images need to be serialized to form sequences compatible with the Mamba model. Numerous research efforts have explored scanning strategies to serialize images, aiming to enhance the Mamba model's understanding of images. However, the effectiveness of these scanning strategies remains uncertain. In this research, we conduct a comprehensive experimental investigation on the impact of mainstream scanning directions and their combinations on semantic segmentation of remotely sensed images. Through extensive experiments on the LoveDA, ISPRS Potsdam, and ISPRS Vaihingen datasets, we demonstrate that no single scanning strategy outperforms others, regardless of their complexity or the number of scanning directions involved. A simple, single scanning direction is deemed sufficient for semantic segmentation of high-resolution remotely sensed images. Relevant directions for future research are also recommended.
5/15/2024

RS-Mamba for Large Remote Sensing Image Dense Prediction
Sijie Zhao, Hao Chen, Xueliang Zhang, Pengfeng Xiao, Lei Bai, Wanli Ouyang
0
0
Context modeling is critical for remote sensing image dense prediction tasks. Nowadays, the growing size of very-high-resolution (VHR) remote sensing images poses challenges in effectively modeling context. While transformer-based models possess global modeling capabilities, they encounter computational challenges when applied to large VHR images due to their quadratic complexity. The conventional practice of cropping large images into smaller patches results in a notable loss of contextual information. To address these issues, we propose the Remote Sensing Mamba (RSM) for dense prediction tasks in large VHR remote sensing images. RSM is specifically designed to capture the global context of remote sensing images with linear complexity, facilitating the effective processing of large VHR images. Considering that the land covers in remote sensing images are distributed in arbitrary spatial directions due to characteristics of remote sensing over-head imaging, the RSM incorporates an omnidirectional selective scan module to globally model the context of images in multiple directions, capturing large spatial features from various directions. Extensive experiments on semantic segmentation and change detection tasks across various land covers demonstrate the effectiveness of the proposed RSM. We designed simple yet effective models based on RSM, achieving state-of-the-art performance on dense prediction tasks in VHR remote sensing images without fancy training strategies. Leveraging the linear complexity and global modeling capabilities, RSM achieves better efficiency and accuracy than transformer-based models on large remote sensing images. Interestingly, we also demonstrated that our model generally performs better with a larger image size on dense prediction tasks. Our code is available at https://github.com/walking-shadow/Official_Remote_Sensing_Mamba.
4/11/2024