RSCaMa: Remote Sensing Image Change Captioning with State Space Model

0
Sign in to get full access
Overview
- This paper presents RSCaMa, a novel framework for captioning changes in remote sensing images using a state space model.
- The proposed approach, called Spatial Difference-guided State Space Model (SD-SSM), leverages the spatial difference between two remote sensing images to generate change captions.
- The authors also introduce Temporal Traveling State Space Model (TT-SSM) to capture the temporal dynamics of changes in remote sensing data.
- The RSCaMa framework integrates these two state space models to provide comprehensive change captions for remote sensing image pairs.
Plain English Explanation
The research paper describes a tool called RSCaMa that can automatically generate descriptions of changes between two remote sensing images. Remote sensing images are taken from satellites or aircraft and can show changes in the Earth's surface over time, such as the construction of new buildings or the spread of wildfires.
The key idea behind RSCaMa is to use a state space model, which is a mathematical framework that can capture the dynamics of a system over time. The researchers developed two specific state space models for this task:
- The Spatial Difference-guided State Space Model (SD-SSM) uses the differences between the spatial patterns in the two remote sensing images to generate captions describing the changes.
- The Temporal Traveling State Space Model (TT-SSM) looks at how the changes evolve over time, allowing it to provide more nuanced and accurate captions.
By combining these two state space models, the RSCaMa framework can generate detailed, human-readable descriptions of the changes observed in the remote sensing image pair. This can be very useful for applications like urban planning, environmental monitoring, and disaster response, where understanding the changes in the landscape is crucial.
Technical Explanation
The RSCaMa framework consists of two main components: the Spatial Difference-guided State Space Model (SD-SSM) and the Temporal Traveling State Space Model (TT-SSM).
The SD-SSM takes the spatial difference between two remote sensing images as input and uses a state space model to capture the spatial patterns of change. This allows the model to generate captions that describe the specific changes observed in the images, such as the construction of new buildings or the expansion of a forest.
The TT-SSM, on the other hand, focuses on the temporal dynamics of the changes. By modeling the evolution of the changes over time, the TT-SSM can provide more nuanced and accurate captions that reflect the temporal context of the observed changes.
The RSCaMa framework integrates these two state space models to leverage both the spatial and temporal information in the remote sensing image pair. The authors demonstrate the effectiveness of their approach through extensive experiments on several remote sensing datasets, showing that RSCaMa outperforms existing change captioning methods in terms of both quantitative metrics and human evaluation.
Critical Analysis
The RSCaMa framework represents a significant advancement in the field of remote sensing image change captioning, as it combines state-of-the-art spatial and temporal modeling techniques to generate high-quality, human-readable descriptions of changes in the landscape.
One potential limitation of the research, as mentioned in the paper, is the reliance on the availability of paired remote sensing images for training the models. In real-world scenarios, it may not always be easy to obtain such paired data, which could limit the practical application of the RSCaMa framework.
Additionally, while the authors demonstrate the effectiveness of their approach on several datasets, it would be valuable to see how RSCaMa performs on a wider range of remote sensing data, including imagery from different sensors, resolutions, and geographic regions. This could help identify any potential biases or limitations in the proposed methods.
Furthermore, the paper does not discuss the computational complexity or runtime performance of the RSCaMa framework, which could be an important consideration for practical deployment, especially in time-sensitive applications like disaster response.
Despite these potential areas for improvement, the RSCaMa framework represents an important contribution to the field of remote sensing image analysis, and the authors have clearly demonstrated the potential of state space models for capturing the spatial and temporal dynamics of changes in the landscape. Future research building on this work could further enhance the capabilities and practical applicability of change captioning systems for remote sensing data.
Conclusion
The RSCaMa framework proposed in this paper represents a significant advancement in the field of remote sensing image change captioning. By integrating the Spatial Difference-guided State Space Model (SD-SSM) and the Temporal Traveling State Space Model (TT-SSM), RSCaMa can generate high-quality, human-readable descriptions of changes observed in remote sensing image pairs.
The ability to automatically caption changes in the landscape has numerous practical applications, from urban planning and environmental monitoring to disaster response and climate change research. While the current approach has some limitations, the success of the RSCaMa framework demonstrates the potential of state space models for leveraging both spatial and temporal information in remote sensing data.
As the field of remote sensing continues to evolve, with the increasing availability of high-resolution, multi-temporal imagery, tools like RSCaMa will become increasingly valuable for extracting meaningful insights and supporting critical decision-making processes. Further research and development in this area could lead to even more powerful and versatile change captioning systems for remote sensing data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RSCaMa: Remote Sensing Image Change Captioning with State Space Model
Chenyang Liu, Keyan Chen, Bowen Chen, Haotian Zhang, Zhengxia Zou, Zhenwei Shi
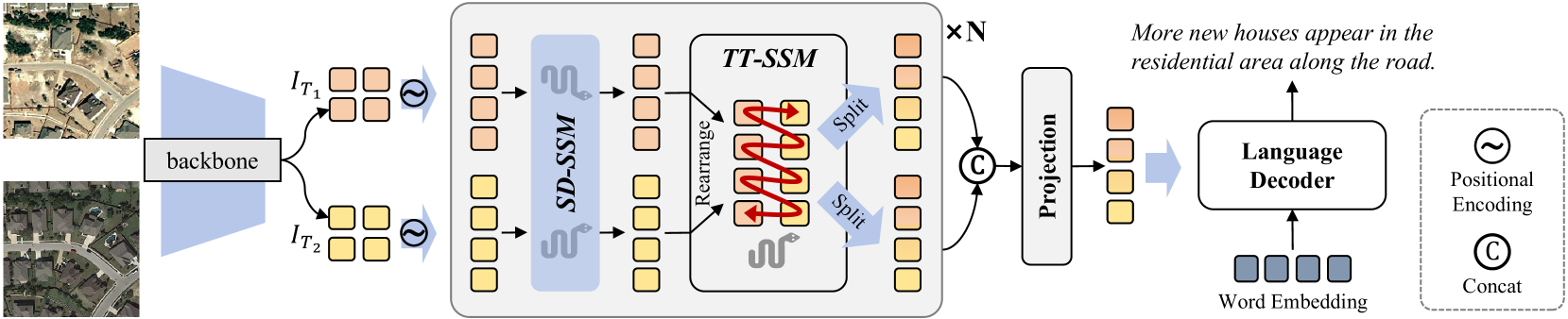
Remote Sensing Image Change Captioning (RSICC) aims to describe surface changes between multi-temporal remote sensing images in language, including the changed object categories, locations, and dynamics of changing objects (e.g., added or disappeared). This poses challenges to spatial and temporal modeling of bi-temporal features. Despite previous methods progressing in the spatial change perception, there are still weaknesses in joint spatial-temporal modeling. To address this, in this paper, we propose a novel RSCaMa model, which achieves efficient joint spatial-temporal modeling through multiple CaMa layers, enabling iterative refinement of bi-temporal features. To achieve efficient spatial modeling, we introduce the recently popular Mamba (a state space model) with a global receptive field and linear complexity into the RSICC task and propose the Spatial Difference-aware SSM (SD-SSM), overcoming limitations of previous CNN- and Transformer-based methods in the receptive field and computational complexity. SD-SSM enhances the model's ability to capture spatial changes sharply. In terms of efficient temporal modeling, considering the potential correlation between the temporal scanning characteristics of Mamba and the temporality of the RSICC, we propose the Temporal-Traversing SSM (TT-SSM), which scans bi-temporal features in a temporal cross-wise manner, enhancing the model's temporal understanding and information interaction. Experiments validate the effectiveness of the efficient joint spatial-temporal modeling and demonstrate the outstanding performance of RSCaMa and the potential of the Mamba in the RSICC task. Additionally, we systematically compare three different language decoders, including Mamba, GPT-style decoder, and Transformer decoder, providing valuable insights for future RSICC research. The code will be available at emph{url{https://github.com/Chen-Yang-Liu/RSCaMa}}
Read more5/22/2024
0
ChangeMamba: Remote Sensing Change Detection with Spatio-Temporal State Space Model
Hongruixuan Chen, Jian Song, Chengxi Han, Junshi Xia, Naoto Yokoya
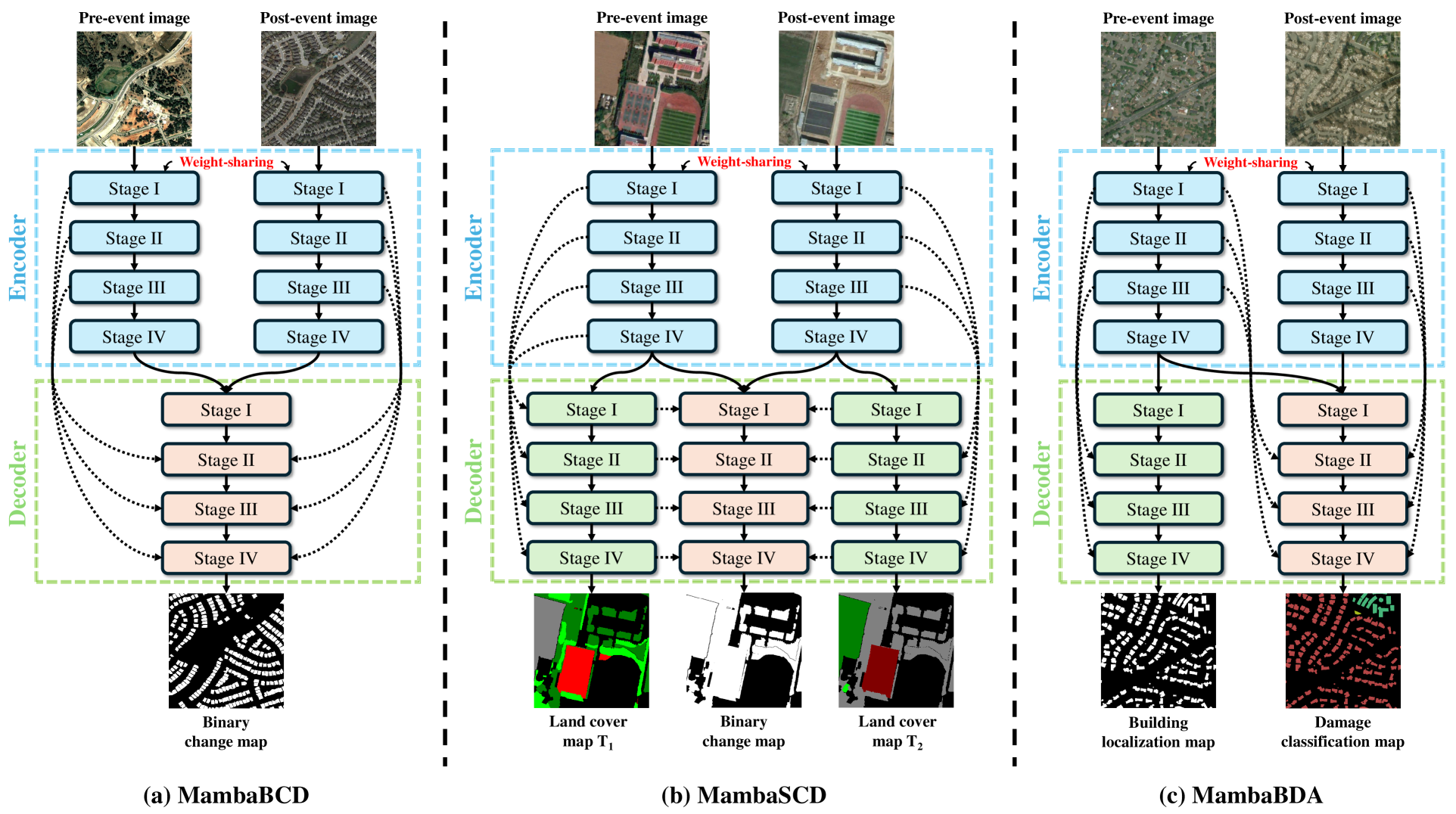
Convolutional neural networks (CNN) and Transformers have made impressive progress in the field of remote sensing change detection (CD). However, both architectures have inherent shortcomings: CNN are constrained by a limited receptive field that may hinder their ability to capture broader spatial contexts, while Transformers are computationally intensive, making them costly to train and deploy on large datasets. Recently, the Mamba architecture, based on state space models, has shown remarkable performance in a series of natural language processing tasks, which can effectively compensate for the shortcomings of the above two architectures. In this paper, we explore for the first time the potential of the Mamba architecture for remote sensing CD tasks. We tailor the corresponding frameworks, called MambaBCD, MambaSCD, and MambaBDA, for binary change detection (BCD), semantic change detection (SCD), and building damage assessment (BDA), respectively. All three frameworks adopt the cutting-edge Visual Mamba architecture as the encoder, which allows full learning of global spatial contextual information from the input images. For the change decoder, which is available in all three architectures, we propose three spatio-temporal relationship modeling mechanisms, which can be naturally combined with the Mamba architecture and fully utilize its attribute to achieve spatio-temporal interaction of multi-temporal features, thereby obtaining accurate change information. On five benchmark datasets, our proposed frameworks outperform current CNN- and Transformer-based approaches without using any complex training strategies or tricks, fully demonstrating the potential of the Mamba architecture in CD tasks. Further experiments show that our architecture is quite robust to degraded data. The source code will be available in https://github.com/ChenHongruixuan/MambaCD
Read more6/27/2024
0
RS3Mamba: Visual State Space Model for Remote Sensing Images Semantic Segmentation
Xianping Ma, Xiaokang Zhang, Man-On Pun
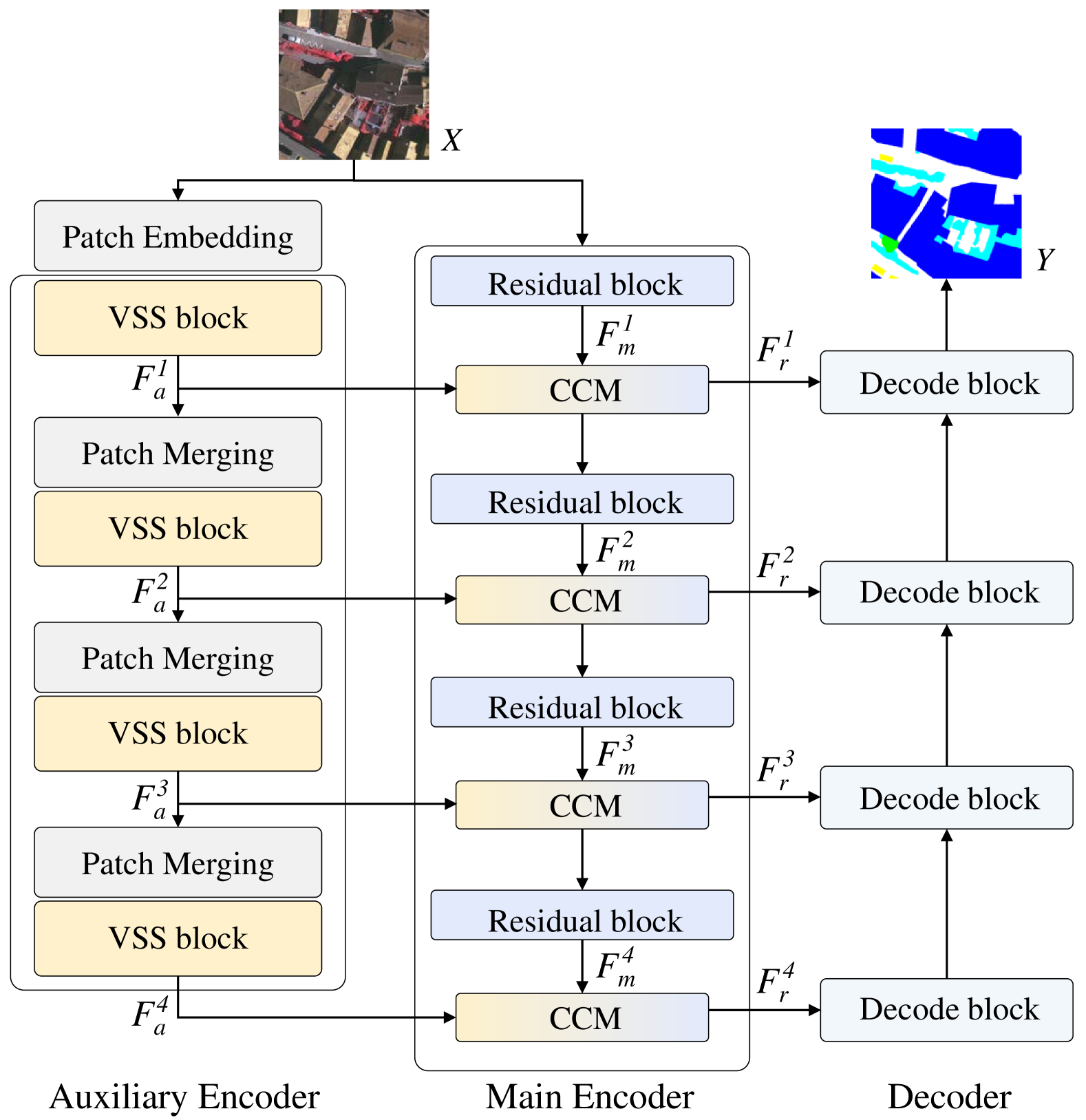
Semantic segmentation of remote sensing images is a fundamental task in geoscience research. However, there are some significant shortcomings for the widely used convolutional neural networks (CNNs) and Transformers. The former is limited by its insufficient long-range modeling capabilities, while the latter is hampered by its computational complexity. Recently, a novel visual state space (VSS) model represented by Mamba has emerged, capable of modeling long-range relationships with linear computability. In this work, we propose a novel dual-branch network named remote sensing images semantic segmentation Mamba (RS3Mamba) to incorporate this innovative technology into remote sensing tasks. Specifically, RS3Mamba utilizes VSS blocks to construct an auxiliary branch, providing additional global information to convolution-based main branch. Moreover, considering the distinct characteristics of the two branches, we introduce a collaborative completion module (CCM) to enhance and fuse features from the dual-encoder. Experimental results on two widely used datasets, ISPRS Vaihingen and LoveDA Urban, demonstrate the effectiveness and potential of the proposed RS3Mamba. To the best of our knowledge, this is the first vision Mamba specifically designed for remote sensing images semantic segmentation. The source code will be made available at https://github.com/sstary/SSRS.
Read more4/4/2024
📈
0
Diffusion-RSCC: Diffusion Probabilistic Model for Change Captioning in Remote Sensing Images
Xiaofei Yu, Yitong Li, Jie Ma
Remote sensing image change captioning (RSICC) aims at generating human-like language to describe the semantic changes between bi-temporal remote sensing image pairs. It provides valuable insights into environmental dynamics and land management. Unlike conventional change captioning task, RSICC involves not only retrieving relevant information across different modalities and generating fluent captions, but also mitigating the impact of pixel-level differences on terrain change localization. The pixel problem due to long time span decreases the accuracy of generated caption. Inspired by the remarkable generative power of diffusion model, we propose a probabilistic diffusion model for RSICC to solve the aforementioned problems. In training process, we construct a noise predictor conditioned on cross modal features to learn the distribution from the real caption distribution to the standard Gaussian distribution under the Markov chain. Meanwhile, a cross-mode fusion and a stacking self-attention module are designed for noise predictor in the reverse process. In testing phase, the well-trained noise predictor helps to estimate the mean value of the distribution and generate change captions step by step. Extensive experiments on the LEVIR-CC dataset demonstrate the effectiveness of our Diffusion-RSCC and its individual components. The quantitative results showcase superior performance over existing methods across both traditional and newly augmented metrics. The code and materials will be available online at https://github.com/Fay-Y/Diffusion-RSCC.
Read more5/22/2024