RSAdapter: Adapting Multimodal Models for Remote Sensing Visual Question Answering

0
Sign in to get full access
Introduction
This paper, "RSAdapter: Adapting Multimodal Models for Remote Sensing Visual Question Answering," explores a technique for fine-tuning large language models to perform visual question answering (VQA) tasks on remote sensing imagery. The researchers aim to develop a parameter-efficient approach that can leverage the knowledge captured in pre-trained multimodal models, rather than training models from scratch.
Related Work
Multimodal Frameworks for Remote Sensing
Previous research has explored developing multimodal frameworks for remote sensing image analysis and automating remote sensing tasks through language-guided AI agents. The authors of this paper build on these efforts by adapting multimodal models to the specific domain of remote sensing VQA.
Multimodal Instruction Following
The authors also note the relevance of recent work on unified multimodal instruction-following datasets and cross-modal adapter-based transfer learning, as these techniques could be applied to the remote sensing VQA task.
Multimodal Transformers
Additionally, the paper cites research on multimodal transformers using cross-channel attention, which provides relevant insights for the model architecture used in this work.
Plain English Explanation
The researchers in this paper wanted to find a way to use large, pre-trained language models to answer questions about remote sensing images, such as satellite or aerial photographs. Rather than training a new model from scratch, they explored a technique called "parameter-efficient fine-tuning" (PEFT) to adapt the pre-trained models to the remote sensing VQA task.
The key idea is to add a small number of extra "adapter" layers to the pre-trained model, which can learn the specific skills needed for the remote sensing VQA task, while keeping the majority of the model's parameters fixed. This allows the model to leverage the broad knowledge captured in the pre-trained model, while only needing to learn a relatively small number of task-specific parameters.
The researchers tested their approach on a remote sensing VQA dataset and found that it outperformed training a model from scratch, while using significantly fewer parameters. This suggests that the PEFT approach can be an effective way to adapt powerful multimodal models to specialized tasks like remote sensing image analysis, without having to start from zero.
Technical Explanation
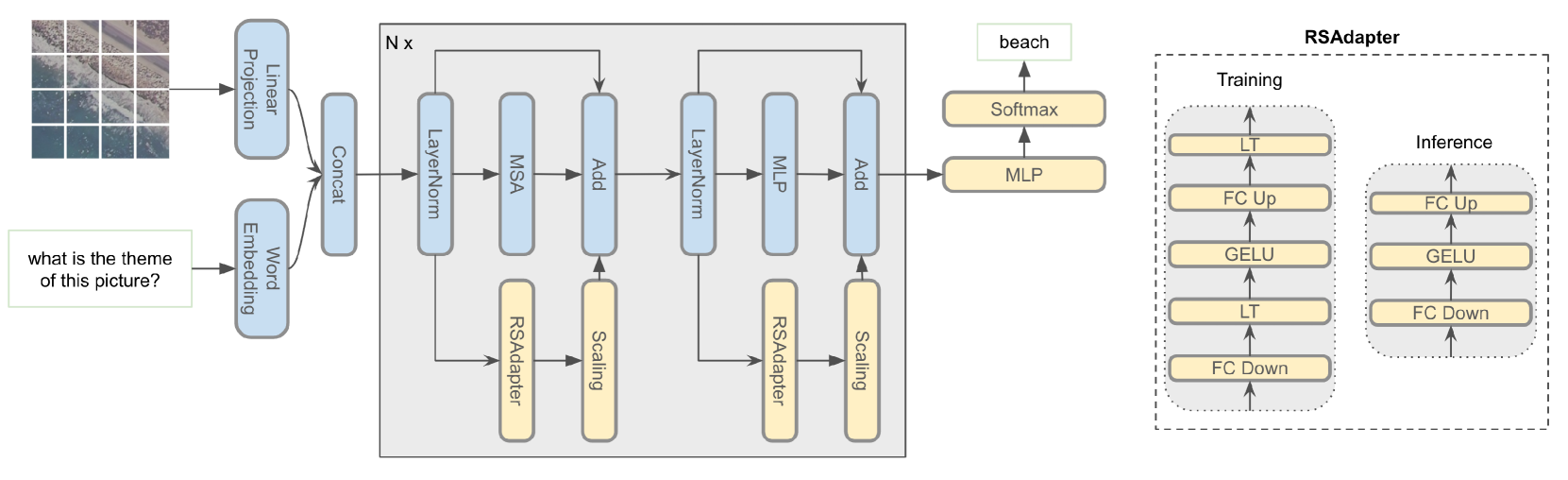
The paper introduces a technique called "RSAdapter" that uses parameter-efficient fine-tuning (PEFT) to adapt pre-trained multimodal models for remote sensing visual question answering (VQA). The key components of the approach are:
-
Model Architecture: The researchers use a pre-trained multimodal transformer model as the base, and add task-specific "adapter" layers that can be trained efficiently. The adapter layers learn to transform the inputs and outputs of the pre-trained model to better suit the remote sensing VQA task.
-
PEFT Training: Instead of fine-tuning the entire pre-trained model, the researchers only update the adapter layers, leaving the majority of the model's parameters frozen. This reduces the number of parameters that need to be learned, making the fine-tuning process more efficient.
-
Experimental Evaluation: The authors evaluate their RSAdapter approach on a remote sensing VQA dataset, comparing it to training a model from scratch. They find that RSAdapter outperforms the from-scratch model while using significantly fewer parameters.
Critical Analysis
The paper presents a promising approach for adapting powerful multimodal models to specialized tasks like remote sensing VQA. The PEFT technique allows the model to leverage the broad knowledge captured in the pre-trained model, while only requiring the learning of a small number of task-specific parameters.
However, the paper does not explore the limits of this approach. It would be valuable to understand how the performance and parameter efficiency of RSAdapter scales as the task complexity or dataset size increases. Additionally, the paper does not compare RSAdapter to other fine-tuning techniques, such as full model fine-tuning or layer-wise adaptive rates, which could provide further insights.
Furthermore, the paper focuses on a single remote sensing VQA dataset, so it is unclear how well the RSAdapter approach would generalize to other remote sensing tasks or datasets. Exploring the transferability of the adapted model to related remote sensing applications would strengthen the conclusions.
Conclusion
This paper presents a novel approach, RSAdapter, for adapting pre-trained multimodal models to the task of remote sensing visual question answering. By leveraging parameter-efficient fine-tuning, the researchers demonstrate that it is possible to take advantage of the broad knowledge captured in large language models, while only needing to learn a small number of task-specific parameters.
The results suggest that this approach can outperform training a model from scratch, while using significantly fewer parameters. This has important implications for the field of remote sensing, as it could enable the development of powerful, data-efficient AI systems for a range of image analysis tasks without the need for extensive domain-specific training data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RSAdapter: Adapting Multimodal Models for Remote Sensing Visual Question Answering
Yuduo Wang, Pedram Ghamisi
In recent years, with the rapid advancement of transformer models, transformer-based multimodal architectures have found wide application in various downstream tasks, including but not limited to Image Captioning, Visual Question Answering (VQA), and Image-Text Generation. However, contemporary approaches to Remote Sensing (RS) VQA often involve resource-intensive techniques, such as full fine-tuning of large models or the extraction of image-text features from pre-trained multimodal models, followed by modality fusion using decoders. These approaches demand significant computational resources and time, and a considerable number of trainable parameters are introduced. To address these challenges, we introduce a novel method known as RSAdapter, which prioritizes runtime and parameter efficiency. RSAdapter comprises two key components: the Parallel Adapter and an additional linear transformation layer inserted after each fully connected (FC) layer within the Adapter. This approach not only improves adaptation to pre-trained multimodal models but also allows the parameters of the linear transformation layer to be integrated into the preceding FC layers during inference, reducing inference costs. To demonstrate the effectiveness of RSAdapter, we conduct an extensive series of experiments using three distinct RS-VQA datasets and achieve state-of-the-art results on all three datasets. The code for RSAdapter is available online at https://github.com/Y-D-Wang/RSAdapter.
Read more6/21/2024

0
Towards a multimodal framework for remote sensing image change retrieval and captioning
Roger Ferrod, Luigi Di Caro, Dino Ienco
Recently, there has been increasing interest in multimodal applications that integrate text with other modalities, such as images, audio and video, to facilitate natural language interactions with multimodal AI systems. While applications involving standard modalities have been extensively explored, there is still a lack of investigation into specific data modalities such as remote sensing (RS) data. Despite the numerous potential applications of RS data, including environmental protection, disaster monitoring and land planning, available solutions are predominantly focused on specific tasks like classification, captioning and retrieval. These solutions often overlook the unique characteristics of RS data, such as its capability to systematically provide information on the same geographical areas over time. This ability enables continuous monitoring of changes in the underlying landscape. To address this gap, we propose a novel foundation model for bi-temporal RS image pairs, in the context of change detection analysis, leveraging Contrastive Learning and the LEVIR-CC dataset for both captioning and text-image retrieval. By jointly training a contrastive encoder and captioning decoder, our model add text-image retrieval capabilities, in the context of bi-temporal change detection, while maintaining captioning performances that are comparable to the state of the art. We release the source code and pretrained weights at: https://github.com/rogerferrod/RSICRC.
Read more6/21/2024

0
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agents
Wenjia Xu, Zijian Yu, Yixu Wang, Jiuniu Wang, Mugen Peng
An increasing number of models have achieved great performance in remote sensing tasks with the recent development of Large Language Models (LLMs) and Visual Language Models (VLMs). However, these models are constrained to basic vision and language instruction-tuning tasks, facing challenges in complex remote sensing applications. Additionally, these models lack specialized expertise in professional domains. To address these limitations, we propose a LLM-driven remote sensing intelligent agent named RS-Agent. Firstly, RS-Agent is powered by a large language model (LLM) that acts as its Central Controller, enabling it to understand and respond to various problems intelligently. Secondly, our RS-Agent integrates many high-performance remote sensing image processing tools, facilitating multi-tool and multi-turn conversations. Thirdly, our RS-Agent can answer professional questions by leveraging robust knowledge documents. We conducted experiments using several datasets, e.g., RSSDIVCS, RSVQA, and DOTAv1. The experimental results demonstrate that our RS-Agent delivers outstanding performance in many tasks, i.e., scene classification, visual question answering, and object counting tasks.
Read more6/12/2024

0
RS-GPT4V: A Unified Multimodal Instruction-Following Dataset for Remote Sensing Image Understanding
Linrui Xu, Ling Zhao, Wang Guo, Qiujun Li, Kewang Long, Kaiqi Zou, Yuhan Wang, Haifeng Li
The remote sensing image intelligence understanding model is undergoing a new profound paradigm shift which has been promoted by multi-modal large language model (MLLM), i.e. from the paradigm learning a domain model (LaDM) shifts to paradigm learning a pre-trained general foundation model followed by an adaptive domain model (LaGD). Under the new LaGD paradigm, the old datasets, which have led to advances in RSI intelligence understanding in the last decade, are no longer suitable for fire-new tasks. We argued that a new dataset must be designed to lighten tasks with the following features: 1) Generalization: training model to learn shared knowledge among tasks and to adapt to different tasks; 2) Understanding complex scenes: training model to understand the fine-grained attribute of the objects of interest, and to be able to describe the scene with natural language; 3) Reasoning: training model to be able to realize high-level visual reasoning. In this paper, we designed a high-quality, diversified, and unified multimodal instruction-following dataset for RSI understanding produced by GPT-4V and existing datasets, which we called RS-GPT4V. To achieve generalization, we used a (Question, Answer) which was deduced from GPT-4V via instruction-following to unify the tasks such as captioning and localization; To achieve complex scene, we proposed a hierarchical instruction description with local strategy in which the fine-grained attributes of the objects and their spatial relationships are described and global strategy in which all the local information are integrated to yield detailed instruction descript; To achieve reasoning, we designed multiple-turn QA pair to provide the reasoning ability for a model. The empirical results show that the fine-tuned MLLMs by RS-GPT4V can describe fine-grained information. The dataset is available at: https://github.com/GeoX-Lab/RS-GPT4V.
Read more6/19/2024