Towards a multimodal framework for remote sensing image change retrieval and captioning
2406.13424
0
0

Abstract
Recently, there has been increasing interest in multimodal applications that integrate text with other modalities, such as images, audio and video, to facilitate natural language interactions with multimodal AI systems. While applications involving standard modalities have been extensively explored, there is still a lack of investigation into specific data modalities such as remote sensing (RS) data. Despite the numerous potential applications of RS data, including environmental protection, disaster monitoring and land planning, available solutions are predominantly focused on specific tasks like classification, captioning and retrieval. These solutions often overlook the unique characteristics of RS data, such as its capability to systematically provide information on the same geographical areas over time. This ability enables continuous monitoring of changes in the underlying landscape. To address this gap, we propose a novel foundation model for bi-temporal RS image pairs, in the context of change detection analysis, leveraging Contrastive Learning and the LEVIR-CC dataset for both captioning and text-image retrieval. By jointly training a contrastive encoder and captioning decoder, our model add text-image retrieval capabilities, in the context of bi-temporal change detection, while maintaining captioning performances that are comparable to the state of the art. We release the source code and pretrained weights at: https://github.com/rogerferrod/RSICRC.
Create account to get full access
Overview
- This paper proposes a multimodal framework for remote sensing image change retrieval and captioning.
- The framework leverages contrastive learning to learn joint representations of image pairs and their corresponding captions.
- It enables tasks like text-image retrieval and image change captioning.
- The model is evaluated on several remote sensing datasets, demonstrating its effectiveness compared to unimodal baselines.
Plain English Explanation
The paper describes a new way to work with satellite or aerial images and the text that describes them. Often, we have pairs of images taken at different times of the same place, and we want to understand how the scene has changed. The researchers developed a system that can learn the connections between the image pairs and the text captions that describe the changes.
The key idea is to use "contrastive learning" - this means the system learns by comparing positive example image-text pairs to negative ones, finding the patterns that distinguish them. This allows the system to build a joint representation that captures the relationship between the images and their descriptions.
text-image retrieval - Once the system has learned these connections, it can be used to find relevant text for a given image, or find images that match a given text description.
image change captioning - It can also generate natural language descriptions of the changes observed between two images of the same place taken at different times.
The researchers tested their framework on several remote sensing datasets, and showed it outperformed approaches that only used the images or text separately. This multimodal approach seems promising for applications like monitoring land use changes, damage assessment, and more from satellite imagery.
Technical Explanation
The proposed framework uses a multimodal transformer architecture to learn joint representations of remote sensing image pairs and their corresponding change captions.
The key component is a contrastive learning module that encourages the model to learn meaningful connections between the visual and textual modalities. During training, the model is shown both positive image-caption pairs (where the caption describes the changes in the image pair) as well as negative pairs (where the caption does not match the changes).
By learning to distinguish these, the model develops a joint embedding space that effectively captures the relationship between the visual changes and their textual descriptions. This enables both text-image retrieval and image change captioning capabilities.
The model is evaluated on several remote sensing benchmarks, including RS-GCHR and RS-GPT4V. Experiments show it outperforms unimodal baselines on both retrieval and captioning tasks, demonstrating the value of the joint multimodal representation.
Critical Analysis
The paper presents a promising multimodal framework for remote sensing applications, but there are a few potential limitations and areas for future work:
-
Dataset Diversity: The evaluation is conducted on a limited set of benchmarks, primarily focused on urban and land cover changes. It would be valuable to assess the framework's performance on a wider range of remote sensing scenarios, such as natural disaster monitoring or agricultural applications.
-
Model Explainability: As with many deep learning models, the inner workings of the multimodal transformer can be opaque. Providing more insight into how the model reasons about the visual changes and generates the corresponding captions would be helpful for building trust and understanding its decision-making process.
-
Real-world Deployment: The paper does not address practical considerations for deploying such a system in real-world remote sensing workflows. Factors like computational efficiency, robustness to noisy or incomplete data, and integration with existing tools and pipelines should be explored.
-
Multimodal Interaction: The current framework treats the image and text modalities in a somewhat siloed manner, with the contrastive learning module as the primary link between them. Investigating cross-channel attention mechanisms or other techniques to more deeply integrate the visual and textual processing could lead to further performance gains.
Overall, the proposed framework represents an important step forward in multimodal remote sensing analysis, and the authors have identified a valuable application area. Addressing the points above could help strengthen the work and pave the way for more robust and practical multimodal remote sensing systems.
Conclusion
This paper introduces a novel multimodal framework for remote sensing image change retrieval and captioning. By leveraging contrastive learning to build joint representations of image pairs and their textual descriptions, the system can effectively connect visual changes with natural language explanations.
The demonstrated capabilities in text-image retrieval and image change captioning suggest this approach could have significant impact on a range of remote sensing applications, from land use monitoring to disaster response. Further research to address the identified limitations and expand the model's real-world applicability could make this an important tool for gaining meaningful insights from the wealth of remote sensing data available.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
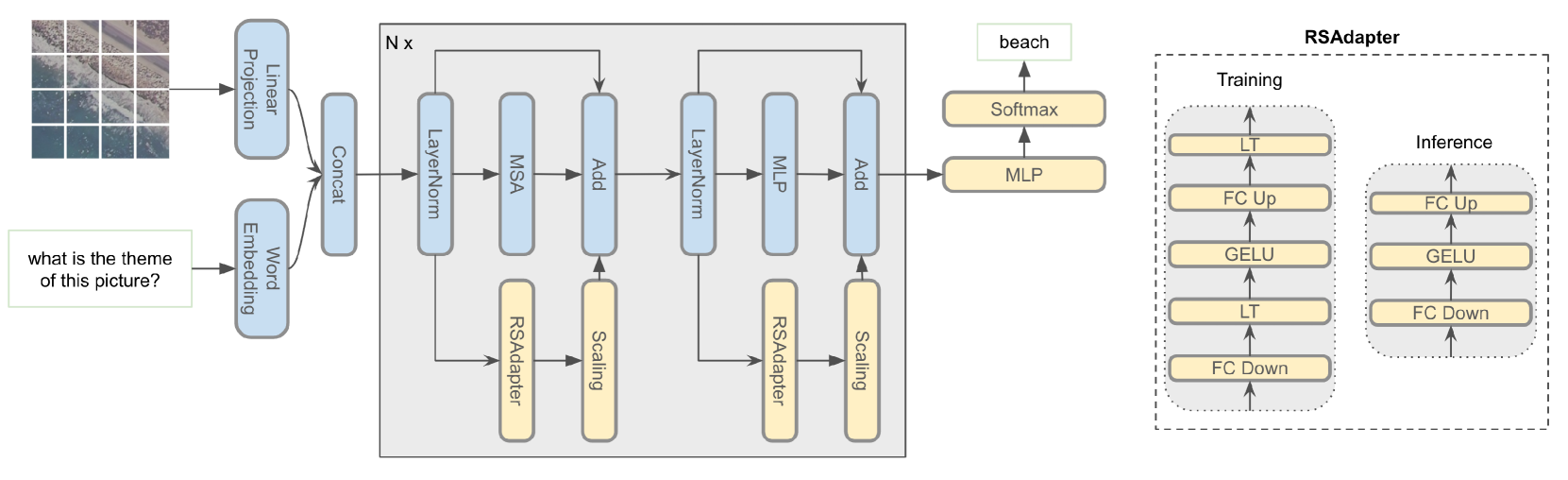
RSAdapter: Adapting Multimodal Models for Remote Sensing Visual Question Answering
Yuduo Wang, Pedram Ghamisi
0
0
In recent years, with the rapid advancement of transformer models, transformer-based multimodal architectures have found wide application in various downstream tasks, including but not limited to Image Captioning, Visual Question Answering (VQA), and Image-Text Generation. However, contemporary approaches to Remote Sensing (RS) VQA often involve resource-intensive techniques, such as full fine-tuning of large models or the extraction of image-text features from pre-trained multimodal models, followed by modality fusion using decoders. These approaches demand significant computational resources and time, and a considerable number of trainable parameters are introduced. To address these challenges, we introduce a novel method known as RSAdapter, which prioritizes runtime and parameter efficiency. RSAdapter comprises two key components: the Parallel Adapter and an additional linear transformation layer inserted after each fully connected (FC) layer within the Adapter. This approach not only improves adaptation to pre-trained multimodal models but also allows the parameters of the linear transformation layer to be integrated into the preceding FC layers during inference, reducing inference costs. To demonstrate the effectiveness of RSAdapter, we conduct an extensive series of experiments using three distinct RS-VQA datasets and achieve state-of-the-art results on all three datasets. The code for RSAdapter is available online at https://github.com/Y-D-Wang/RSAdapter.
6/21/2024
📈
Diffusion-RSCC: Diffusion Probabilistic Model for Change Captioning in Remote Sensing Images
Xiaofei Yu, Yitong Li, Jie Ma
0
0
Remote sensing image change captioning (RSICC) aims at generating human-like language to describe the semantic changes between bi-temporal remote sensing image pairs. It provides valuable insights into environmental dynamics and land management. Unlike conventional change captioning task, RSICC involves not only retrieving relevant information across different modalities and generating fluent captions, but also mitigating the impact of pixel-level differences on terrain change localization. The pixel problem due to long time span decreases the accuracy of generated caption. Inspired by the remarkable generative power of diffusion model, we propose a probabilistic diffusion model for RSICC to solve the aforementioned problems. In training process, we construct a noise predictor conditioned on cross modal features to learn the distribution from the real caption distribution to the standard Gaussian distribution under the Markov chain. Meanwhile, a cross-mode fusion and a stacking self-attention module are designed for noise predictor in the reverse process. In testing phase, the well-trained noise predictor helps to estimate the mean value of the distribution and generate change captions step by step. Extensive experiments on the LEVIR-CC dataset demonstrate the effectiveness of our Diffusion-RSCC and its individual components. The quantitative results showcase superior performance over existing methods across both traditional and newly augmented metrics. The code and materials will be available online at https://github.com/Fay-Y/Diffusion-RSCC.
5/22/2024

RS-GPT4V: A Unified Multimodal Instruction-Following Dataset for Remote Sensing Image Understanding
Linrui Xu, Ling Zhao, Wang Guo, Qiujun Li, Kewang Long, Kaiqi Zou, Yuhan Wang, Haifeng Li
0
0
The remote sensing image intelligence understanding model is undergoing a new profound paradigm shift which has been promoted by multi-modal large language model (MLLM), i.e. from the paradigm learning a domain model (LaDM) shifts to paradigm learning a pre-trained general foundation model followed by an adaptive domain model (LaGD). Under the new LaGD paradigm, the old datasets, which have led to advances in RSI intelligence understanding in the last decade, are no longer suitable for fire-new tasks. We argued that a new dataset must be designed to lighten tasks with the following features: 1) Generalization: training model to learn shared knowledge among tasks and to adapt to different tasks; 2) Understanding complex scenes: training model to understand the fine-grained attribute of the objects of interest, and to be able to describe the scene with natural language; 3) Reasoning: training model to be able to realize high-level visual reasoning. In this paper, we designed a high-quality, diversified, and unified multimodal instruction-following dataset for RSI understanding produced by GPT-4V and existing datasets, which we called RS-GPT4V. To achieve generalization, we used a (Question, Answer) which was deduced from GPT-4V via instruction-following to unify the tasks such as captioning and localization; To achieve complex scene, we proposed a hierarchical instruction description with local strategy in which the fine-grained attributes of the objects and their spatial relationships are described and global strategy in which all the local information are integrated to yield detailed instruction descript; To achieve reasoning, we designed multiple-turn QA pair to provide the reasoning ability for a model. The empirical results show that the fine-tuned MLLMs by RS-GPT4V can describe fine-grained information. The dataset is available at: https://github.com/GeoX-Lab/RS-GPT4V.
6/19/2024
🔎
Multimodal Transformer Using Cross-Channel attention for Object Detection in Remote Sensing Images
Bissmella Bahaduri, Zuheng Ming, Fangchen Feng, Anissa Mokraou
0
0
Object detection in Remote Sensing Images (RSI) is a critical task for numerous applications in Earth Observation (EO). Differing from object detection in natural images, object detection in remote sensing images faces challenges of scarcity of annotated data and the presence of small objects represented by only a few pixels. Multi-modal fusion has been determined to enhance the accuracy by fusing data from multiple modalities such as RGB, infrared (IR), lidar, and synthetic aperture radar (SAR). To this end, the fusion of representations at the mid or late stage, produced by parallel subnetworks, is dominant, with the disadvantages of increasing computational complexity in the order of the number of modalities and the creation of additional engineering obstacles. Using the cross-attention mechanism, we propose a novel multi-modal fusion strategy for mapping relationships between different channels at the early stage, enabling the construction of a coherent input by aligning the different modalities. By addressing fusion in the early stage, as opposed to mid or late-stage methods, our method achieves competitive and even superior performance compared to existing techniques. Additionally, we enhance the SWIN transformer by integrating convolution layers into the feed-forward of non-shifting blocks. This augmentation strengthens the model's capacity to merge separated windows through local attention, thereby improving small object detection. Extensive experiments prove the effectiveness of the proposed multimodal fusion module and the architecture, demonstrating their applicability to object detection in multimodal aerial imagery.
6/19/2024