RSET: Remapping-based Sorting Method for Emotion Transfer Speech Synthesis
2405.17028
0
0

Abstract
Although current Text-To-Speech (TTS) models are able to generate high-quality speech samples, there are still challenges in developing emotion intensity controllable TTS. Most existing TTS models achieve emotion intensity control by extracting intensity information from reference speeches. Unfortunately, limited by the lack of modeling for intra-class emotion intensity and the model's information decoupling capability, the generated speech cannot achieve fine-grained emotion intensity control and suffers from information leakage issues. In this paper, we propose an emotion transfer TTS model, which defines a remapping-based sorting method to model intra-class relative intensity information, combined with Mutual Information (MI) to decouple speaker and emotion information, and synthesizes expressive speeches with perceptible intensity differences. Experiments show that our model achieves fine-grained emotion control while preserving speaker information.
Create account to get full access
Overview
- The paper proposes RSET, a Remapping-based Sorting Method for Emotion Transfer Speech Synthesis.
- RSET aims to transfer emotional expressions from a source speech to a target speech while maintaining the target speaker's identity and intensity.
- The method involves mapping the emotional intensity of the source speech to the target speech using a remapping function, allowing for emotional transfer without distorting the target speaker's voice.
Plain English Explanation
The paper describes a technique called RSET (Remapping-based Sorting Method for Emotion Transfer Speech Synthesis) that allows you to take a person's speech and change the emotional tone of it, while still keeping the person's voice. For example, you could take a recording of someone speaking in a neutral tone and make it sound like they are speaking with anger or happiness, without it sounding like a different person entirely.
The key idea behind RSET is that it maps the emotional intensity of the source speech (the original recording) to the target speech (the desired emotional tone) using a special function. This allows the emotional expression to be transferred without significantly changing the target speaker's voice characteristics. So the end result is a speech sample that has the desired emotional tone, but still sounds like the original speaker.
This could be useful in a variety of applications, such as text-to-speech systems that need to convey emotion, or speech synthesis for animated characters. By allowing emotional expressions to be transferred, it can make spoken language sound more natural and expressive.
Technical Explanation
The RSET method works by first extracting the emotional intensity contour from the source speech using a deep learning model. This provides information about how the emotional expression varies over the course of the speech sample.
Next, RSET maps this emotional intensity contour onto the target speech using a remapping function. This function is designed to preserve the overall emotional dynamics while adjusting the intensity to match the target speaker. The authors explore different remapping functions and find that a piecewise linear function works well.
After applying the remapping, the emotional content of the target speech is modified, but its underlying voice characteristics are largely maintained. This allows the target speaker's identity and intensity to be preserved while the emotional expression is altered.
The authors evaluate RSET on a speech corpus with various emotional styles. They find that it outperforms previous emotion transfer methods in terms of preserving the target speaker's identity and intensity while successfully transferring the desired emotional expression.
Critical Analysis
The RSET method represents a promising approach for emotion transfer in speech synthesis. By decoupling the emotional expression from the underlying voice characteristics, it enables more natural-sounding emotional speech without distorting the target speaker.
However, the paper does not address some potential limitations. For example, the remapping function is manually designed and may not generalize well to all speakers and emotional expressions. An automated or learned remapping function could potentially improve performance.
Additionally, the evaluation is limited to a single speech corpus. More diverse testing, including real-world applications, would help validate the method's robustness and practical usefulness. Comparison to alternative emotion transfer techniques could also provide further insights.
Overall, RSET is a valuable contribution to the field of expressive speech synthesis. With further research and development, it could lead to more natural and engaging spoken language interfaces across a range of applications.
Conclusion
The RSET method proposed in this paper offers a novel approach to emotion transfer in speech synthesis. By remapping the emotional intensity of a source speech onto a target speaker, it can modify the emotional expression while preserving the target's identity and vocal characteristics. This could enable more natural-sounding emotional speech synthesis for applications like text-to-speech, virtual assistants, and animated characters.
While the paper demonstrates the effectiveness of RSET on a specific dataset, further research is needed to expand its capabilities and robustness. Exploring automated remapping functions, evaluating on more diverse datasets, and comparing to other emotion transfer techniques could help unlock the full potential of this approach. Overall, RSET represents an important step forward in the quest for expressive and personalized speech synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
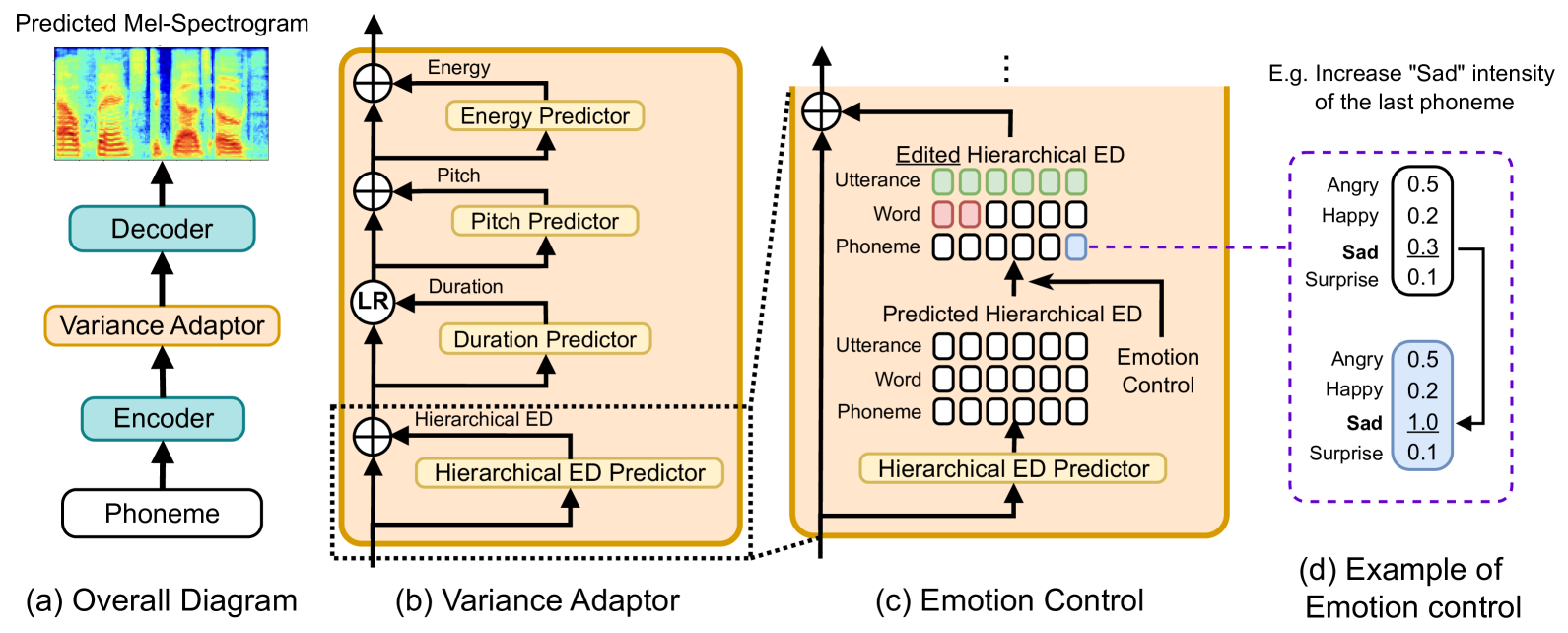
Hierarchical Emotion Prediction and Control in Text-to-Speech Synthesis
Sho Inoue, Kun Zhou, Shuai Wang, Haizhou Li
0
0
It remains a challenge to effectively control the emotion rendering in text-to-speech (TTS) synthesis. Prior studies have primarily focused on learning a global prosodic representation at the utterance level, which strongly correlates with linguistic prosody. Our goal is to construct a hierarchical emotion distribution (ED) that effectively encapsulates intensity variations of emotions at various levels of granularity, encompassing phonemes, words, and utterances. During TTS training, the hierarchical ED is extracted from the ground-truth audio and guides the predictor to establish a connection between emotional and linguistic prosody. At run-time inference, the TTS model generates emotional speech and, at the same time, provides quantitative control of emotion over the speech constituents. Both objective and subjective evaluations validate the effectiveness of the proposed framework in terms of emotion prediction and control.
5/16/2024

EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
Deok-Hyeon Cho, Hyung-Seok Oh, Seung-Bin Kim, Sang-Hoon Lee, Seong-Whan Lee
0
0
Despite rapid advances in the field of emotional text-to-speech (TTS), recent studies primarily focus on mimicking the average style of a particular emotion. As a result, the ability to manipulate speech emotion remains constrained to several predefined labels, compromising the ability to reflect the nuanced variations of emotion. In this paper, we propose EmoSphere-TTS, which synthesizes expressive emotional speech by using a spherical emotion vector to control the emotional style and intensity of the synthetic speech. Without any human annotation, we use the arousal, valence, and dominance pseudo-labels to model the complex nature of emotion via a Cartesian-spherical transformation. Furthermore, we propose a dual conditional adversarial network to improve the quality of generated speech by reflecting the multi-aspect characteristics. The experimental results demonstrate the model ability to control emotional style and intensity with high-quality expressive speech.
6/13/2024

Emotion-Aware Speech Self-Supervised Representation Learning with Intensity Knowledge
Rui Liu, Zening Ma
0
0
Speech Self-Supervised Learning (SSL) has demonstrated considerable efficacy in various downstream tasks. Nevertheless, prevailing self-supervised models often overlook the incorporation of emotion-related prior information, thereby neglecting the potential enhancement of emotion task comprehension through emotion prior knowledge in speech. In this paper, we propose an emotion-aware speech representation learning with intensity knowledge. Specifically, we extract frame-level emotion intensities using an established speech-emotion understanding model. Subsequently, we propose a novel emotional masking strategy (EMS) to incorporate emotion intensities into the masking process. We selected two representative models based on Transformer and CNN, namely MockingJay and Non-autoregressive Predictive Coding (NPC), and conducted experiments on IEMOCAP dataset. Experiments have demonstrated that the representations derived from our proposed method outperform the original model in SER task.
6/12/2024
❗
MM-TTS: A Unified Framework for Multimodal, Prompt-Induced Emotional Text-to-Speech Synthesis
Xiang Li, Zhi-Qi Cheng, Jun-Yan He, Xiaojiang Peng, Alexander G. Hauptmann
0
0
Emotional Text-to-Speech (E-TTS) synthesis has gained significant attention in recent years due to its potential to enhance human-computer interaction. However, current E-TTS approaches often struggle to capture the complexity of human emotions, primarily relying on oversimplified emotional labels or single-modality inputs. To address these limitations, we propose the Multimodal Emotional Text-to-Speech System (MM-TTS), a unified framework that leverages emotional cues from multiple modalities to generate highly expressive and emotionally resonant speech. MM-TTS consists of two key components: (1) the Emotion Prompt Alignment Module (EP-Align), which employs contrastive learning to align emotional features across text, audio, and visual modalities, ensuring a coherent fusion of multimodal information; and (2) the Emotion Embedding-Induced TTS (EMI-TTS), which integrates the aligned emotional embeddings with state-of-the-art TTS models to synthesize speech that accurately reflects the intended emotions. Extensive evaluations across diverse datasets demonstrate the superior performance of MM-TTS compared to traditional E-TTS models. Objective metrics, including Word Error Rate (WER) and Character Error Rate (CER), show significant improvements on ESD dataset, with MM-TTS achieving scores of 7.35% and 3.07%, respectively. Subjective assessments further validate that MM-TTS generates speech with emotional fidelity and naturalness comparable to human speech. Our code and pre-trained models are publicly available at https://anonymous.4open.science/r/MMTTS-D214
4/30/2024