S-HR-VQVAE: Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder for Video Prediction
2307.06701
0
0
📶
Abstract
We address the video prediction task by putting forth a novel model that combines (i) our recently proposed hierarchical residual vector quantized variational autoencoder (HR-VQVAE), and (ii) a novel spatiotemporal PixelCNN (ST-PixelCNN). We refer to this approach as a sequential hierarchical residual learning vector quantized variational autoencoder (S-HR-VQVAE). By leveraging the intrinsic capabilities of HR-VQVAE at modeling still images with a parsimonious representation, combined with the ST-PixelCNN's ability at handling spatiotemporal information, S-HR-VQVAE can better deal with chief challenges in video prediction. These include learning spatiotemporal information, handling high dimensional data, combating blurry prediction, and implicit modeling of physical characteristics. Extensive experimental results on the KTH Human Action and Moving-MNIST tasks demonstrate that our model compares favorably against top video prediction techniques both in quantitative and qualitative evaluations despite a much smaller model size. Finally, we boost S-HR-VQVAE by proposing a novel training method to jointly estimate the HR-VQVAE and ST-PixelCNN parameters.
Create account to get full access
Overview
- The researchers propose a novel model called Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder (S-HR-VQVAE) for the video prediction task.
- S-HR-VQVAE combines two key components: (i) the Hierarchical Residual Vector Quantized Variational Autoencoder (HR-VQVAE), and (ii) a novel Spatiotemporal PixelCNN (ST-PixelCNN).
- By leveraging the strengths of HR-VQVAE in modeling still images and the ST-PixelCNN's ability to handle spatiotemporal information, S-HR-VQVAE can better address challenges in video prediction.
Plain English Explanation
The researchers have developed a new model called S-HR-VQVAE to tackle the problem of video prediction. Video prediction is the task of generating future frames of a video sequence based on past frames. This is a challenging problem because it requires capturing both the spatial information within each frame and the temporal relationships between frames.
S-HR-VQVAE combines two key components to address these challenges. The first is a [object Object], which is a type of neural network that can efficiently represent and reconstruct still images. The second is a novel Spatiotemporal PixelCNN (ST-PixelCNN), which is designed to model the complex spatiotemporal relationships in video data.
By bringing these two components together, S-HR-VQVAE can effectively learn to predict future video frames. It can capture the spatial structure of individual frames using HR-VQVAE, and the temporal dynamics between frames using ST-PixelCNN. This allows the model to generate high-quality video predictions while using a relatively small model size compared to other state-of-the-art video prediction techniques.
Technical Explanation
The key components of S-HR-VQVAE are the [object Object] and the novel Spatiotemporal PixelCNN (ST-PixelCNN).
The HR-VQVAE is a type of variational autoencoder that can efficiently represent and reconstruct still images using a parsimonious representation. It does this by incorporating a hierarchical and residual structure, as well as vector quantization, which allows it to capture the essential visual features of an image.
The ST-PixelCNN is designed to model the complex spatiotemporal relationships in video data. It extends the traditional PixelCNN architecture, which generates images pixel-by-pixel in an autoregressive manner, to handle the temporal dimension of video. The ST-PixelCNN can thus predict future video frames by considering both the spatial structure of each frame and the temporal dependencies between frames.
By combining the strengths of HR-VQVAE and ST-PixelCNN, S-HR-VQVAE can address key challenges in video prediction, such as learning spatiotemporal information, handling high-dimensional data, reducing blurry predictions, and implicitly modeling physical characteristics.
The researchers evaluate S-HR-VQVAE on the KTH Human Action and Moving-MNIST tasks, and find that it outperforms other state-of-the-art video prediction techniques in both quantitative and qualitative measures, while using a much smaller model size.
Critical Analysis
The paper presents a well-designed and promising approach to video prediction, leveraging the complementary strengths of HR-VQVAE and ST-PixelCNN. The researchers acknowledge some limitations, such as the need for further research to improve the joint training of the two components and to explore the model's ability to handle more complex video datasets.
One potential area for further investigation is the generalization of S-HR-VQVAE to tasks beyond video prediction, such as [object Object] or [object Object]. The [object Object] framework could be an interesting direction to explore in this context.
Additionally, the researchers could investigate the potential of incorporating temporal inductive biases, inspired by biological mechanisms like [object Object], to further enhance the model's ability to capture the complex spatiotemporal dynamics in video data.
Overall, the S-HR-VQVAE model presents a compelling approach to video prediction, and the critical analysis highlights several avenues for potential future research to build upon this work.
Conclusion
The researchers have proposed a novel video prediction model called S-HR-VQVAE, which combines a Hierarchical Residual Vector Quantized Variational Autoencoder (HR-VQVAE) and a Spatiotemporal PixelCNN (ST-PixelCNN). By leveraging the strengths of these two components, S-HR-VQVAE can effectively capture the spatial and temporal information in video data, leading to improved video prediction performance compared to other state-of-the-art techniques.
The key contributions of this work include the development of the S-HR-VQVAE model, its successful application to video prediction tasks, and the insights gained into the complementary roles of HR-VQVAE and ST-PixelCNN in addressing the challenges of video prediction. This research represents an important step forward in the field of video understanding and generation, with potential applications in areas such as video compression, video summarization, and video-based action recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
RAQ-VAE: Rate-Adaptive Vector-Quantized Variational Autoencoder
Jiwan Seo, Joonhyuk Kang
0
0
Vector Quantized Variational AutoEncoder (VQ-VAE) is an established technique in machine learning for learning discrete representations across various modalities. However, its scalability and applicability are limited by the need to retrain the model to adjust the codebook for different data or model scales. We introduce the Rate-Adaptive VQ-VAE (RAQ-VAE) framework, which addresses this challenge with two novel codebook representation methods: a model-based approach using a clustering-based technique on an existing well-trained VQ-VAE model, and a data-driven approach utilizing a sequence-to-sequence (Seq2Seq) model for variable-rate codebook generation. Our experiments demonstrate that RAQ-VAE achieves effective reconstruction performance across multiple rates, often outperforming conventional fixed-rate VQ-VAE models. This work enhances the adaptability and performance of VQ-VAEs, with broad applications in data reconstruction, generation, and computer vision tasks.
5/24/2024

CV-VAE: A Compatible Video VAE for Latent Generative Video Models
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, Ying Shan
0
0
Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
5/31/2024
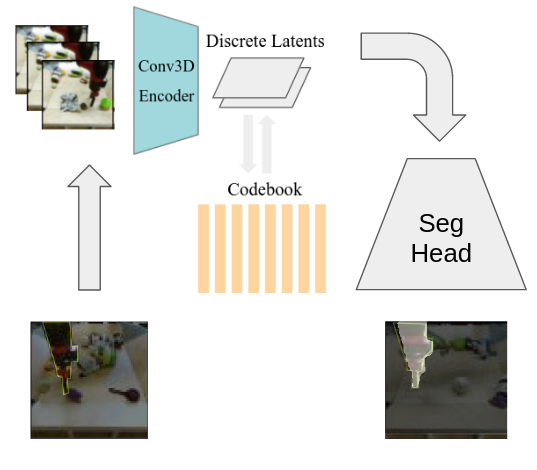
Video Prediction Models as General Visual Encoders
James Maier, Nishanth Mohankumar
0
0
This study explores the potential of open-source video conditional generation models as encoders for downstream tasks, focusing on instance segmentation using the BAIR Robot Pushing Dataset. The researchers propose using video prediction models as general visual encoders, leveraging their ability to capture critical spatial and temporal information which is essential for tasks such as instance segmentation. Inspired by human vision studies, particularly Gestalts principle of common fate, the approach aims to develop a latent space representative of motion from images to effectively discern foreground from background information. The researchers utilize a 3D Vector-Quantized Variational Autoencoder 3D VQVAE video generative encoder model conditioned on an input frame, coupled with downstream segmentation tasks. Experiments involve adapting pre-trained video generative models, analyzing their latent spaces, and training custom decoders for foreground-background segmentation. The findings demonstrate promising results in leveraging generative pretext learning for downstream tasks, working towards enhanced scene analysis and segmentation in computer vision applications.
5/28/2024
🗣️
A vector quantized masked autoencoder for audiovisual speech emotion recognition
Samir Sadok, Simon Leglaive, Renaud S'eguier
0
0
The limited availability of labeled data is a major challenge in audiovisual speech emotion recognition (SER). Self-supervised learning approaches have recently been proposed to mitigate the need for labeled data in various applications. This paper proposes the VQ-MAE-AV model, a vector quantized masked autoencoder (MAE) designed for audiovisual speech self-supervised representation learning and applied to SER. Unlike previous approaches, the proposed method employs a self-supervised paradigm based on discrete audio and visual speech representations learned by vector quantized variational autoencoders. A multimodal MAE with self- or cross-attention mechanisms is proposed to fuse the audio and visual speech modalities and to learn local and global representations of the audiovisual speech sequence, which are then used for an SER downstream task. Experimental results show that the proposed approach, which is pre-trained on the VoxCeleb2 database and fine-tuned on standard emotional audiovisual speech datasets, outperforms the state-of-the-art audiovisual SER methods. Extensive ablation experiments are also provided to assess the contribution of the different model components.
5/16/2024