Video Prediction Models as General Visual Encoders
2405.16382
0
0
Abstract
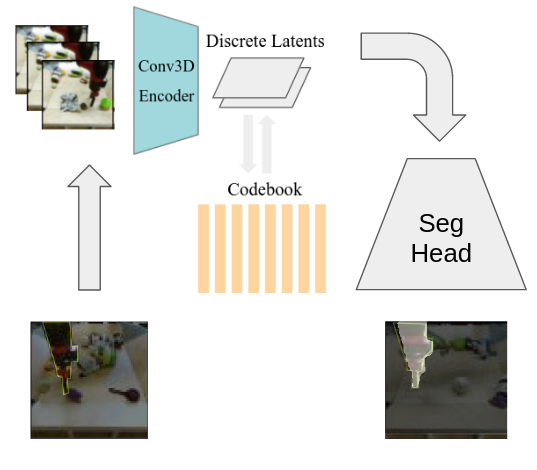
This study explores the potential of open-source video conditional generation models as encoders for downstream tasks, focusing on instance segmentation using the BAIR Robot Pushing Dataset. The researchers propose using video prediction models as general visual encoders, leveraging their ability to capture critical spatial and temporal information which is essential for tasks such as instance segmentation. Inspired by human vision studies, particularly Gestalts principle of common fate, the approach aims to develop a latent space representative of motion from images to effectively discern foreground from background information. The researchers utilize a 3D Vector-Quantized Variational Autoencoder 3D VQVAE video generative encoder model conditioned on an input frame, coupled with downstream segmentation tasks. Experiments involve adapting pre-trained video generative models, analyzing their latent spaces, and training custom decoders for foreground-background segmentation. The findings demonstrate promising results in leveraging generative pretext learning for downstream tasks, working towards enhanced scene analysis and segmentation in computer vision applications.
Create account to get full access
Overview
- This paper explores the potential of video prediction models to serve as general-purpose visual encoders.
- The authors investigate whether these models can learn representations that are useful for a wide range of computer vision tasks, beyond just video prediction.
- Key findings include that video prediction models can indeed learn powerful visual representations that transfer well to diverse tasks like image classification, object detection, and semantic segmentation.
Plain English Explanation
Video prediction models are a type of artificial intelligence (AI) system that can forecast what will happen in a video sequence. For example, if shown a few frames of a video, these models can predict what the next frames might look like.
The researchers behind this paper wanted to see if these video prediction models could do more than just predict the future. Could they also learn general-purpose visual representations that would be useful for all sorts of computer vision tasks, like recognizing objects in images, analyzing the contents of videos, or assessing video quality?
To find out, the researchers tested video prediction models on a wide variety of computer vision benchmarks. And the results were quite promising - the video prediction models were able to learn visual representations that transferred well to these other tasks, often matching or even outperforming models that were trained specifically for those tasks.
This suggests that video prediction could be a powerful way to build general-purpose visual AI systems that can handle many different computer vision challenges, without having to train separate models for each one. The representations learned by video prediction models seem to capture a lot of the fundamental visual information that's useful across many applications.
Technical Explanation
The core idea behind this research is to explore whether video prediction models can learn visual representations that are broadly applicable, beyond just the task of predicting future video frames.
The authors start by training several state-of-the-art video prediction models on large video datasets. These models learn to forecast the next few frames in a video sequence, given the past frames as input.
Next, the researchers evaluate the learned representations from these video prediction models on a diverse set of computer vision benchmarks, including image classification, object detection, and semantic segmentation. This is done by taking the pre-trained video prediction model, removing the video prediction head, and using the remaining encoder as a feature extractor for the downstream tasks.
Surprisingly, the authors find that the video prediction models are able to produce visual representations that perform on par with or even better than models that were trained specifically for those tasks. This indicates that the video prediction training process allows the models to learn general-purpose visual features that are widely applicable.
The authors explore several hypotheses for why video prediction might be an effective way to learn transferable visual representations. One key idea is that predicting future frames requires the model to build an understanding of the underlying 3D scene structure and object dynamics - information that turns out to be useful for many other vision tasks as well.
Overall, this work suggests that video prediction models could serve as a powerful alternative to traditional approaches for learning general-purpose visual encoders, with potential applications in areas like video augmentation and prediction or multi-task, multi-modal video understanding.
Critical Analysis
The authors acknowledge several limitations and areas for future work. First, while the video prediction models perform well on the evaluated benchmarks, there may be some computer vision tasks where they underperform models trained specifically for that task. Further research is needed to fully map the strengths and weaknesses of this approach.
Additionally, the paper only evaluates the video prediction models on standard computer vision datasets. It's unclear how well the learned representations would transfer to real-world applications with more diverse, unconstrained data. Exploring the robustness of these representations in the face of distribution shift would be an important next step.
Finally, the exact mechanisms by which video prediction leads to such effective visual representations are not yet fully understood. A deeper analysis of the learned features and their relationship to 3D scene understanding, object dynamics, and other key visual concepts could yield important insights.
Despite these caveats, this work represents a significant advance in our understanding of how to build general-purpose visual AI systems. The findings encourage further research into leveraging video prediction as a pathway to powerful, transferable visual encoders.
Conclusion
This paper demonstrates that video prediction models can learn visual representations that are highly effective for a wide range of computer vision tasks, often outperforming models trained specifically for those tasks.
The key insight is that the process of predicting future video frames seems to force the model to build a rich, general-purpose understanding of visual information that is broadly applicable. This suggests video prediction could be a promising alternative to traditional techniques for learning transferable visual encoders, with potential benefits for applications like video augmentation and prediction, multi-modal video understanding, and beyond.
While further research is needed to fully understand the strengths and limitations of this approach, this work represents an important step forward in our quest to develop general-purpose visual AI systems that can flexibly adapt to a wide range of real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Khan
0
0
Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.
6/14/2024

Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, Nicolas Ballas
0
0
This paper explores feature prediction as a stand-alone objective for unsupervised learning from video and introduces V-JEPA, a collection of vision models trained solely using a feature prediction objective, without the use of pretrained image encoders, text, negative examples, reconstruction, or other sources of supervision. The models are trained on 2 million videos collected from public datasets and are evaluated on downstream image and video tasks. Our results show that learning by predicting video features leads to versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model's parameters; e.g., using a frozen backbone. Our largest model, a ViT-H/16 trained only on videos, obtains 81.9% on Kinetics-400, 72.2% on Something-Something-v2, and 77.9% on ImageNet1K.
4/15/2024

CV-VAE: A Compatible Video VAE for Latent Generative Video Models
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, Ying Shan
0
0
Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
5/31/2024
VideoPrism: A Foundational Visual Encoder for Video Understanding
Long Zhao, Nitesh B. Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J. Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, Rachel Hornung, Florian Schroff, Ming-Hsuan Yang, David A. Ross, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko, Ting Liu, Boqing Gong
0
0
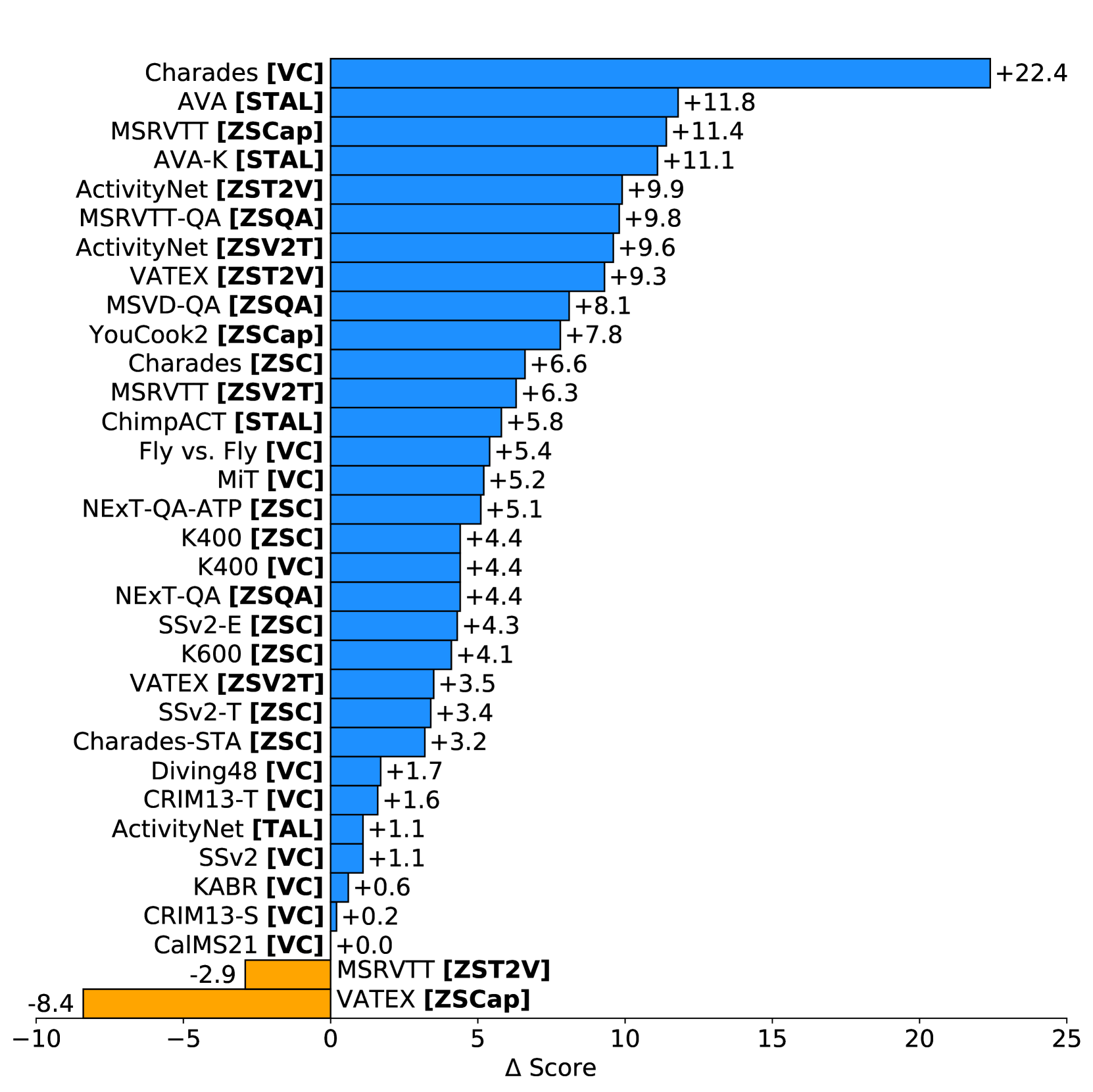
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 31 out of 33 video understanding benchmarks.
6/18/2024