CV-VAE: A Compatible Video VAE for Latent Generative Video Models
2405.20279
0
0

Abstract
Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
Create account to get full access
Overview
- This paper introduces CV-VAE, a compatible video variational autoencoder (VAE) for latent generative video models.
- CV-VAE aims to improve the performance and flexibility of existing video VAE architectures.
- The paper compares CV-VAE to previous video VAE models and demonstrates its capabilities on several video datasets.
Plain English Explanation
The researchers have developed a new type of video autoencoder called CV-VAE. An autoencoder is a machine learning model that can learn to compress and decompress data, like videos, in an efficient way.
CV-VAE is designed to work well with other generative video models, meaning it can be easily combined with other techniques to create more powerful video generation systems. Previous video autoencoder models had some limitations, so the researchers set out to create a more flexible and high-performing alternative.
The key idea behind CV-VAE is to make it "compatible" with other video models, so that it can be readily incorporated into more complex video generation pipelines. The researchers show that CV-VAE outperforms previous video autoencoder models on several standard video datasets, indicating it is a useful building block for more advanced video synthesis and manipulation systems.
Technical Explanation
The paper introduces the CV-VAE architecture, which builds on previous work in video prediction models and latent generative models.
Key elements of the CV-VAE model include:
- An encoder that maps input video frames to a latent representation
- A decoder that reconstructs the original video from the latent codes
- A compatibility objective that aligns the CV-VAE latent space with that of other video models
The researchers evaluate CV-VAE on several video datasets and compare its performance to prior video VAE approaches like LiteVAE and RVAE. They show that CV-VAE achieves better reconstruction quality and faster inference times.
Critical Analysis
The paper makes a strong case for the advantages of the CV-VAE architecture, but there are a few potential limitations worth considering:
- The compatibility objective introduces additional complexity and hyperparameters that need to be tuned, which could make CV-VAE more difficult to train and deploy than simpler VAE models.
- The evaluation is mainly focused on reconstruction quality and speed, but the paper does not deeply explore the implications of the compatible latent space for downstream video generation or manipulation tasks.
- There may be additional research needed to fully understand how the CV-VAE latent representation compares to those learned by other state-of-the-art video compression and latent diffusion models.
Conclusion
Overall, the CV-VAE model presented in this paper represents an interesting advance in the field of video VAEs. By emphasizing compatibility with other video models, the researchers have created a more flexible and high-performing autoencoder that could serve as a useful component in larger video generation and manipulation pipelines. While there are a few areas for potential future work, this research makes a valuable contribution to the ongoing efforts to develop powerful and versatile video modeling capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
LiteVAE: Lightweight and Efficient Variational Autoencoders for Latent Diffusion Models
Seyedmorteza Sadat, Jakob Buhmann, Derek Bradley, Otmar Hilliges, Romann M. Weber
0
0
Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored. In this paper, we introduce LiteVAE, a family of autoencoders for LDMs that leverage the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality. We also investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality. Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
5/24/2024
📶
S-HR-VQVAE: Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder for Video Prediction
Mohammad Adiban, Kalin Stefanov, Sabato Marco Siniscalchi, Giampiero Salvi
0
0
We address the video prediction task by putting forth a novel model that combines (i) our recently proposed hierarchical residual vector quantized variational autoencoder (HR-VQVAE), and (ii) a novel spatiotemporal PixelCNN (ST-PixelCNN). We refer to this approach as a sequential hierarchical residual learning vector quantized variational autoencoder (S-HR-VQVAE). By leveraging the intrinsic capabilities of HR-VQVAE at modeling still images with a parsimonious representation, combined with the ST-PixelCNN's ability at handling spatiotemporal information, S-HR-VQVAE can better deal with chief challenges in video prediction. These include learning spatiotemporal information, handling high dimensional data, combating blurry prediction, and implicit modeling of physical characteristics. Extensive experimental results on the KTH Human Action and Moving-MNIST tasks demonstrate that our model compares favorably against top video prediction techniques both in quantitative and qualitative evaluations despite a much smaller model size. Finally, we boost S-HR-VQVAE by proposing a novel training method to jointly estimate the HR-VQVAE and ST-PixelCNN parameters.
6/12/2024
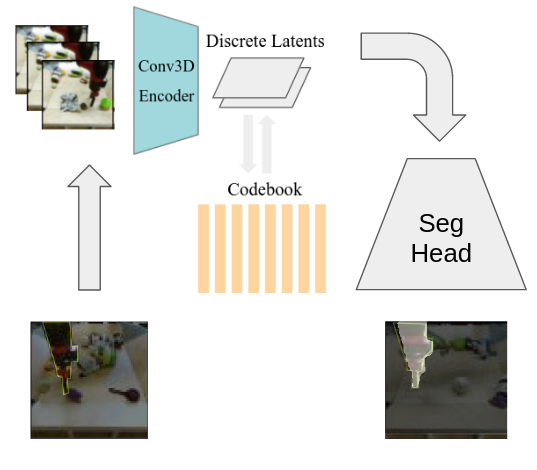
Video Prediction Models as General Visual Encoders
James Maier, Nishanth Mohankumar
0
0
This study explores the potential of open-source video conditional generation models as encoders for downstream tasks, focusing on instance segmentation using the BAIR Robot Pushing Dataset. The researchers propose using video prediction models as general visual encoders, leveraging their ability to capture critical spatial and temporal information which is essential for tasks such as instance segmentation. Inspired by human vision studies, particularly Gestalts principle of common fate, the approach aims to develop a latent space representative of motion from images to effectively discern foreground from background information. The researchers utilize a 3D Vector-Quantized Variational Autoencoder 3D VQVAE video generative encoder model conditioned on an input frame, coupled with downstream segmentation tasks. Experiments involve adapting pre-trained video generative models, analyzing their latent spaces, and training custom decoders for foreground-background segmentation. The findings demonstrate promising results in leveraging generative pretext learning for downstream tasks, working towards enhanced scene analysis and segmentation in computer vision applications.
5/28/2024
Towards Extreme Image Compression with Latent Feature Guidance and Diffusion Prior
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, Jingwen Jiang
0
0
Image compression at extremely low bitrates (below 0.1 bits per pixel (bpp)) is a significant challenge due to substantial information loss. In this work, we propose a novel two-stage extreme image compression framework that exploits the powerful generative capability of pre-trained diffusion models to achieve realistic image reconstruction at extremely low bitrates. In the first stage, we treat the latent representation of images in the diffusion space as guidance, employing a VAE-based compression approach to compress images and initially decode the compressed information into content variables. The second stage leverages pre-trained stable diffusion to reconstruct images under the guidance of content variables. Specifically, we introduce a small control module to inject content information while keeping the stable diffusion model fixed to maintain its generative capability. Furthermore, we design a space alignment loss to force the content variables to align with the diffusion space and provide the necessary constraints for optimization. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art approaches in terms of visual performance at extremely low bitrates.
6/14/2024