S^3D-NeRF: Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis

0

Sign in to get full access
Overview
- Efficient single-shot speech-driven 3D talking head synthesis
- Generates photorealistic talking heads from a single image and speech audio
- Uses a neural radiance field (NeRF) to model the 3D face geometry and appearance
Plain English Explanation
This paper presents a novel method called S3D-NeRF that can generate high-fidelity 3D talking heads from a single image and an accompanying speech audio clip. The key innovation is the use of a neural radiance field (NeRF), which is a powerful 3D representation that can capture the geometry and appearance of a face.
The process works as follows: a single input image of a person's face and a speech audio clip are fed into the S3D-NeRF model. The model then generates a 3D neural light dynamic field representation of the face that can be animated to match the input speech. This allows for the creation of high-fidelity 3D talking heads from a single image, without the need for complex 3D modeling or multiple images.
The key advantage of this approach is that it enables efficient 3D face transmission and synthesis from minimal input, making it suitable for applications like virtual avatars, video conferencing, and digital assistants.
Technical Explanation
The S3D-NeRF model consists of several key components:
- Audio Encoder: This module takes the input speech audio and extracts relevant features that capture the dynamics of the speech.
- Face NeRF: This is the core 3D representation of the face, which is conditioned on the audio features to generate the animated talking head.
- Rendering Module: This component uses the NeRF representation to render the final talking head video, including the mouth movements and facial expressions.
The training process involves optimizing the NeRF representation and the rendering module to faithfully reproduce the target talking head from the input image and speech. The authors leverage several techniques, such as progressive training and multi-view consistency, to improve the quality and stability of the generated results.
Critical Analysis
The S3D-NeRF method represents a significant advancement in the field of talking head synthesis, as it can generate high-fidelity 3D avatars from a single image and speech input. However, the paper does acknowledge some limitations:
- The method is currently limited to frontal-facing head poses and may struggle with more extreme head rotations or occlusions.
- The quality of the generated talking heads is still not on par with professional video recordings, and there is room for improvement in terms of realism and smoothness of the animations.
- The training process is computationally intensive and may not be suitable for real-time applications without further optimization.
Additionally, there are some potential ethical concerns around the use of such technology, particularly in the creation of synthetic media and the potential for misuse. The authors do not address these issues in the paper.
Conclusion
The S3D-NeRF method represents a significant step forward in the field of talking head synthesis, demonstrating the potential of neural radiance fields to enable efficient and high-fidelity 3D face animation from minimal input. While the current limitations and ethical concerns should be carefully considered, the proposed approach has promising applications in areas such as virtual avatars, video conferencing, and digital assistants, where the ability to generate realistic talking heads from limited data could be highly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
S^3D-NeRF: Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis
Dongze Li, Kang Zhao, Wei Wang, Yifeng Ma, Bo Peng, Yingya Zhang, Jing Dong
Talking head synthesis is a practical technique with wide applications. Current Neural Radiance Field (NeRF) based approaches have shown their superiority on driving one-shot talking heads with videos or signals regressed from audio. However, most of them failed to take the audio as driven information directly, unable to enjoy the flexibility and availability of speech. Since mapping audio signals to face deformation is non-trivial, we design a Single-Shot Speech-Driven Neural Radiance Field (S^3D-NeRF) method in this paper to tackle the following three difficulties: learning a representative appearance feature for each identity, modeling motion of different face regions with audio, and keeping the temporal consistency of the lip area. To this end, we introduce a Hierarchical Facial Appearance Encoder to learn multi-scale representations for catching the appearance of different speakers, and elaborate a Cross-modal Facial Deformation Field to perform speech animation according to the relationship between the audio signal and different face regions. Moreover, to enhance the temporal consistency of the important lip area, we introduce a lip-sync discriminator to penalize the out-of-sync audio-visual sequences. Extensive experiments have shown that our S^3D-NeRF surpasses previous arts on both video fidelity and audio-lip synchronization.
Read more8/20/2024
0
NeRFFaceSpeech: One-shot Audio-diven 3D Talking Head Synthesis via Generative Prior
Gihoon Kim, Kwanggyoon Seo, Sihun Cha, Junyong Noh
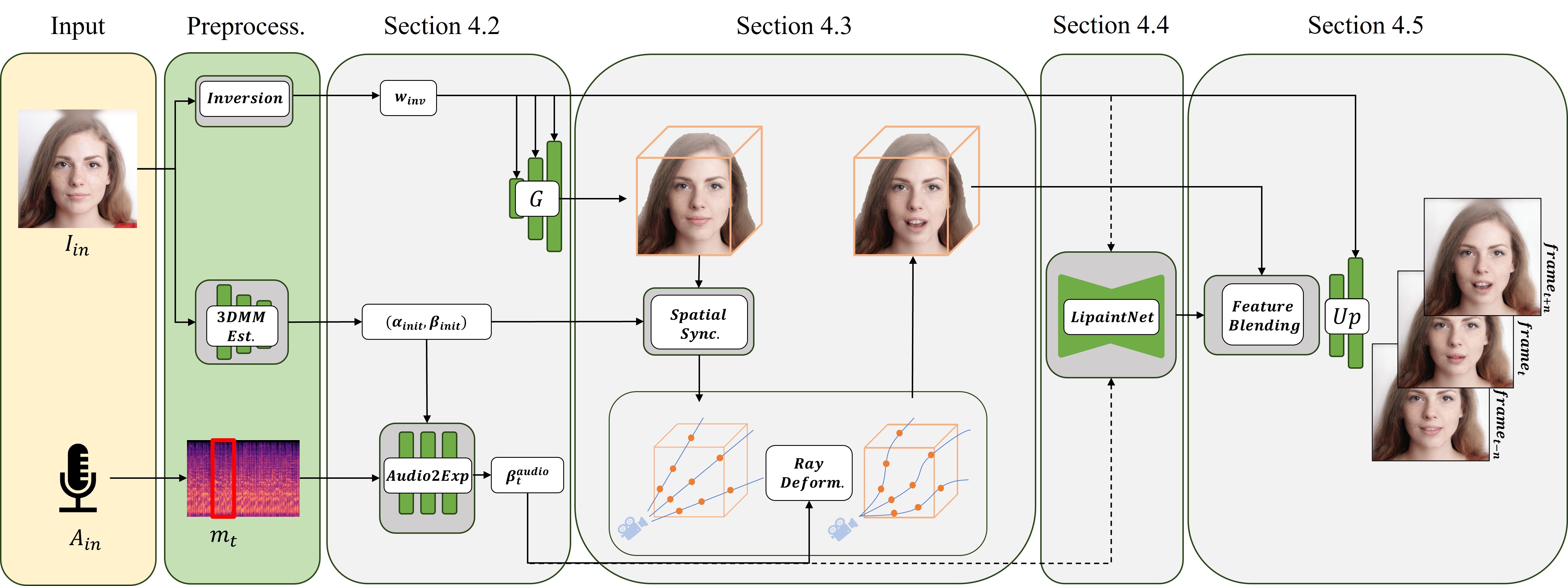
Audio-driven talking head generation is advancing from 2D to 3D content. Notably, Neural Radiance Field (NeRF) is in the spotlight as a means to synthesize high-quality 3D talking head outputs. Unfortunately, this NeRF-based approach typically requires a large number of paired audio-visual data for each identity, thereby limiting the scalability of the method. Although there have been attempts to generate audio-driven 3D talking head animations with a single image, the results are often unsatisfactory due to insufficient information on obscured regions in the image. In this paper, we mainly focus on addressing the overlooked aspect of 3D consistency in the one-shot, audio-driven domain, where facial animations are synthesized primarily in front-facing perspectives. We propose a novel method, NeRFFaceSpeech, which enables to produce high-quality 3D-aware talking head. Using prior knowledge of generative models combined with NeRF, our method can craft a 3D-consistent facial feature space corresponding to a single image. Our spatial synchronization method employs audio-correlated vertex dynamics of a parametric face model to transform static image features into dynamic visuals through ray deformation, ensuring realistic 3D facial motion. Moreover, we introduce LipaintNet that can replenish the lacking information in the inner-mouth area, which can not be obtained from a given single image. The network is trained in a self-supervised manner by utilizing the generative capabilities without additional data. The comprehensive experiments demonstrate the superiority of our method in generating audio-driven talking heads from a single image with enhanced 3D consistency compared to previous approaches. In addition, we introduce a quantitative way of measuring the robustness of a model against pose changes for the first time, which has been possible only qualitatively.
Read more5/13/2024
🧠
0
NLDF: Neural Light Dynamic Fields for Efficient 3D Talking Head Generation
Niu Guanchen
Talking head generation based on the neural radiation fields model has shown promising visual effects. However, the slow rendering speed of NeRF seriously limits its application, due to the burdensome calculation process over hundreds of sampled points to synthesize one pixel. In this work, a novel Neural Light Dynamic Fields model is proposed aiming to achieve generating high quality 3D talking face with significant speedup. The NLDF represents light fields based on light segments, and a deep network is used to learn the entire light beam's information at once. In learning the knowledge distillation is applied and the NeRF based synthesized result is used to guide the correct coloration of light segments in NLDF. Furthermore, a novel active pool training strategy is proposed to focus on high frequency movements, particularly on the speaker mouth and eyebrows. The propose method effectively represents the facial light dynamics in 3D talking video generation, and it achieves approximately 30 times faster speed compared to state of the art NeRF based method, with comparable generation visual quality.
Read more6/18/2024

0
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
Read more8/12/2024