Semantic Communications for 3D Human Face Transmission with Neural Radiance Fields

0

Sign in to get full access
Overview
- This paper presents a new approach for semantic communications in 3D human face transmission using neural radiance fields (NeRF).
- The key ideas involve leveraging a knowledge base and NeRF to enable efficient encoding and decoding of 3D facial information.
- The proposed system aims to transmit 3D facial data with high fidelity while minimizing bandwidth requirements.
Plain English Explanation
The paper describes a new way to transmit 3D models of human faces over digital networks. Traditional methods of sending 3D data can require a lot of bandwidth, making them impractical for many applications.
The researchers propose using a knowledge base and a neural radiance field (NeRF) to encode the 3D facial information more efficiently. A knowledge base is a database of structured information, while a NeRF is a type of machine learning model that can represent 3D scenes.
By combining these techniques, the system can transmit 3D facial data using less bandwidth than previous methods, while still preserving a high level of detail and realism. This could enable new applications like high-quality video calls or remote collaboration with 3D avatars.
Technical Explanation
The paper introduces a semantic communications framework for 3D human face transmission using neural radiance fields (NeRF).
The key components are:
-
Knowledge Base: The researchers build a knowledge base containing detailed information about human facial features, expressions, and other relevant data. This provides a shared understanding between the encoder and decoder.
-
NeRF Encoder/Decoder: The 3D facial data is encoded using a NeRF model, which can compactly represent the appearance and geometry of the face. The encoder converts the 3D face into the NeRF representation, which is then transmitted. The decoder at the receiver end uses the NeRF to reconstruct the 3D face.
-
Semantic Encoding: By leveraging the knowledge base, the system can transmit the 3D facial data more efficiently. Only the high-level semantic information needed to reconstruct the face is sent, rather than the full 3D geometry.
The paper evaluates the proposed approach through experiments, demonstrating that it can achieve high-fidelity 3D face reconstruction at lower bandwidth compared to traditional 3D transmission methods.
Critical Analysis
The paper presents a novel and promising approach for efficient 3D facial data transmission. However, there are a few notable limitations and areas for further research:
-
Knowledge Base Dependence: The system relies heavily on the completeness and accuracy of the underlying knowledge base. If the knowledge base is incomplete or biased, it could lead to errors in the reconstructed 3D faces.
-
Generalization Capability: The paper focuses on a specific dataset of human faces. It's unclear how well the approach would generalize to more diverse 3D content, such as different types of objects or scenes.
-
Real-Time Performance: While the system reduces bandwidth requirements, the computational complexity of the NeRF model and knowledge base lookup may impact real-time performance, especially for applications like video conferencing.
-
Privacy and Security: Transmitting 3D facial data raises potential privacy and security concerns that should be carefully considered, especially if the knowledge base contains sensitive personal information.
Further research could explore ways to address these limitations, such as developing more robust and generalizable knowledge bases, improving the efficiency of the NeRF encoding/decoding, and incorporating privacy-preserving techniques.
Conclusion
This paper presents an innovative approach to 3D human face transmission that leverages semantic communications and neural radiance fields. By combining a knowledge base with NeRF-based encoding, the system can transmit high-fidelity 3D facial data at lower bandwidth compared to traditional methods.
While the approach has some limitations, it represents an important step towards more efficient and practical 3D content delivery, with potential applications in areas like telepresence, virtual avatars, and remote collaboration. As the field of 3D semantic communications continues to evolve, this research contributes valuable insights and techniques that may inspire further advancements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantic Communications for 3D Human Face Transmission with Neural Radiance Fields
Guanlin Wu, Zhonghao Lyu, Juyong Zhang, Jie Xu
This paper investigates the transmission of three-dimensional (3D) human face content for immersive communication over a rate-constrained transmitter-receiver link. We propose a new framework named NeRF-SeCom, which leverages neural radiance fields (NeRF) and semantic communications to improve the quality of 3D visualizations while minimizing the communication overhead. In the NeRF-SeCom framework, we first train a NeRF face model based on the NeRFBlendShape method, which is pre-shared between the transmitter and receiver as the semantic knowledge base to facilitate the real-time transmission. Next, with knowledge base, the transmitter extracts and sends only the essential semantic features for the receiver to reconstruct 3D face in real time. To optimize the transmission efficiency, we classify the expression features into static and dynamic types. Over each video chunk, static features are transmitted once for all frames, whereas dynamic features are transmitted over a portion of frames to adhere to rate constraints. Additionally, we propose a feature prediction mechanism, which allows the receiver to predict the dynamic features for frames that are not transmitted. Experiments show that our proposed NeRF-SeCom framework significantly outperforms benchmark methods in delivering high-quality 3D visualizations of human faces.
Read more7/22/2024

0
S^3D-NeRF: Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis
Dongze Li, Kang Zhao, Wei Wang, Yifeng Ma, Bo Peng, Yingya Zhang, Jing Dong
Talking head synthesis is a practical technique with wide applications. Current Neural Radiance Field (NeRF) based approaches have shown their superiority on driving one-shot talking heads with videos or signals regressed from audio. However, most of them failed to take the audio as driven information directly, unable to enjoy the flexibility and availability of speech. Since mapping audio signals to face deformation is non-trivial, we design a Single-Shot Speech-Driven Neural Radiance Field (S^3D-NeRF) method in this paper to tackle the following three difficulties: learning a representative appearance feature for each identity, modeling motion of different face regions with audio, and keeping the temporal consistency of the lip area. To this end, we introduce a Hierarchical Facial Appearance Encoder to learn multi-scale representations for catching the appearance of different speakers, and elaborate a Cross-modal Facial Deformation Field to perform speech animation according to the relationship between the audio signal and different face regions. Moreover, to enhance the temporal consistency of the important lip area, we introduce a lip-sync discriminator to penalize the out-of-sync audio-visual sequences. Extensive experiments have shown that our S^3D-NeRF surpasses previous arts on both video fidelity and audio-lip synchronization.
Read more8/20/2024
0
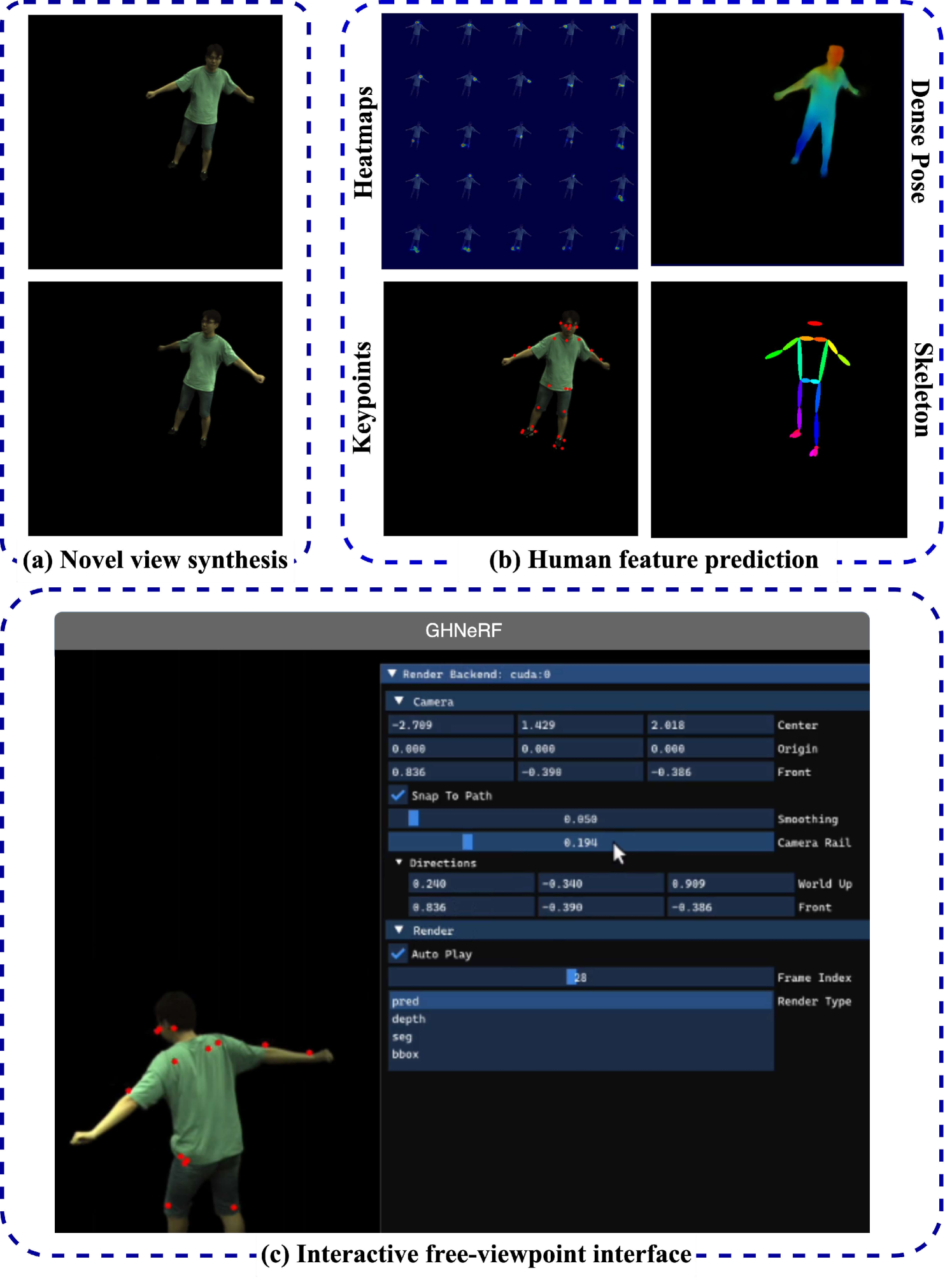
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Arnab Dey, Di Yang, Rohith Agaram, Antitza Dantcheva, Andrew I. Comport, Srinath Sridhar, Jean Martinet
Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.
Read more4/10/2024

0
Rethinking Open-Vocabulary Segmentation of Radiance Fields in 3D Space
Hyunjee Lee, Youngsik Yun, Jeongmin Bae, Seoha Kim, Youngjung Uh
Understanding the 3D semantics of a scene is a fundamental problem for various scenarios such as embodied agents. While NeRFs and 3DGS excel at novel-view synthesis, previous methods for understanding their semantics have been limited to incomplete 3D understanding: their segmentation results are 2D masks and their supervision is anchored at 2D pixels. This paper revisits the problem set to pursue a better 3D understanding of a scene modeled by NeRFs and 3DGS as follows. 1) We directly supervise the 3D points to train the language embedding field. It achieves state-of-the-art accuracy without relying on multi-scale language embeddings. 2) We transfer the pre-trained language field to 3DGS, achieving the first real-time rendering speed without sacrificing training time or accuracy. 3) We introduce a 3D querying and evaluation protocol for assessing the reconstructed geometry and semantics together. Code, checkpoints, and annotations will be available online. Project page: https://hyunji12.github.io/Open3DRF
Read more8/20/2024