SA-DVAE: Improving Zero-Shot Skeleton-Based Action Recognition by Disentangled Variational Autoencoders

0

Sign in to get full access
Overview
- This paper introduces SA-DVAE, a method for improving zero-shot skeleton-based action recognition using disentangled variational autoencoders (DVAEs).
- Zero-shot learning is the ability to recognize actions that were not seen during training, which is an important challenge in action recognition.
- The key ideas are to learn disentangled representations of action features and to leverage side information to enable zero-shot generalization.
Plain English Explanation
The paper proposes a new method called SA-DVAE to address the problem of zero-shot skeleton-based action recognition. Zero-shot learning is the ability to recognize actions that the model has never seen before during training. This is an important but challenging task in action recognition.
The core idea behind SA-DVAE is to learn disentangled representations of the different factors that make up an action, such as the body pose, motion patterns, and action semantics. By separating these factors, the model can better generalize to new actions that it hasn't seen before.
The method also leverages side information, such as text descriptions of the actions, to further improve the zero-shot recognition performance. This side information helps the model understand the relationship between different actions, even if it hasn't directly observed them.
Overall, the key contributions of this work are:
- Learning disentangled representations for skeleton-based action recognition
- Incorporating side information to enable zero-shot generalization
- Demonstrating improved zero-shot and generalized zero-shot learning performance on benchmark datasets
Technical Explanation
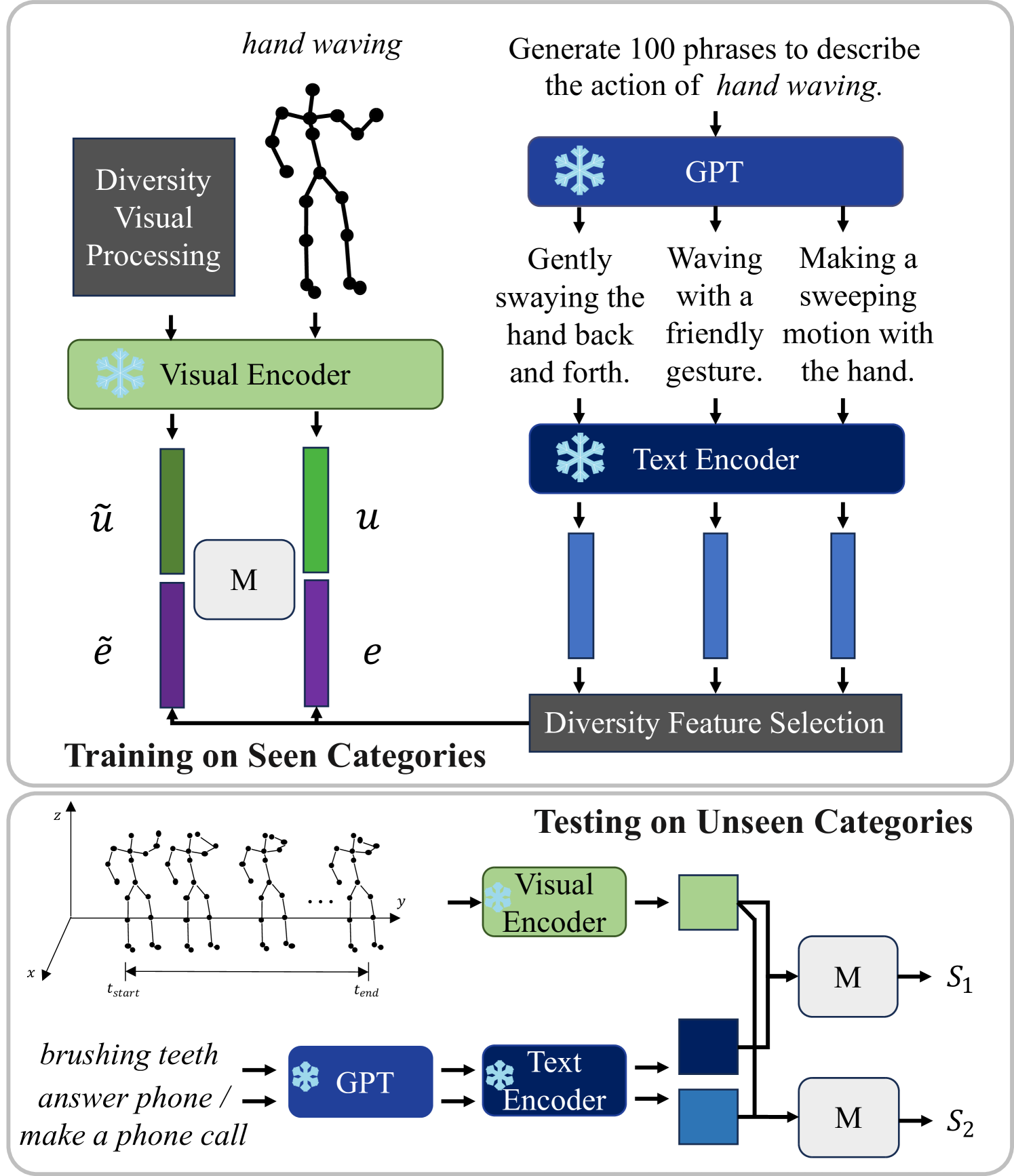
The SA-DVAE model uses a disentangled variational autoencoder (DVAE) architecture to learn distinct latent representations for different aspects of the action, such as the body pose, motion patterns, and action semantics.
The encoder network takes in the input skeleton sequence and produces three separate latent codes: a pose code, a motion code, and a semantic code. The decoder then reconstructs the original skeleton sequence from these disentangled representations.
To enable zero-shot learning, the model also takes in side information about the actions, such as text descriptions. This side information is used to learn a mapping between the disentangled latent codes and the action labels, allowing the model to recognize new actions that it hasn't directly observed.
The authors evaluate SA-DVAE on standard zero-shot and generalized zero-shot skeleton-based action recognition benchmarks, demonstrating state-of-the-art performance. They also conduct ablation studies to analyze the contribution of the disentangled representations and side information.
Critical Analysis
The paper makes a convincing case for the benefits of using disentangled representations and side information to improve zero-shot action recognition. The experimental results show clear performance gains over prior methods on relevant benchmarks.
However, one potential limitation is the reliance on text descriptions as the sole form of side information. It would be interesting to explore incorporating additional modalities, such as vision-language models or self-supervised 3D action representations, to further enhance the zero-shot capabilities.
Additionally, the paper does not deeply investigate the interpretability and robustness of the disentangled representations learned by SA-DVAE. Adapters for deformable spatio-temporal representations could be a relevant area to explore in this context.
Overall, this is a well-executed piece of research that makes a valuable contribution to the field of zero-shot action recognition. The disentanglement and side information approaches warrant further exploration and could lead to significant advancements in this important area of computer vision.
Conclusion
The SA-DVAE method presented in this paper represents an effective approach for improving zero-shot and generalized zero-shot skeleton-based action recognition. By learning disentangled representations of different action factors and leveraging side information, the model can significantly outperform previous state-of-the-art methods on benchmark datasets.
This work highlights the importance of representation learning and the effective use of auxiliary information for tackling challenging zero-shot learning problems. The insights gained from this research could have broader implications for other domains beyond action recognition, such as zero-shot classification and fine-grained visual recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SA-DVAE: Improving Zero-Shot Skeleton-Based Action Recognition by Disentangled Variational Autoencoders
Sheng-Wei Li, Zi-Xiang Wei, Wei-Jie Chen, Yi-Hsin Yu, Chih-Yuan Yang, Jane Yung-jen Hsu
Existing zero-shot skeleton-based action recognition methods utilize projection networks to learn a shared latent space of skeleton features and semantic embeddings. The inherent imbalance in action recognition datasets, characterized by variable skeleton sequences yet constant class labels, presents significant challenges for alignment. To address the imbalance, we propose SA-DVAE -- Semantic Alignment via Disentangled Variational Autoencoders, a method that first adopts feature disentanglement to separate skeleton features into two independent parts -- one is semantic-related and another is irrelevant -- to better align skeleton and semantic features. We implement this idea via a pair of modality-specific variational autoencoders coupled with a total correction penalty. We conduct experiments on three benchmark datasets: NTU RGB+D, NTU RGB+D 120 and PKU-MMD, and our experimental results show that SA-DAVE produces improved performance over existing methods. The code is available at https://github.com/pha123661/SA-DVAE.
Read more7/19/2024
0
An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Haojun Xu, Yan Gao, Jie Li, Xinbo Gao
Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
Read more6/4/2024

0
Fine-Grained Side Information Guided Dual-Prompts for Zero-Shot Skeleton Action Recognition
Yang Chen, Jingcai Guo, Tian He, Ling Wang
Skeleton-based zero-shot action recognition aims to recognize unknown human actions based on the learned priors of the known skeleton-based actions and a semantic descriptor space shared by both known and unknown categories. However, previous works focus on establishing the bridges between the known skeleton representation space and semantic descriptions space at the coarse-grained level for recognizing unknown action categories, ignoring the fine-grained alignment of these two spaces, resulting in suboptimal performance in distinguishing high-similarity action categories. To address these challenges, we propose a novel method via Side information and dual-prompts learning for skeleton-based zero-shot action recognition (STAR) at the fine-grained level. Specifically, 1) we decompose the skeleton into several parts based on its topology structure and introduce the side information concerning multi-part descriptions of human body movements for alignment between the skeleton and the semantic space at the fine-grained level; 2) we design the visual-attribute and semantic-part prompts to improve the intra-class compactness within the skeleton space and inter-class separability within the semantic space, respectively, to distinguish the high-similarity actions. Extensive experiments show that our method achieves state-of-the-art performance in ZSL and GZSL settings on NTU RGB+D, NTU RGB+D 120, and PKU-MMD datasets.
Read more4/16/2024

0
Vision-Language Meets the Skeleton: Progressively Distillation with Cross-Modal Knowledge for 3D Action Representation Learning
Yang Chen, Tian He, Junfeng Fu, Ling Wang, Jingcai Guo, Ting Hu, Hong Cheng
Skeleton-based action representation learning aims to interpret and understand human behaviors by encoding the skeleton sequences, which can be categorized into two primary training paradigms: supervised learning and self-supervised learning. However, the former one-hot classification requires labor-intensive predefined action categories annotations, while the latter involves skeleton transformations (e.g., cropping) in the pretext tasks that may impair the skeleton structure. To address these challenges, we introduce a novel skeleton-based training framework (C$^2$VL) based on Cross-modal Contrastive learning that uses the progressive distillation to learn task-agnostic human skeleton action representation from the Vision-Language knowledge prompts. Specifically, we establish the vision-language action concept space through vision-language knowledge prompts generated by pre-trained large multimodal models (LMMs), which enrich the fine-grained details that the skeleton action space lacks. Moreover, we propose the intra-modal self-similarity and inter-modal cross-consistency softened targets in the cross-modal representation learning process to progressively control and guide the degree of pulling vision-language knowledge prompts and corresponding skeletons closer. These soft instance discrimination and self-knowledge distillation strategies contribute to the learning of better skeleton-based action representations from the noisy skeleton-vision-language pairs. During the inference phase, our method requires only the skeleton data as the input for action recognition and no longer for vision-language prompts. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets demonstrate that our method outperforms the previous methods and achieves state-of-the-art results. Code is available at: https://github.com/cseeyangchen/C2VL.
Read more9/17/2024