Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
2405.16390
0
0
Abstract
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
Create account to get full access
Overview
- This paper presents a framework for constrained multi-objective reinforcement learning (MORL) that aims to balance reward maximization with safety constraints.
- The proposed approach, called "Safe and Balanced" (SaB), introduces objective suppression techniques to handle safety constraints while maintaining performance on the primary objective.
- The framework is designed to be applicable to a wide range of MORL problems, with the ability to handle both hard and soft constraints.
Plain English Explanation
The paper describes a new method for reinforcement learning (RL) agents to handle multiple goals at the same time while also ensuring safety. In typical RL, an agent tries to maximize a single reward signal, but in many real-world problems, there are multiple objectives that need to be balanced, such as maximizing performance while also avoiding dangerous or undesirable actions.
The Safe and Balanced (SaB) framework proposed in this paper aims to solve this challenge. It uses "objective suppression" techniques to handle safety constraints while still allowing the agent to perform well on its primary objective. This means the agent will try to avoid violating the safety constraints, but it won't completely ignore the main goal it's trying to achieve.
The framework is designed to be flexible and applicable to a wide range of multi-objective reinforcement learning (MORL) problems, where the agent has to juggle multiple, potentially conflicting goals. It can handle both hard constraints (which must never be violated) and soft constraints (which should be avoided but can be broken if necessary).
Technical Explanation
The SaB framework introduces a new constrained MORL formulation that combines reward maximization with constraint satisfaction. It does this by defining a "safe and balanced" objective function that combines the original reward signal with a suppressed version of the constraint violations.
This suppression mechanism allows the agent to prioritize the primary objective while still considering the safety constraints, rather than simply treating them as hard limits. The authors show that this approach can outperform existing constrained MORL methods in terms of balancing performance and safety.
The paper also presents a survey of different constraint formulations used in safe reinforcement learning, and discusses how the SaB framework relates to and builds upon this prior work. Additionally, the authors provide a theoretical analysis of the trade-offs between reward maximization and constraint satisfaction in the SaB approach.
The proposed method is evaluated on several benchmark multi-objective and constrained reinforcement learning tasks, demonstrating its effectiveness at finding a balance between performance and safety.
Critical Analysis
The SaB framework represents an important step forward in the field of constrained multi-objective reinforcement learning, addressing a key challenge in real-world applications where agents need to juggle multiple, potentially conflicting goals.
One potential limitation of the approach is that the specific trade-off between reward maximization and constraint satisfaction is controlled by a hyperparameter, which may require careful tuning for different problem domains. Additionally, the paper does not provide a comprehensive analysis of the computational complexity or scalability of the SaB algorithm, which could be an important consideration for deploying the method in large-scale or time-sensitive applications.
That said, the authors do a thorough job of situating their work within the broader context of safe reinforcement learning research, and the evaluation on benchmark tasks suggests the SaB framework is a promising direction for further exploration and refinement.
Conclusion
The "Safe and Balanced" framework presented in this paper offers a novel approach to constrained multi-objective reinforcement learning, aiming to balance the maximization of a primary reward signal with the satisfaction of safety constraints. By introducing objective suppression techniques, the method allows agents to prioritize the main objective while still considering the safety requirements, rather than treating them as hard limits.
This flexibility and balance between performance and safety could make the SaB framework a valuable tool for a wide range of real-world applications, from autonomous systems to decision-making algorithms, where multiple, potentially competing objectives need to be optimized under various constraints. As the field of safe and ethical AI continues to evolve, approaches like SaB that can navigate these complex trade-offs will become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
Multi-Constraint Safe RL with Objective Suppression for Safety-Critical Applications
Zihan Zhou, Jonathan Booher, Khashayar Rohanimanesh, Wei Liu, Aleksandr Petiushko, Animesh Garg
0
0
Safe reinforcement learning tasks with multiple constraints are a challenging domain despite being very common in the real world. In safety-critical domains, properly handling the constraints becomes even more important. To address this challenge, we first describe the multi-constraint problem with a stronger Uniformly Constrained MDP (UCMDP) model; we then propose Objective Suppression, a novel method that adaptively suppresses the task reward maximizing objectives according to a safety critic, as a solution to the Lagrangian dual of a UCMDP. We benchmark Objective Suppression in two multi-constraint safety domains, including an autonomous driving domain where any incorrect behavior can lead to disastrous consequences. Empirically, we demonstrate that our proposed method, when combined with existing safe RL algorithms, can match the task reward achieved by our baselines with significantly fewer constraint violations.
4/17/2024
🏅
A Survey of Constraint Formulations in Safe Reinforcement Learning
Akifumi Wachi, Xun Shen, Yanan Sui
0
0
Safety is critical when applying reinforcement learning (RL) to real-world problems. As a result, safe RL has emerged as a fundamental and powerful paradigm for optimizing an agent's policy while incorporating notions of safety. A prevalent safe RL approach is based on a constrained criterion, which seeks to maximize the expected cumulative reward subject to specific safety constraints. Despite recent effort to enhance safety in RL, a systematic understanding of the field remains difficult. This challenge stems from the diversity of constraint representations and little exploration of their interrelations. To bridge this knowledge gap, we present a comprehensive review of representative constraint formulations, along with a curated selection of algorithms designed specifically for each formulation. In addition, we elucidate the theoretical underpinnings that reveal the mathematical mutual relations among common problem formulations. We conclude with a discussion of the current state and future directions of safe reinforcement learning research.
5/9/2024

Balance Reward and Safety Optimization for Safe Reinforcement Learning: A Perspective of Gradient Manipulation
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Ming Jin, Alois Knoll
0
0
Ensuring the safety of Reinforcement Learning (RL) is crucial for its deployment in real-world applications. Nevertheless, managing the trade-off between reward and safety during exploration presents a significant challenge. Improving reward performance through policy adjustments may adversely affect safety performance. In this study, we aim to address this conflicting relation by leveraging the theory of gradient manipulation. Initially, we analyze the conflict between reward and safety gradients. Subsequently, we tackle the balance between reward and safety optimization by proposing a soft switching policy optimization method, for which we provide convergence analysis. Based on our theoretical examination, we provide a safe RL framework to overcome the aforementioned challenge, and we develop a Safety-MuJoCo Benchmark to assess the performance of safe RL algorithms. Finally, we evaluate the effectiveness of our method on the Safety-MuJoCo Benchmark and a popular safe RL benchmark, Omnisafe. Experimental results demonstrate that our algorithms outperform several state-of-the-art baselines in terms of balancing reward and safety optimization.
6/10/2024
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
0
0
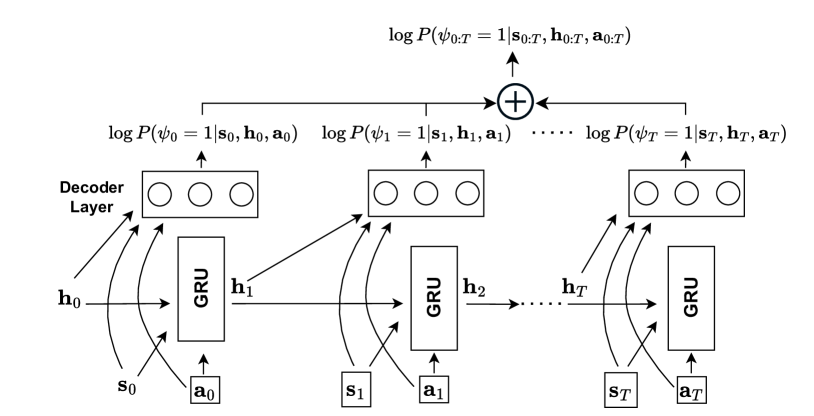
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
5/7/2024